

وقتی نقشه ندارید، اما باید تصمیم درست بگیرید؛ بازتعریف ناوبری صنعتی با هوش تقویتی و مهندسی پاداش
در زیستبوم صنعت ۴.۰، جایی که تولید، لجستیک و مدیریت مواد هر لحظه تحت تأثیر نوسانات تقاضا، تغییرات طراحی و بهروزرسانی سریع فرآیندهاست، یک سؤال اساسی مطرح است: چگونه میتوان ناوبری رباتهای خودکار را در دل این بیثباتی طراحی کرد؟
تا امروز، پاسخ اغلب سازمانها استفاده از نقشههای ازپیشساخته، سیستمهای SLAM، یا مسیرهای نشانهگذاریشدهی مبتنی بر AGV بوده است؛ اما تجربه عملیاتی نشان داده این روشها در برابر پویایی محیط صنعتی شکست میخورند.
بهعبارت دقیقتر، هر بار که چیدمان خط تولید تغییر میکند، یا یک اپراتور ابزار سنگینی را در مسیر حرکت ربات قرار میدهد، کل سامانه دچار اختلال میشود؛ چرا که این رباتها نمیتوانند “در لحظه” تصمیم بگیرند.
اینجاست که مفهوم ناوبری بدون نقشه (Map-Free Navigation) وارد میشود. برخلاف AGVهای سنتی که روی مسیر ثابت و شرایط ایستا تعریف میشوند، یک سیستم ناوبری بدون نقشه باید بتواند:
بدون داشتن نقشه کامل از محیط، با دادههای خامی مثل لیزر یا موقعیت نسبی، مسیر را تحلیل کند؛
موانع را بدون وابستگی به نقشه یا سنسورهای خاص، شناسایی و دور بزند؛
و مهمتر از همه، در هر لحظه بهترین تصمیم را بگیرد، حتی اگر محیط بارها تغییر کند.
اما چالش اصلی اینجاست: در چنین محیطهایی، سیگنال پاداش یادگیری بسیار ضعیف و پراکنده است؛ یعنی ربات نمیداند که کدام رفتار درست است، مگر زمانی که خیلی دیر شده — مثلاً وقتی برخورد کرده یا به هدف رسیده. اینجاست که مقاله حاضر، با ارائهی یک معماری جدید بهنام Heuristic Dense Reward Shaping (HDRS)، این بنبست را میشکند.
HDRS، با الهام از مفاهیم فیزیکی مانند میدانهای پتانسیل، مدل یادگیری تقویتی را با پاداشسازی هوشمند و پیوسته غنی میکند. برخلاف مدلهای پاداشمحور ساده که فقط برای رسیدن یا نرسیدن پاداش میدهند، HDRS در هر لحظه، با درک موقعیت، زاویه، فاصله از هدف و موانع، سیگنال پاداشی مهندسیشده به ربات میدهد. این یعنی ربات میآموزد نهفقط به هدف برسد، بلکه به بهترین شکل ممکن به هدف برسد. از نگاه صنعتی، مزایای این معماری در سه بُعد استراتژیک قابلدرک است:
انعطافپذیری: بینیاز از نقشه، نصب مارکر یا زیرساخت پیچیده
سرعت در یادگیری: همگرایی بسیار سریعتر نسبت به الگوریتمهای کلاسیک
انتقالپذیری به دنیای واقعی (Sim-to-Real): با افزودن نویز کنترلشده، مدل بدون نیاز به روتیونینگ قابل استقرار روی AMRهای واقعی است.
و درست همینجاست که HDRS نه بهعنوان یک الگوریتم دانشگاهی، بلکه بهعنوان یک فناوری صنعتی آمادهی پیادهسازی در کف کارخانه مطرح میشود؛ راهکاری برای آندسته از مدیران لجستیک، اتوماسیون یا بهرهبرداری که بهدنبال ناوبری منعطف، بدون دردسر، و سازگار با تغییرات محیطی هستند.
فرصتها و چالشهای فنی–صنعتی در ناوبری رباتهای خودمختار بدون نقشه
در نگاه اول، ایدهی ناوبری ربات بدون نقشه میتواند مفهومی آزمایشگاهی یا دانشگاهی بهنظر برسد. اما در واقعیت صنعتی امروز، دقیقاً همین مدل اسخ اجتنابناپذیر صنعت به یک بحران عملیاتی در حال رشد است عدم تطابق فناوریهای ناوبری کلاسیک با محیطهای واقعی، پویا و نامطمئن. بگذارید دقیقتر بررسی کنیم:
چالش ۱: ناپایداری محیط صنعتی؛ جایی برای نقشهها نیست
محیطهای صنعتی مدرن، بهویژه در صنایع متوسط و بزرگ، با یک ویژگی مشترک مشخص میشوند: نظمناپذیری عملیاتی. چه در یک انبار متحرک، چه در کف تولید، چیدمان ماشینآلات، خطوط بستهبندی، پالتها و حتی مسیرهای عبوری، در بازههای زمانی کوتاهمدت تغییر میکنند.
در چنین فضایی، استفاده از نقشههای ازپیشتعریفشده یا مسیرهای مبتنی بر SLAM، عملاً ناکارآمد میشود. نقشههایی که دیروز دقیق بودند، امروز منسوخاند.
✅ HDRS، در چنین بستری معنا پیدا میکند. این الگوریتم نهتنها بدون نقشه کار میکند، بلکه با پردازش دادههای زنده از محیط، توانایی تفسیر و تطبیق تصمیمگیری در لحظه را برای AMR فراهم میکند — بدون وابستگی به زیرساخت فیزیکی یا تغییرات سختافزاری.
چالش ۲: سکوت محیط؛ یادگیری بدون بازخورد کار نمیکند
یکی از جدیترین موانع یادگیری تقویتی در محیطهای صنعتی، فقدان سیگنالهای آموزشی کافی در طول مسیر حرکت است.
اگر ربات تنها هنگام رسیدن به هدف یا در زمان برخورد بازخورد بگیرد، مسیر یادگیری تبدیل به یک تونل تاریک خواهد شد: پرهزینه، کند، و مستعد تصمیمگیریهای اشتباه.
✅ HDRS، با مهندسی پاداشهای متراکم (Dense Reward)، این سکوت را میشکند.
الگوریتم در هر لحظه از حرکت، با توجه به دادههای فاصله، زاویه، موقعیت مانع، و تغییرات حرکتی، پاداشی پیوسته و هوشمند تعریف میکند که هم ایمنی را افزایش میدهد و هم رفتار مطلوب را تشویق میکند.
چالش ۳: شکاف شبیهسازی تا واقعیت؛ الگوریتمهایی که در دنیای واقعی شکست میخورند
الگوریتمهایی که در محیط Gazebo یا Webots موفق عمل میکنند، اغلب در محیط واقعی عملکرد مناسبی ندارند. چرا؟
چون دنیای واقعی پر از نویز، انحرافات سنسوری، خطاهای مکانیابی، و دادههای ناقص است. این همان چیزیست که به آن Sim-to-Real Gap گفته میشود — شکاف بین “یادگیری در آزمایشگاه” و “اجرا در کارخانه”.
✅ HDRS، برای این مسئله پاسخ عملیاتی دارد:
در حین آموزش، با افزودن نویزهای کنترلشده به دادهها (مثل نویز مکان، خطای LiDAR، تأخیر سنسور)، مدل را از ابتدا برای زندگی در دنیای واقعی آماده میکند. نتیجه؟
AMRهای آموزشدیده با HDRS، بدون نیاز به تنظیم مجدد، میتوانند بهراحتی روی ربات فیزیکی اجرا شوند.
چالش ۴: محدودیت منابع سختافزاری در ربات صنعتی
خیلی از الگوریتمهای پیشرفته، مثل SAC یا TD3، نیازمند کارتهای گرافیک قدرتمند یا پردازندههای چندهستهای هستند. این در تضاد با واقعیت سختافزارهای صنعتی است — که باید سبک، کممصرف و Real-Time باشند.
✅ HDRS، با استفاده از DDPG و ساختار MLP ساده، روی رباتهایی با منابع پردازشی محدود هم اجرا میشود.
الگوریتم با فرکانس بالای تصمیمگیری (تا 488 هرتز) و بدون نیاز به شبکههای سنگین، هم در زمان و هم در منابع، بهینه عمل میکند.
چالش ۵: بنبستهای محلی؛ تلههایی که رباتها در آن گیر میافتند
در مسیرهای پیچیده، راهروهای تنگ، یا موانع U شکل، الگوریتمهای مبتنی بر پاداشهای ساده یا میدانهای پتانسیل کلاسیک، دچار بنبست یا حرکت نوسانی میشوند.
✅ HDRS، برخلاف APF، نه تصمیم را مستقیم از نیروها میگیرد، بلکه از پاداشهایی استفاده میکند که رفتار مطلوب را به مدل یاد میدهند.
این یعنی حتی اگر ربات نیاز به تغییر مسیر موقت داشته باشد، باز هم از طریق «درک» محیط و نه صرفاً «فرمول»، به هدف میرسد.
رویکرد علمی مقاله و نقطه تمایز آن نسبت به مدلهای رایج
اگر بخواهیم جایگاه این مقاله را از منظر پیشرفت علمی و صنعتی بررسی کنیم، باید یک قدم به عقب برگردیم و نگاهی به نحوهی رشد الگوریتمهای ناوبری رباتها در سالهای اخیر بیندازیم. بیشتر روشهای موجود، بهخصوص آنهایی که بر پایهی یادگیری تقویتی بنا شدهاند، یک مسیر تکراری را طی کردهاند:
ساختار پیچیدهتر، سنسورهای بیشتر، شبکههای عمیقتر، و تنظیمات الگوریتمی ظریفتر. اما با وجود این پیشرفتها، بسیاری از آنها هنوز در محیطهای واقعی، ناپایدار، پرنویز و صنعتی دچار شکست میشوند. چرا؟
چون آنچه بهدرستی تغییر نکرده، منطق پاداشدهی به ربات است.
در اغلب این مدلها، پاداش صرفاً یک عدد است: اگر ربات به هدف رسید، پاداش میگیرد؛ اگر برخورد کرد، جریمه میشود؛ و در تمام مسیر، چیزی نمیآموزد. این رویکرد از اساس محدودکننده است، چون ربات تنها در نقاط انتهایی رفتار بازخورد میگیرد، نه در طول مسیر — مسیری که پر از تصمیمهای جزئی اما حیاتی است.
مقالهی حاضر دقیقاً این نقطهضعف بنیادین را هدف قرار داده و بهجای افزودن پیچیدگی در ساختار، کیفیت سیگنال یادگیری را بازتعریف کرده است.
رویکرد Heuristic Dense Reward Shaping (HDRS) که در این مقاله معرفی میشود، بر پایهی یک ایدهی بسیار ساده اما قدرتمند بنا شده است: ربات باید در هر لحظه از مسیر، حس کند که در حال بهبود یا بدتر شدن است — درست مانند یک انسان.
HDRS از مفهومی الهام گرفته است که در مهندسی کلاسیک به خوبی شناخته شده: میدان پتانسیل. در این مدل، هر موقعیت مکانی، زاویه، فاصله، یا حالت ربات دارای یک “پتانسیل پاداش” است. ترکیبی از جذابیت هدف و دافعهی موانع، یک فضای پیوستهی پاداش ایجاد میکند که ربات را بهصورت تدریجی، هوشمند و منطقی به سمت تصمیم بهتر سوق میدهد. به زبان دیگر، HDRS نهتنها مقصد را مشخص میکند، بلکه کیفیت مسیر را هم میسنجد و هدایت میکند.
اما این صرفاً یک ترفند عددی نیست. طراحی HDRS با دقت زیادی به رفتار واقعی رباتها و محیطهای صنعتی تنظیم شده است. پاداش مثبت برای نزدیکشدن به هدف، جریمهی پیوسته برای نزدیکی به مانع، مجازات برای نوسانهای اضافی در سرعت چرخشی، و حتی درک زاویهی صحیح نزدیکشدن به هدف — همهی این عوامل در HDRS بهطور همزمان لحاظ شدهاند. این یعنی: ربات دیگر نیاز ندارد محیط را بشناسد یا نقشه داشته باشد؛ کافیست بتواند “بفهمد” چه رفتاری مطلوب است.
از نظر الگوریتمی، HDRS بهجای حرکت بهسمت مدلهای بسیار پیچیدهی یادگیری، مثل SAC یا TD3، بر پایهی DDPG پیادهسازی شده است؛ مدلی سبک، کمهزینه، و مناسب برای محیطهای Real-Time صنعتی. این انتخاب هوشمندانه باعث میشود پیادهسازی HDRS حتی روی AMRهایی با منابع پردازشی محدود هم ممکن باشد.
در عوضِ پیچیدگی، قدرت HDRS از طراحی پاداش دقیق و مهندسی رفتار نشأت میگیرد — درست همانچیزی که در محیط صنعتی مهم است: عملکرد پایدار، سریع، و قابل اعتماد.
و در نهایت، چیزی که HDRS را از مدلهای مبتنی بر Artificial Potential Field (APF) نیز متمایز میکند، همین نگاه یادگیرانه است. برخلاف APF که حرکت ربات را مستقیماً از ترکیب بردار نیروها محاسبه میکند (و در نتیجه مستعد نوسان و گیرکردن در بنبستهاست)، HDRS از این نیروها صرفاً برای هدایت یادگیری استفاده میکند — یعنی ربات یاد میگیرد چگونه از پاداشها برای تصمیمگیری استفاده کند، نه اینکه تنها بر اساس فورسها حرکت کند.
بنابراین، نقطه تمایز این مقاله در یک جمله خلاصه میشود:
مقاله به جای بزرگتر کردن مغز ربات، زبان گفتوگویش با محیط را هوشمند کرده است.
رویکردی که نهتنها در شبیهسازی کار میکند، بلکه در محیط صنعتی واقعی هم قابل پیادهسازی، مقاوم، و مؤثر است — و این دقیقاً همان چیزیست که صنعت امروز به آن نیاز دارد.
برای تغییر این متن بر روی دکمه ویرایش کلیک کنید. لورم ایپسوم متن ساختگی با تولید سادگی نامفهوم از صنعت چاپ و با استفاده از طراحان گرافیک است.
روش و چارچوب پیشنهادی مقاله
HDRS؛ ترکیب دانش مهندسی و هوش مصنوعی برای ناوبری بدون نقشه در صنعت
۱. طراحی حالت (State Space) و فضای اقدام (Action Space)
در طراحی هر الگوریتم یادگیری تقویتی، «آنچه ربات میبیند» (state) و «آنچه میتواند انجام دهد» (action) تعیینکنندهی موفقیت یا شکست مدل است.
▪ چه چیزی به ربات داده میشود؟ مدل HDRS از یک بردار ۱۹۴ بُعدی بهعنوان ورودی استفاده میکند که شامل این موارد است:
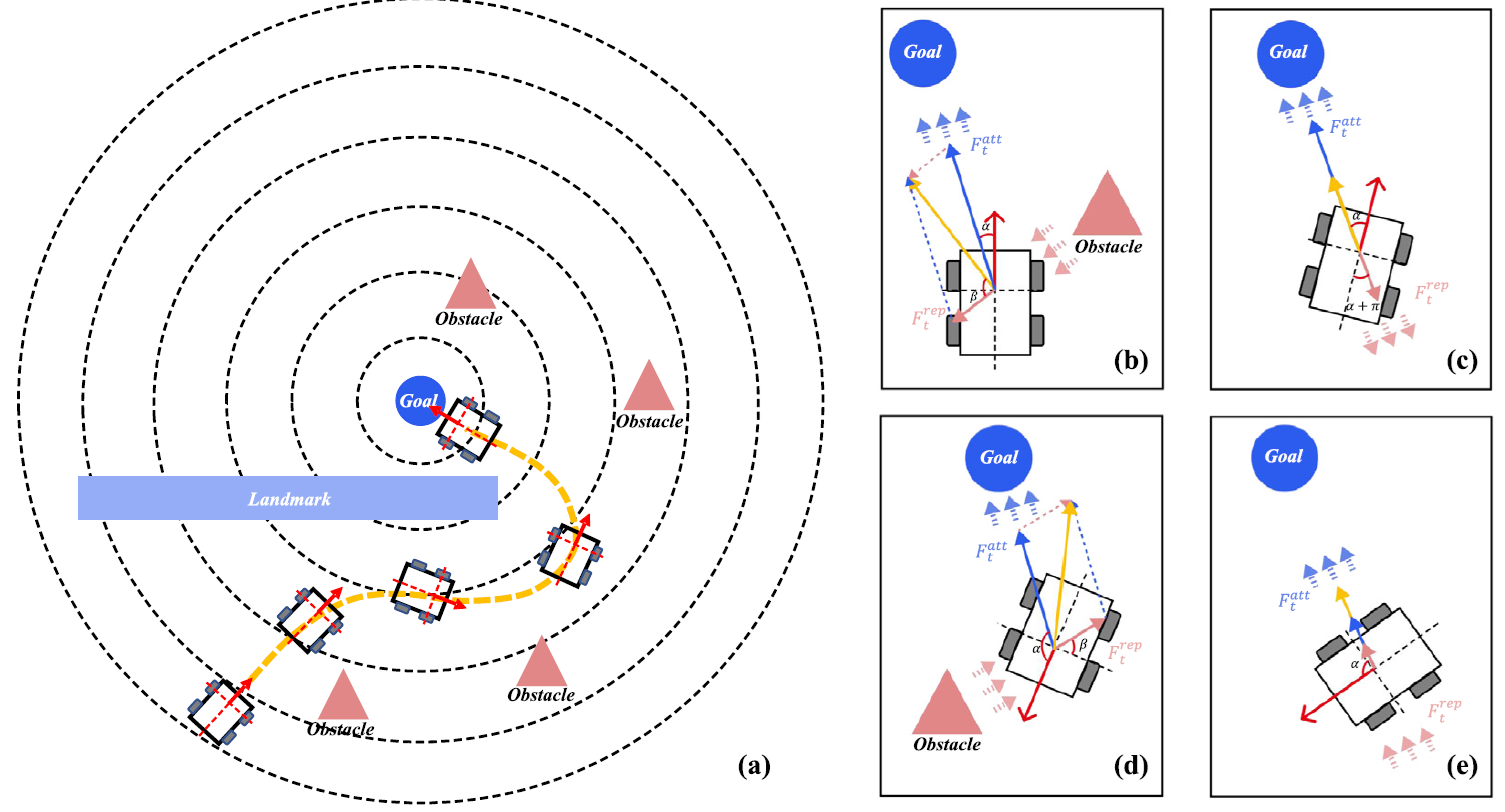
فاصله اقلیدسی تا هدف (dt): این مقدار مشخص میکند ربات چقدر با نقطه مقصد فاصله دارد. از آن برای تشویق ربات به نزدیک شدن به هدف استفاده میشود.
زاویه انحراف از هدف (α): ربات نهتنها باید به هدف برسد، بلکه باید «در راستای درست» حرکت کند. این زاویه مشخص میکند که آیا ربات بهسمت هدف حرکت میکند یا در حال دور زدن آن است.
فاصله تا نزدیکترین مانع (do) و زاویه آن (β): برای جلوگیری از برخورد، ربات باید بداند که نزدیکترین مانع کجاست و در چه جهتی قرار دارد. این پارامترها کمک میکنند که ربات تصمیم بگیرد چگونه مانع را دور بزند.
دادههای خام LiDAR (۱۹۰ نقطه): این اطلاعات کامل از محیط اطراف در قالب یک «نقشه زنده» به مدل داده میشود — شبیه یک حس بینایی صنعتی. این دادهها به ربات اجازه میدهد حتی بدون نقشه، موانع را در زاویهها و فاصلههای مختلف شناسایی کند.
▪ فضای اقدام (action space) اکشنهای خروجی مدل شامل دو مقدار پیوسته هستند:
سرعت خطی (v): میزان پیشروی به سمت جلو
سرعت زاویهای (ω): جهت و شدت چرخش به چپ یا راست
این انتخاب، برخلاف روشهای گسسته، به ربات اجازه میدهد حرکاتی نرم، روان و دقیق انجام دهد — که برای حرکت در محیطهای شلوغ صنعتی حیاتی است.
۲. طراحی پاداش متراکم (HDRS: Heuristic Dense Reward Shaping)
اینجا قلب الگوریتم نهفته است. در این بخش، مدل یاد میگیرد نهتنها “به کجا برود”، بلکه “چگونه بهتر برود”. HDRS با سه مؤلفهی مکمل تعریف شده:
▪ جذابیت هدف (Attractive Reward):
بهجای اینکه تنها وقتی ربات به هدف میرسد، پاداش بگیرد، HDRS در هر لحظه میزان نزدیکی به هدف و جهت حرکت را بررسی میکند. اگر ربات مستقیماً به سمت هدف در حال حرکت باشد، پاداش مثبت بیشتری دریافت میکند. اگر از هدف منحرف شود، با تابعی مبتنی بر فاصله و زاویه، پاداش کاهش مییابد. این مکانیزم باعث میشود مدل نهتنها سریعتر به هدف برسد، بلکه مسیر بهینهتری را یاد بگیرد.
▪ دافعه از موانع (Repulsive Reward)
در اکثر الگوریتمهای DRL، برخورد تنها زمانی باعث جریمه میشود که اتفاق افتاده باشد. اما HDRS زودتر وارد عمل میشود: اگر مانعی در مسیر مستقیم ربات قرار داشته باشد، و فاصله آن از حد آستانه کمتر شود، یک سیگنال جریمه پیوسته بر اساس فاصله و زاویه نسبت به مانع اعمال میشود. به زبان ساده، ربات با نزدیکشدن به موانع «احساس خطر» میکند و قبل از برخورد، رفتار خود را اصلاح میکند. این پاداش منفی با توابع نمایی یا معکوس طراحی شده که شدت واکنش را کنترل کند.
▪ تنبیه برای رفتار ناپایدار (Dissipative Term)
هر بار که ربات تغییر زاویه شدید یا نوسانهای کنترلنشده دارد، این موضوع بهعنوان اتلاف انرژی یا ناهمواری در عملکرد در نظر گرفته میشود و جریمه اعمال میشود. این بخش کمک میکند تا حرکتها طبیعیتر، یکنواختتر و صنعتیتر باشند — مناسب برای کاربردهایی مثل حمل بار، حرکت در میان انسانها یا ناوبری در خطوط باریک.
۳. ساختار یادگیری: Actor–Critic با الگوریتم DDPG
HDRS روی الگوریتم DDPG (Deep Deterministic Policy Gradient) پیاده شده؛ انتخابی کاملاً آگاهانه و مهندسیشده. چرا DDPG؟
زیرا که فضای تصمیمگیری پیوسته است، معماری سبکوزنی دارد، یادگیری پایدار در محیطهای نویزی دارد، قابلاجرا روی پردازندههای صنعتی و سیستمهای سبک است.
چگونه کار میکند؟ DDPG از دو شبکه اصلی استفاده میکند:
Actor: سیاست (پالیسی) را تولید میکند، یعنی از روی حالت محیط (state) → اکشن را پیشبینی میکند
Critic: کیفیت اکشن را ارزیابی میکند (Q-value)، یعنی چقدر این تصمیم خوب بوده
مدل با استفاده از یادگیری تدریجی و بازپخش تجربیات گذشته (Replay Buffer)، از تصمیمات قبلی میآموزد. همچنین شبکههای هدف (Target Networks) برای تثبیت یادگیری استفاده شدهاند، با نرخ بهروزرسانی آرام τ = 0.01 تا نوسانات یادگیری کنترل شود.
۴.مکانیزم انتقال از شبیهسازی به واقعیت (Sim-to-Real)
اجرای مدل در محیط شبیهسازی کافی نیست. مدل باید در کف کارخانه، بین انسانها، لیفتراکها و موانع تصادفی هم بتواند کار کند. HDRS این انتقال را هوشمندانه طراحی کرده:
▪ افزودهشدن نویز مصنوعی به دادهها
در حین آموزش، دادههای ورودی مثل فاصله، زاویه، اسکن لیزر و مکانیابی، با نویزهای کوچک ولی واقعی ترکیب میشوند. این کمک میکند که مدل در برابر خطاهای دنیای واقعی (مثل لرزش سنسور، تأخیر شبکه یا خطای SLAM) تابآوری بالا داشته باشد.
▪ رابط اجرا در محیط واقعی با ROS
مدل نهایی بهراحتی قابل اجرا در ROS است؛ جایی که دادههای سنسور از /scan، وضعیت موقعیت از /odom و دستورات حرکتی از /cmd_vel گرفته و اعمال میشوند. این یعنی بدون نیاز به تغییر در ساختار ربات یا طراحی سیستم کنترل، میتوان HDRS را روی ربات موجود پیادهسازی کرد.
اکنون با این جزئیات: میدانیم ربات چگونه میبیند، چگونه تصمیم میگیرد و چرا عملکردش در دنیای واقعی مؤثر است و HDRS را نه بهعنوان یک تئوری دانشگاهی، بلکه بهعنوان یک معماری مهندسیشده و عملیاتی برای صنعت واقعی میشناسیم
تحلیل اجرای مدل، مقایسه با سایر روشها و نتایج تجربی
عملکردی فراتر از انتظار؛ وقتی HDRS در میدان واقعی میدرخشد
مدلی که در محیطهای واقعی صنعتی جواب ندهد، حتی اگر روی کاغذ بهترین باشد، صرفاً یک تمرین آکادمیک باقی میماند. اما آنچه مقالهٔ حاضر با دقت و ظرافت نشان میدهد این است که HDRS نهتنها روی شبیهسازهای صنعتی دقیق کار میکند، بلکه رفتارش بهشکلی طراحی شده که با کمترین اصطکاک، به دنیای واقعی منتقل شود و عملکردش حفظ شود.
برای سنجش عملیاتی بودن این مدل، نویسندگان آن را در سه محیط با سطوح پیچیدگی متفاوت آزمودهاند: یک مسیر مستقیم و ساده برای بررسی پایهای، یک راهرو باریک با موانع نزدیک برای ارزیابی تصمیمگیری در فضای محدود، و در نهایت، یک مانع Uشکل که برای بسیاری از الگوریتمها چالشبرانگیز است. این طراحی آزمایشها بسیار هوشمندانه است؛ چون از سادگی تا واقعیت دشوار صنعتی را پوشش میدهد. نکته قابل توجه دیگر این است که تمامی این سناریوها با دادههایی همراه بودند که بهصورت مصنوعی نویزدار شده بودند. این یعنی حتی در محیط شبیهسازیشده، مدل با سیگنالهای ناقص و مختل مواجه بود تا شرایط واقعی را تقلید کند؛ کاری که در بسیاری از مقالات مشابه دیده نمیشود.
در این محیطها، HDRS عملکردی درخشان ارائه میدهد. نخست، مدل در مدت زمان بسیار کوتاهتری نسبت به الگوریتمهای دیگر به پایداری در یادگیری میرسد. برای مثال، مدل کلاسیک DDPG نیاز به بیش از ۸۰۰ اپیزود آموزش داشت تا رفتار قابل قبولی یاد بگیرد، اما HDRS تنها در حدود ۲۰۰ اپیزود به مرحلهی همگرایی رسید. این یعنی کاهش زمان آموزش تا یکچهارم، که در صنعت، تفاوت بین یک پروژهی موفق و یک پروژهی رهاشده را رقم میزند.
در سنجش نرخ موفقیت، HDRS توانست در بیش از ۹۸ درصد موارد به هدف برسد، بدون برخورد و با طی مسیر ایمن. این عدد، مخصوصاً در سناریوی دشوار Uشکل که نیاز به عقبنشینی، تغییر زاویه و تصمیمگیری ترکیبی دارد، نشان میدهد مدل توانسته نهفقط مسیر کوتاه را حفظ کند، بلکه «منطق حرکت در محیط پیچیده» را هم بهخوبی درک کند. بسیاری از مدلهای جایگزین، از جمله SAC-SP و GRS، در همین سناریو، دچار رفتار نوسانی یا بنبست تصمیمگیری شدند؛ یعنی یا در میان مانعها گیر افتادند یا به مسیر بیربط منحرف شدند.
از منظر کیفیت رفتار حرکتی نیز HDRS برتری محسوسی دارد. برخلاف بسیاری از مدلهای دیگر که مسیر حرکت ربات در آنها نوسانهای شدید دارد و ربات مدام تغییر زاویهی ناگهانی یا توقفهای بیمورد دارد، HDRS بهدلیل داشتن تنبیه برای تغییرات غیرضروری در سرعت زاویهای، رفتار طبیعیتر و نرمتری از خود نشان میدهد. در محیط صنعتی، بهویژه جایی که ربات بار حمل میکند یا بین انسانها حرکت میکند، این نرمی و پیوستگی حرکات نهتنها موجب افزایش ایمنی، بلکه کاهش استهلاک قطعات مکانیکی نیز میشود.
اما شاید مهمترین نکته، نحوهٔ انتقال مدل از محیط شبیهسازی به دنیای واقعی باشد. برخلاف بسیاری از الگوریتمها که پس از آموزش، نیاز به تنظیمات دوباره، روتیونینگ و انطباق دستی با شرایط واقعی دارند، HDRS بهگونهای طراحی شده که با اعمال نویز و خطاهای طبیعی در فاز آموزش، از همان ابتدا برای واقعیت آماده شده است. به همین دلیل، مدل میتواند بدون هیچ تنظیم اضافهای روی یک AMR فیزیکی اجرا شود و عملکرد قابل قبولی داشته باشد. این ویژگی، مزیتی بزرگ برای صنایع است؛ چون زمان پیادهسازی، هزینههای آزمونوخطا، و نیاز به مهارتهای تخصصی برای نگهداری الگوریتم را به حداقل میرساند.
در مجموع، آنچه از نتایج این مقاله برداشت میشود این است که HDRS نهفقط یک پیشرفت در طراحی پاداش در DRL است، بلکه یک پاسخ کامل، مهندسیشده و صنعتی به نیاز روز ناوبری رباتها در محیطهای بدون نقشه، متغیر و چالشبرانگیز محسوب میشود.
راهبردهای اجرایی و نسخهی بومیشده برای صنعت ایران
از مقاله تا میدان عملیات؛ چگونه HDRS را در صنعت ایران پیاده کنیم؟
هر فناوری اگر نتواند در شرایط خاص یک کشور یا صنعت خاص بومیسازی شود، دیر یا زود از میدان رقابت حذف میشود. الگوریتم HDRS با وجود اینکه در یک مقاله بینالمللی منتشر شده، اما بهدلیل سادگی معماری، وابستگی پایین به زیرساخت و رویکرد عملگرایانه، بهشکلی کمنظیر برای انتقال به صنایع ایران مناسب است — بهشرط آنکه با شناخت دقیق از محدودیتها و ظرفیتها، برای پیادهسازی آن یک مسیر گامبهگام تدوین شود.
اولین نکته این است که HDRS برای اجرا به سیستمهای نقشهبرداری گرانقیمت، GPS، یا موقعیتیابی لیزری پیشرفته نیاز ندارد. همین ویژگی آن را برای بسیاری از واحدهای تولیدی و انبارهای متوسط و بزرگ در ایران که زیرساخت دیجیتالشدهی کامل ندارند، به گزینهای مقرونبهصرفه و در دسترس تبدیل میکند. تنها الزامات آن استفاده از یک اسکنر لیزری دوبعدی (مثل LiDARهای موجود در بازار ایران)، سیستم کنترل حرکتی ساده (مثل بردهای ROS-ready)، و یک کانال برای دریافت مختصات نسبی هدف است — چیزی که حتی با یک ماژول UWB، یا شبکه Wi-Fi داخلی نیز قابل اجراست.
از نظر سختافزاری، بسیاری از AMRهای ایرانی یا چینی موجود در بازار با سختافزار متوسط و پردازندههای سبک طراحی شدهاند. HDRS به دلیل اجرای سبک بر مبنای DDPG و استفاده از شبکههای عصبی ساده، کاملاً روی این رباتها قابل اجراست؛ بدون نیاز به GPU یا ایستگاه محاسباتی جداگانه. این یعنی الگوریتم مستقیماً میتواند روی پردازندهی onboard اجرا شود، و سیستم بدون نیاز به اتصال دائم به سرور، بهشکل محلی تصمیمگیری کند.
از نظر نرمافزاری نیز اجرای HDRS بر پایهی پلتفرم ROS انجام میشود که هم اکنون نیز در بسیاری از پروژههای رباتیک ایران بهکار گرفته میشود. این یعنی تقریباً تمامی شرکتهایی که با رباتهای خودمختار یا نیمهخودکار کار کردهاند، میتوانند بهسرعت این الگوریتم را در معماری خود پیاده کنند. دادههای مورد نیاز الگوریتم، یعنی اسکنهای سنسور لیزری، وضعیت موقعیت، و دستورات حرکتی، از همان تاپیکهای استاندارد در ROS (نظیر /scan, /cmd_vel, /odom) گرفته میشوند و نیاز به بازطراحی سیستم کنترل نیست.
اما مهمتر از همه، سازگاری این الگوریتم با «هرجومرج واقعی» در محیطهای صنعتی ایران است. بسیاری از واحدهای صنعتی ایران از نقشههای CAD دقیق یا چیدمان ثابت برخوردار نیستند. چرخش خطوط، موانع موقتی، حضور نیروی انسانی در مسیر حرکت ربات، یا حتی تغییرات شبانهروزی در مسیر حمل بار، مشکلاتی رایجاند. HDRS با اتکا به دادههای لحظهای، بدون وابستگی به موقعیت مطلق، و با رفتار تطبیقپذیر، دقیقاً برای چنین فضاهایی طراحی شده است. این یعنی نهتنها در محیطهای سازمانیافته، بلکه در بسترهای آشفته، در حال گذار یا حتی پروژههای صنعتی در مناطق ویژه اقتصادی، این الگوریتم میتواند تفاوت ایجاد کند.
از نظر عملیاتی، چرخهی پیادهسازی HDRS در یک صنعت ایرانی میتواند چنین باشد:
ارزیابی اولیه سختافزار AMR موجود – بررسی امکان اتصال سنسور لیزر، کنترلکننده ROS، و دریافت داده موقعیت
آموزش مدل در محیط شبیهسازی داخلی (Gazebo یا Webots) – با نقشهسازی تقریبی از محیط واقعی و وارد کردن نویزهای کنترلشده
استقرار مدل آموزشدیده روی ربات واقعی با ROS Interface – بدون نیاز به بازآموزی یا تغییر ساختار
پایش و بهینهسازی محلی – بررسی رفتار در سناریوهای واقعی و اعمال تنظیمات سبک در پارامترهای پاداش در صورت نیاز
این مسیر، نسبت به اکثر پروژههای پیادهسازی WMS، SLAM یا سیستمهای ناوبری کلاسیک، بهمراتب سادهتر، سریعتر و کمهزینهتر است. بهویژه برای شرکتهایی که زیرساخت فنی متوسط دارند، اما بهدنبال افزایش اتوماسیون بدون ایجاد وابستگی سنگین زیرساختی یا سرمایهگذاریهای چند میلیاردی هستند، HDRS میتواند یک راهحل طلایی باشد.
در نهایت، اگر یک برند ایرانی بخواهد وارد دنیای AMRهای هوشمند، مستقل از نقشه، و دارای تصمیمگیری تطبیقپذیر شود، HDRS انتخابی منطقی، کاربردی و قابل استقرار در ظرف چند هفته خواهد بود — نه چند سال
جمعبندی نهایی
در جهانی که مسیرهای مشخص به سرعت در حال از بین رفتناند، نیاز به رباتهایی که بتوانند «در بینقشهگی تصمیم بگیرند» از یک انتخاب فناورانه، به یک ضرورت رقابتی تبدیل شده است. الگوریتم HDRS، با مهندسی دقیق در ساختار پاداش و طراحی سبک در بستر یادگیری تقویتی، دقیقاً برای همین جهان ساخته شده — جهانی که در آن محیط ثابت نمیماند، موانع غیرمنتظرهاند، و نقشهها قبل از چاپ، منسوخ میشوند.
در این مقاله، نهتنها چارچوب HDRS بهدقت تشریح شد، بلکه دیدیم چگونه این مدل در مقایسه با روشهای دیگر، سریعتر یاد میگیرد، ایمنتر حرکت میکند، طبیعیتر رفتار میکند، و مهمتر از همه، در محیطهای واقعی صنعتی، بدون وابستگی به زیرساخت خاص، عملکرد قابل اعتمادی دارد.
از طرفی، مزیت بزرگ HDRS در این است که برخلاف بسیاری از راهکارهای پیچیده و گرانقیمت جهانی، برای پیادهسازی در صنعت ایران کاملاً مناسب است. این الگوریتم:
نیازی به GPS، نقشه، SLAM یا زیرساخت شبکهای سنگین ندارد
بر مبنای ROS قابل اجراست و روی سختافزارهای موجود در بازار ایران پیاده میشود
با منابع محاسباتی سبک کار میکند و تصمیمگیری در لحظه را ممکن میسازد
و از همه مهمتر، با رفتار انسانی و حرفهای سازگار است؛ یعنی نهتنها به هدف میرسد، بلکه بهدرستی، هوشمندانه و ایمن میرسد
برای شرکتهایی که در حوزهی لجستیک، مدیریت انبار، رباتیک صنعتی، یا حملونقل داخلی کارخانه فعالیت میکنند، HDRS میتواند نقطه شروع نسل جدیدی از اتوماسیون باشد؛ نسلی که بهجای اتکا به نقشه، به «درک محیط» تکیه میکند.
اگر برند شما به دنبال راهکارهایی در حوزهی ناوبری هوشمند بدون نقشه، ارتقای عملکرد AMR، یا طراحی سیستمهای تصمیمیار در بسترهای پویا و صنعتی است، ما میتوانیم در موارد زیر همراه شما باشیم:
طراحی و سفارشیسازی مدل یادگیری تقویتی برای محیط خاص شما
ارزیابی سختافزار موجود و بومیسازی الگوریتم HDRS برای رباتهای ایرانی
آموزش، انتقال دانش و راهاندازی پایلوت عملیاتی در انبار یا خط تولید
ارائه داشبورد تحلیلی از عملکرد ناوبری و بهینهسازی رفتاری AMR
برای شروع همکاری یا دریافت نسخهی فنی کامل، مستندات اجرایی یا مشاوره، کافیست با تیم ما تماس بگیرید.
📚 مشخصات مقاله علمی مرجع:
عنوان: Heuristic dense reward shaping for learning-based map-free navigation of industrial automatic mobile robots
نویسندگان: Yizhi Wang, Yongfang Xie, Degang Xu, Jiahui Shi, Shiyu Fang, Weihua Gui
ژورنال: ISA Transactions, Volume 156, 2025, Pages 579–596
DOI: 10.1016/j.isatra.2024.10.026
{kind=link}
بدون نظر