

از ناوبری رباتهای هوشمند تا اجتناب تطبیقی در شرایط بلادرنگ
در گذار صنعت بهسوی هوشمندسازی عملیات تولید، مونتاژ، انبارداری و لجستیک، سیستمهای رباتیک نقش اساسی در افزایش ایمنی، بهرهوری و چابکی فرآیندها ایفا میکنند. بهویژه بازوهای رباتیک با درجات آزادی بالا (مانند ۶ یا ۷-DOF manipulators) و وسایل هدایتشونده خودکار (AGV) در خطوط تولید و فضای کارخانهای، نیازمند الگوریتمهای ناوبری هوشمند هستند که بتوانند در شرایط پیچیده، غیرقطعی و متغیر محیطی، رفتار حرکتی ایمن و واکنشپذیر ارائه دهند.
در چنین محیطهایی، موانع ثابت و متحرک، اختلالات لحظهای، و همزیستی با اپراتور انسانی، مسائلی هستند که راهکارهای کلاسیک کنترلی مانند PID، MPC یا الگوریتمهای اجتناب مبتنی بر قانون (Rule-Based) بهتنهایی توانایی پاسخدهی به آنها را ندارند. زیرا این روشها معمولاً فاقد درک بلندمدت از محیط و پیشبینی تغییرات آینده هستند؛ همچنین در محاسبات بلادرنگ برای بازوهای با درجات آزادی بالا، دچار کندی یا ناپایداری میشوند.
در چنین بستری، پژوهش حاضر با تمرکز بر توسعه یک مدل یادگیری تقویتی عمیق (DRL) برای کنترل بلادرنگ ربات در مواجهه با موانع دینامیک، مسیر نوینی را پیشنهاد میدهد. این مدل با تلفیق دو تکنیک کلیدی:
الگوریتم Soft Actor-Critic (SAC) برای یادگیری سیاست حرکتی پایدار و تصادفی،
و مکانیزم Prioritized Experience Replay (PER) برای تسریع و جهتدهی به فرآیند یادگیری،
توانسته یک کنترلکننده تطبیقی تولید کند که بدون نیاز به محاسبه مسیر لحظهای، با تکیه بر تجربههای قبلی، واکنشهای ایمن و بلادرنگ در برابر موانع متحرک تولید میکند.
از منظر کاربردی، این مدل نهتنها برای بازوهای رباتیک ۷-DOF قابل استفاده است، بلکه با توسعه مناسب، میتواند به عنوان یک کنترلر بلادرنگ برای رباتهای متحرک (مانند AMR یا AGV) نیز بهکار گرفته شود — آن هم در محیطهایی با ترافیک انسانی، ماشینآلات متحرک، و تغییرات ساختاری سریع.
در این بلاگ، ساختار فنی این مدل، نوآوریهای بهکاررفته، تحلیل عملکرد آن در محیطهای شبیهسازیشده، و مسیرهای پیادهسازی صنعتی آن را بررسی خواهیم کرد.
چالشهای فنی در کنترل بلادرنگ رباتهای صنعتی در حضور موانع متحرک
طراحی یک سیستم ناوبری یا کنترل حرکتی برای رباتهای صنعتی، زمانی که در معرض موانع متحرک، تداخل انسانی و محدودیتهای محیطی هستند، یکی از چالشبرانگیزترین مسائل در رباتیک پیشرفته محسوب میشود. این مسئله بهویژه در بازوهای چنددرجهآزادی (مانند ۷-DOF) که فضای کاری پیچیدهای دارند، و در AGVهایی که باید بدون توقف و با سرعت بالا از میان موانع دینامیکی عبور کنند، اهمیت دوچندان دارد. در ادامه، به مهمترین چالشهای فنی این حوزه اشاره میکنیم:
۱. پیچیدگی فضای حالت در بازوهای چنددرجهآزادی: بُعد بالا، قید زیاد، دینامیک پیچیده
در سیستمهای رباتیک با درجات آزادی بالا (مانند ۶-DOF و ۷-DOF)، فضای حالت بهطور نمایی بزرگتر از سیستمهای سادهتری مانند AGV یا رباتهای دو مفصلی میشود. هر مفصل مستقل یک یا چند متغیر وضعیت دارد (زاویه، سرعت، گشتاور)، و اندافکتور نیز باید موقعیت نهایی را در فضای سهبعدی با دقت بالا دنبال کند. این یعنی کنترلکننده باید در هر گام زمانی، بر اساس برداری متشکل از حداقل ۱۴ تا ۲۰ متغیر، تصمیمگیری کند.
علاوه بر آن، باید به قیود سختگیرانه زیر نیز پاسخ داده شود:
محدودیتهای سینماتیکی و دینامیکی: حداکثر سرعت مفصل، گشتاور مجاز، نواحی ممنوعه برای حرکت
اجتناب از خودبرخوردی (Self-Collision): اجتناب از تماس تصادفی بین لینکهای مختلف بازو
مرزهای workspace: محدودیتهای فیزیکی و هندسی در محیط کاری بازو
خط سیر پیوسته و ایمن: تضمین انحراف حداقلی از مسیر هدف
کنترل دقیق و پایدار چنین سیستمی در حضور عوامل اختلالزا (مانند نیروی غیرمنتظره یا ورود مانع متحرک) نیازمند الگوریتمهایی است که بتوانند در فضای حالت غیرخطی، با ابعاد بالا و چندقید، سیاست حرکتی بهینه یا شبهبهینه را در زمان بسیار کوتاه تولید کنند — کاری که از توان روشهای کنترلی سنتی خارج است.
۲. عدم ایستایی، عدم قطعیت و پیشبینیناپذیری رفتار موانع دینامیک
یکی از متمایزترین ویژگیهای محیطهای صنعتی مدرن، وجود موانع متحرک با رفتارهای غیرقابل پیشبینی است. این موانع میتوانند اپراتورهای انسانی، لیفتراکها، سایر AGVها، یا حتی بازوهای رباتیک دیگر باشند که رفتارشان تابعی از تصمیمات خارج از کنترل ما است. برخلاف مدلهای استاتیک که بر پایه موقعیت ثابت موانع برنامهریزی میشوند، سیستمهای ناوبری در محیطهای دینامیک باید قابلیت پیشبینی، انطباق لحظهای، و بازطراحی فوری مسیر را داشته باشند. در این شرایط، دو نوع عدم قطعیت رخ میدهد:
عدم قطعیت در موقعیت آینده موانع: مسیر حرکتی مانع ممکن است قابل پیشبینی نباشد یا بهشکل تصادفی تغییر کند.
عدم قطعیت در تعامل: ممکن است مانع در لحظه تصمیم به توقف، شتابگیری یا چرخش بگیرد — بدون هشدار یا نشانه قبلی.
کنترلکنندهای که بهصورت لحظهای و بدون حافظه عمل کند (مانند سیستمهای rule-based)، نمیتواند الگوی احتمالی حرکت مانع را در نظر بگیرد. در حالیکه برای جلوگیری از برخورد، سیستم باید: روند سرعت و مسیر مانع را درک کند، خطر برخورد را بر اساس زمان بهبرخورد (Time-to-Collision) تخمین بزند و مسیر خود را در زمان کمتر از بازه پیشبینیشده اصلاح کند. در چنین بستر غیرقطعی، تنها رویکردهایی موفقاند که امکان یادگیری تجربه، تحلیل احتمال، و تصمیمگیری تطبیقی در زمان کوتاه داشته باشند — که یادگیری تقویتی یکی از بهترین ابزارهای آن است.
۳. نیاز به کنترل بلادرنگ در سختافزارهای محدود: چالش زمان، منابع و پایداری
یکی از الزامات اساسی در کنترل حرکت رباتها، بهویژه در محیطهای صنعتی واقعی، اجرای تصمیمگیری با تأخیر کمتر از چند ده میلیثانیه است. این در حالیست که بسیاری از الگوریتمهای کلاسیک یا بهینهسازی عددی، مانند MPC، QP-based planning یا الگوریتمهای مبتنی بر نمونهبرداری (sampling-based)، نیازمند حل معادلات پیچیده با فضای جستوجوی بزرگ هستند. در محیط عملیاتی واقعی، به دلایل زیر نمیتوان از چنین الگوریتمهایی استفاده کرد:
منابع پردازشی محدود: اکثر AGVها و بازوهای رباتیک از پردازندههای صنعتی سبک استفاده میکنند (مانند ARM Cortex یا بردهای Jetson).
نیاز به مصرف انرژی کم: کنترلرهایی که نیاز به پردازش مکرر و سنگین دارند، مصرف توان را افزایش داده و عمر باتری را کاهش میدهند.
لزوم پایداری در نرخ نمونهبرداری: اگر محاسبهی فرمان کنترلی در یک چرخه بیش از حد طول بکشد، چرخه کنترلی دچار jitter یا lag میشود، که پایداری کل سیستم را مختل میکند.
بنابراین، باید مدلی طراحی شود که: با پیچیدگی زمانی زیر ۵ms برای هر تصمیم، قابلیت تعبیهشدن در سختافزارهای محدود و قابلیت تعمیم رفتاری بدون نیاز به حل مسأله در لحظه را داشته باشد. معماریهایی مانند Gauss-DNN (در مقاله قبل) یا روش یادگیری تقویتی با replay prioritization (در این مقاله)، دقیقاً در همین راستا عمل میکنند.
۴. ناکارآمدی و عدم تعمیمپذیری روشهای کنترل کلاسیک در محیطهای متغیر و چندعامله
در طول چند دهه گذشته، سیستمهای کنترلی مبتنی بر قواعد ثابت (مانند PID، قوانین منطق فازی، یا میدانهای پتانسیل مصنوعی) در صنایع مختلف استفاده شدهاند. اما این روشها چند ضعف بنیادی دارند که آنها را برای محیطهای چندعامله، غیرایستا، یا دارای ترافیک رباتی نامناسب میسازد:
فاقد قابلیت یادگیری یا تطبیق: آنها نمیتوانند از تجربه قبلی یا رخدادهای گذشته الگو بگیرند
سازگار با سناریوهای از پیش تعریفشده: فقط در شرایطی که کاملاً برای آنها طراحی شدهاند پایدار عمل میکنند
غیرقابل تنظیم برای شرایط بحرانی یا برخوردهای نادر: در سناریوهایی که رفتار جدید بروز میکند (مانند ورود ناگهانی مانع)، این کنترلرها واکنش صحیح ندارند
اغلب وابسته به پارامترهای حساس و نیازمند تنظیم دستی (Tuning)
در محیطهای با تغییرات دینامیکی بالا، حضور انسان، و همکاری چندرباته، مدلهای کنترل کلاسیک بهسرعت دچار واگرایی رفتاری، توقفهای غیرضروری یا حرکات پرنوسان میشوند. در مقابل، مدلهایی که توانایی یادگیری سیاست حرکتی از طریق تقویت رفتار ایمن و موفق در زمان دارند (مانند RL با PER)، قادرند الگوهای جدید را در حافظهی تجربی خود ثبت کرده و در مواجهه مجدد، واکنش مناسبتری نشان دهند.
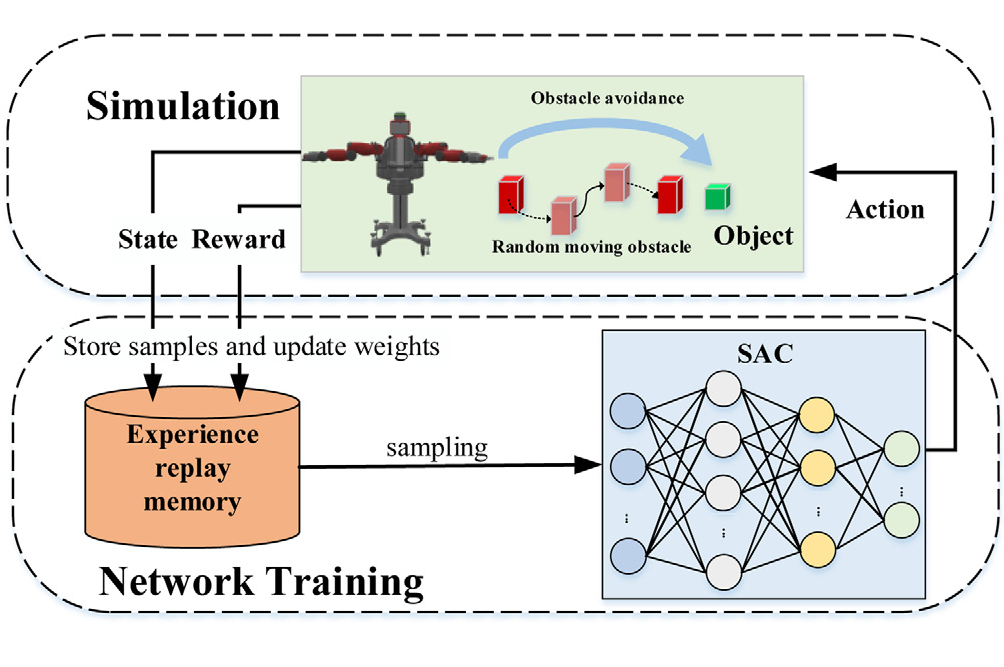
معماری پیشنهادی: طراحی یک مدل کنترل یادگیرنده بلادرنگ با SAC و PER
در رباتیک صنعتی، زمانی که نیاز به تصمیمگیری در شرایط بلادرنگ، در محیطهایی پویا و دارای عدم قطعیت بالا داریم، روشهای یادگیری تقویتی عمیق (DRL) بهعنوان یک رویکرد قدرتمند برای کنترل تطبیقی مطرح میشوند. با این حال، اغلب معماریهای RL در عمل دچار مشکلاتی از قبیل کندی یادگیری، رفتار ناپایدار، یا نیاز به منابع سنگین محاسباتی میشوند — مشکلاتی که مانع پیادهسازی آنها در محیطهای واقعی هستند. مدلی که در این مقاله معرفی شده، با ترکیب دقیق دو تکنیک پیشرفته یادگیری تقویتی یعنی: الگوریتم Soft Actor-Critic (SAC)،و مکانیزم Prioritized Experience Replay (PER) قادر است سیاست حرکتی یک بازوی رباتیک ۷ درجه آزادی یا یک ربات متحرک AGV را، در حضور موانع دینامیکی، با پایداری بالا، دقت کنترلی مطلوب، و پاسخ بلادرنگ یاد بگیرد و پیادهسازی کند.
۱. الگوریتم Soft Actor-Critic (SAC): کنترل تطبیقی در فضای پیوسته و نویزی
الگوریتم Soft Actor-Critic (SAC) بهعنوان یکی از پیشرفتهترین الگوریتمهای یادگیری تقویتی در فضای عمل پیوسته، مبتنی بر چارچوب «حداکثر آنتروپی» (Maximum Entropy RL) طراحی شده است. برخلاف الگوریتمهای کلاسیک مانند DDPG یا PPO که هدف آنها صرفاً بیشینهسازی تابع پاداش است، در SAC یک ترم آنتروپی نیز به تابع هدف اضافه میشود. این ترم آنتروپی باعث میشود عامل در فرآیند یادگیری نهتنها به سمت بیشینهسازی پاداش، بلکه به سمت حفظ تصادفی بودن رفتار خود نیز گرایش داشته باشد. این مفهوم «تصادفیسازی کنترل» در سیستمهایی مانند بازوهای رباتیک یا AGVهایی که در محیطهای غیرقطعی و نویزی حرکت میکنند، مزیت کلیدی به حساب میآید. بهطور خاص:
سیاستهای تصادفی (stochastic policies) امکان تولید رفتارهای متنوعتری را فراهم میکنند که در مواجهه با شرایط ناآشنا یا موقعیتهایی با چند پاسخ قابلقبول، عملکرد پایدارتری خواهند داشت.
این مدلها همچنین در برابر اختلالهای جزئی در ورودی (مانند نویز سنسورها یا خطا در تخمین وضعیت) از پایداری بیشتری برخوردارند.
و در محیطهای مشارکتی، سیاستهای تصادفی رفتار غیرقابل پیشبینیتری ایجاد میکنند که برای جلوگیری از برخورد یا تداخل با سایر رباتها مفید است.
در معماری SAC، دو شبکه عصبی اصلی بهصورت همزمان آموزش داده میشوند:
Critic (شبکههای Q): که مقدار ارزش یک عمل در یک وضعیت را تقریب میزند. دو شبکه Q مستقل برای مقابله با overestimation استفاده میشوند.
Actor: که برای هر وضعیت، یک توزیع احتمال برای اعمال تولید میکند. عمل نهایی از این توزیع گوسین نمونهبرداری و سپس با تابع tanh محدود میشود.
از منظر محاسباتی، الگوریتم SAC در مقایسه با سایر الگوریتمهای RL دارای همگرایی پایدارتر، نرخ یادگیری سریعتر، و حساسیت کمتر به مقیاس پاداش است. این ویژگیها، SAC را برای کنترل بازوهای صنعتی با دینامیکهای پیچیده و قیدهای سخت، مناسب میسازند.
مکانیزم Prioritized Experience Replay (PER): تمرکز یادگیری روی تجربیات باارزشتر
در یادگیری تقویتی، عامل از طریق تعامل با محیط، دادههای متعددی از وضعیت–عمل–پاداش جمعآوری میکند و سپس این دادهها را برای بهروزرسانی شبکههای خود استفاده میکند. در معماریهای کلاسیک، این نمونهبرداری از تجربیات گذشته بهصورت تصادفی انجام میشود. اما در مسائل رباتیک صنعتی که تعاملات بحرانی (مانند لحظات برخورد، مانورهای نزدیک، عبور از بنبست) تعداد محدودی دارند، استفاده یکنواخت از کل تجربیات باعث میشود الگوریتم نتواند از موارد مهم بهطور مؤثر یاد بگیرد. PER این مشکل را حل میکند. در این روش، به هر تجربه در حافظهی replay buffer، یک مقدار اولویت اختصاص داده میشود که معمولاً بر اساس مقدار TD-error آن تعیین میگردد. تجربیاتی که شبکه فعلاً آنها را بد تفسیر میکند یا پاداش ناهمگن دارند (مثلاً یک برخورد شدید)، احتمال بالاتری برای بازپخش مجدد در فرایند آموزش دارند. مزایای فنی این روش در محیطهای کنترلی عبارتاند از:
یادگیری سریعتر در اپیزودهای کوتاه و محیطهای پاداشناهمگن
تمرکز بر رفتارهای بحرانی و بهبود سیاست در نقاط پرریسک
افزایش بازدهی آموزش در محیطهایی که نیاز به واکنشهای ایمن دارند
کاهش پراکندگی یادگیری و بهبود همگرایی
در پیادهسازی مقاله، PER بهصورت ماژول مکمل SAC طراحی شده و replay buffer دارای شاخصهای اولویتگذاری برای تجربیات است. این طراحی باعث شده یادگیری حتی در اپیزودهای کمتکرار ولی با سناریوهای بحرانی، مؤثرتر باشد.
۳. چرخه تصمیمسازی بلادرنگ: طراحی برای پاسخ کنترلی در زیر ۵ میلیثانیه
هدف نهایی از طراحی این معماری، رسیدن به یک سیستم کنترلی است که بتواند در شرایط عملیاتی واقعی، تصمیمگیری حرکتی را در زمان بسیار کوتاه انجام دهد — بدون وابستگی به محاسبات سنگین یا کنترل متمرکز. در کاربردهایی مثل کنترل بازوی ۷ درجه آزادی یا مانور AGV در مسیرهای پویا، تأخیر کنترلی بیش از چند میلیثانیه میتواند منجر به ناپایداری، رفتار نوسانی یا حتی برخورد شود. در این مدل، چرخه کنترل بلادرنگ بهصورت زیر طراحی شده:
دریافت دادههای وضعیت در لحظه: از سنسورها یا سیستمهای تخمین وضعیت (نظیر بردار مفاصل، موقعیت موانع، وضعیت اندافکتور)
ورود به Actor Network: وضعیت وارد شبکه یادگرفتهشده Actor میشود که توزیع گوسین اعمال را تولید میکند
نمونهگیری و محدودسازی عمل: خروجی شبکه بهصورت کنترل گشتاور، شتاب یا فرمان حرکتی بازو محاسبه شده و محدود به محدوده مجاز میگردد
ارسال فرمان به سامانه کنترلی ربات: برای اجرای حرکتی پایدار در چرخه بعدی
در زمان inference، این فرآیند تنها شامل یک بار عبور رو به جلو (forward pass) از شبکه عصبی است، که با شبکهای سبک (معمولاً ۳ تا ۴ لایه MLP) قابل انجام روی سختافزارهای edge مانند Jetson Nano در زیر ۵ms است. این زمان پاسخ، آن را برای پیادهسازی در سیستمهای real-time صنعتی قابل اطمینان میسازد.
۴. مزایای مهندسی ترکیب SAC + PER نسبت به سایر الگوریتمها
ترکیب SAC و PER در این مقاله، پاسخی دقیق به چند نیاز مهندسی اساسی در کنترل رباتهای صنعتی در محیطهای پیچیده است. برخلاف ساختارهای RL ساده (مانند Q-Learning یا DDPG)، یا کنترلهای کلاسیک (مانند MPC یا PID)، این مدل دارای مزایای زیر است:
انعطاف بالا در محیطهای دارای رفتار غیرقطعی
استفاده هوشمند از حافظه تجربه، برای تمرکز یادگیری بر نقاط بحرانی
قابلیت آموزش در محیط شبیهسازی و انتقال به محیط واقعی (Sim2Real)
سازگاری با قیدهای پیوسته، کنترلهای گشتاوری، و سینماتیک پیشرفته بازو
امکان استقرار روی سختافزارهای سبک، با استقلال کامل از سرور مرکزی
این ساختار میتواند جایگزینی قدرتمند برای مدلهای مبتنی بر کنترل قانونمحور یا حتی کنترلهای مبتنی بر مسیر از پیش تعیینشده باشد. زیرا نهتنها در لحظه تصمیمگیری میکند، بلکه سیاست کنترلیای یاد میگیرد که از تجربه، تکرار و خطا ساخته شده و بهمرور تقویت شده است.
تحلیل ساختار شبیهسازی، فضای حالت–عمل و طراحی پاداش در آموزش کنترلر SAC+PER
موفقیت هر مدل یادگیری تقویتی، وابستگی مستقیمی به نحوهی تعریف محیط آموزش، ساختار ورودی–خروجی، و طراحی دقیق تابع پاداش دارد. در این مقاله، محیط شبیهسازیشده برای یک بازوی رباتیک ۷ درجه آزادی (7-DOF manipulator) در نظر گرفته شده که در فضایی با موانع ایستا و متحرک عمل میکند. این بازو باید هم به هدف حرکتی برسد، هم از موانع اجتناب کند، و هم پایداری دینامیکی خود را حفظ نماید. در ادامه، اجزای کلیدی این ساختار شبیهسازی تحلیل میشود:
۱.فضای حالت (State Space): بازتابی دقیق از درک محیط و دینامیک ربات
یکی از الزامات اساسی برای موفقیت یک مدل یادگیری تقویتی در کنترل ربات، تعریف دقیق و هدفمند فضای حالت است. این فضا، معرف «دانش لحظهای» عامل از جهان پیرامون خود است؛ یعنی هر آنچه که باید بداند تا بتواند تصمیم درستی بگیرد. در مدل ارائهشده در مقاله، فضای حالت بهگونهای طراحی شده که هم اطلاعات دینامیکی ربات را شامل شود، هم بازنمایی دقیقی از محیط متغیر را در خود داشته باشد.
در این محیط، عامل یک بازوی ۷ درجه آزادی است که در یک فضای کاری سهبعدی، باید به نقطه هدف برسد و همزمان از برخورد با موانع متحرک جلوگیری کند. بنابراین، فضای حالت شامل مؤلفههایی از چند دسته زیر است:
مشخصات سینماتیکی–دینامیکی بازو: زاویه مفصلها، سرعتهای مفصلی، گشتاورهای فعلی، وضعیت اندافکتور (موقعیت و سرعت خطی و زاویهای)، که همگی از طریق سیستم کنترل پاییندست قابل مشاهده هستند.
اطلاعات موقعیتی هدف: بردار موقعیت و وضعیت هدف نسبت به اندافکتور، که جهتدهی کلی حرکت را تعریف میکند.
موقعیت و سرعت موانع متحرک: که بهصورت بردارهای نسبی بیان میشود. بهجای ثبت مطلق موقعیت موانع، فاصلهی آنها تا اندافکتور و جهت حرکت نسبیشان استفاده میشود تا مدل بهتر بتواند ریسک برخورد را پیشبینی کند.
مقادیر ایمنی مجاورتی: مانند فاصله تا نزدیکترین مانع، نرخ تغییر فاصله، و سایر پارامترهای مرتبط با تماس (Contact Margin) که در تنظیم رفتار اجتنابی مؤثر هستند.
این ترکیب اطلاعات باعث میشود عامل در هر لحظه «ادراکی ترکیبی» از موقعیت خود، هدف، و محیط پیرامون داشته باشد — مشابه چیزی که یک انسان کنترلگر باتجربه در محیط واقعی حس میکند. نتیجه این طراحی، افزایش تعمیمپذیری و کاهش رفتارهای وابسته به جزئیات خاص محیط است.
۲. فضای عمل (Action Space): طراحی کنترلی در سطح گشتاور پیوسته برای پاسخ نرم و دقیق
انتخاب فضای عمل، مستقیماً تعیین میکند که خروجی شبکه عصبی یادگیرنده به چه صورت فرمان صادر کند. در مدل پیشنهادی مقاله، فضای عمل بهصورت پیوسته و بر پایه گشتاور اعمالی به مفصلها تعریف شده است. این انتخاب به چند دلیل کاملاً مهندسیشده و متناسب با سیستمهای واقعی کنترل بازوهای رباتیک است.
اولاً، در بیشتر بازوهای صنعتی سطح بالا، کنترل در سطح گشتاور، امکان مانورهای دقیقتر و سازگاری بهتر با محدودیتهای فیزیکی را فراهم میکند. برخلاف کنترل موقعیتی یا سرعتی که با تأخیر و overshoot همراهاند، گشتاور بهطور مستقیم بر دینامیک تأثیر میگذارد.
دوماً، فضای عمل پیوسته باعث میشود عامل بتواند خروجیهای بسیار نرم، بدون پرش و با دقت بالا تولید کند. این موضوع بهویژه در مواجهه با موانع متحرک ضروری است، چون کوچکترین پرش یا تغییر ناگهانی در فرمان میتواند منجر به برخورد یا بیثباتی شود.
در پیادهسازی مقاله، خروجی شبکه Actor شامل ۷ مقدار پیوسته (برای ۷ مفصل) است، که هر یک از یک توزیع گوسین یادگرفتهشده نمونهبرداری میشوند و با تابع tanh محدود میگردند تا در بازههای فیزیکی مجاز قرار گیرند. این ساختار اجازه میدهد ربات: در حین اجرای مانور، از منابع مکانیکی فراتر نرود، اعمالی مطابق با محدودیتهای صنعتی (torque, slew rate) صادر کند و از رفتارهای نوسانی، لرزشی یا غیرایمن پرهیز کند نتیجه آن یک سیاست کنترلی دقیق، روان و با قابلیت پیادهسازی مستقیم روی سیستم کنترل سطح پایین است.
۳. تابع پاداش: معماری چندبخشی برای توازن بین دقت، ایمنی و پایداری حرکتی
تابع پاداش در یادگیری تقویتی، اصلیترین عامل شکلگیری سیاست یادگیرنده است. طراحی نادرست آن میتواند باعث یادگیری رفتارهای غیربهینه، پرخطر یا ناپایدار شود. در این مقاله، نویسندگان یک تابع پاداش مرکب تعریف کردهاند که چند هدف حیاتی را بهطور همزمان به عامل منتقل میکند. ساختار این تابع شامل مؤلفههای زیر است:
پاداش هدفگرا: کاهش فاصله بین اندافکتور و هدف در هر گام زمانی پاداش مثبت دارد. اگر فاصله افزایش یابد، پنالتی اعمال میشود. این بخش، عامل را بهسوی هدف هدایت میکند.
پنالتی برخورد: برخورد فیزیکی با موانع یا عبور از حداقل فاصله مجاز، جریمه سنگینی دارد. این مؤلفه ایمنی حرکت را تضمین میکند.
پنالتی مانور شدید: اعمال گشتاورهای بسیار بزرگ یا تغییرات ناگهانی در عمل، پنالتی دارد تا رفتار کنترل نرمتر شود.
پاداش تکمیل موفق مأموریت: در صورت رسیدن به هدف بدون برخورد در طول اپیزود، پاداش نهایی قابل توجهی در نظر گرفته شده تا سیاست به سمت دستیابی ایمن سوق یابد.
این طراحی باعث میشود که عامل هم یاد بگیرد چگونه سریع و دقیق حرکت کند، هم چگونه ایمن و پایدار باقی بماند. بهبیان دیگر، عامل نهفقط بر پایه رسیدن، بلکه بر پایه کیفیت رسیدن نیز پاداش دریافت میکند — و این چیزی است که در محیطهای صنعتی حیاتی است.
۴. فرآیند آموزش: یادگیری ایمن و تعمیمپذیر از تجربههای هدفمند
آموزش مدل در این مقاله، در یک محیط شبیهسازیشده انجام شده که شامل سناریوهای متعدد با وضعیتهای اولیه و موقعیت موانع متغیر است. هر اپیزود با یک مقداردهی اولیه تصادفی آغاز میشود تا مدل رفتار تعمیمیافته بیاموزد. مراحل کلیدی فرآیند آموزش:
Replay Buffer اولویتدار (PER): تجربیاتی که دارای خطای بالا، برخورد یا تغییر شدید در مقدار Q هستند، با احتمال بالاتری مجدداً بازپخش میشوند. این باعث تسریع یادگیری و افزایش تمرکز روی دادههای بحرانی میشود.
Dual Critic Networks: برای کاهش overestimation، دو شبکه Q مستقل آموزش داده میشوند و مقدار کمتر از آنها استفاده میشود.
Target Networks و Soft Update: برای پایداری بیشتر، شبکههای هدف با نرخ آهسته بروزرسانی میشوند تا نوسان آموزش کاهش یابد.
Exploration تصادفی با آنتروپی: عامل از توزیع گوسین با واریانس کنترلشده نمونهبرداری میکند تا رفتارهای اکتشافی ایمن ایجاد شود.
معماری بازیابی خطا (Recovery): اپیزودها در شرایطی که عامل رفتار بسیار ناایمن نشان دهد (مثلاً برخورد سخت)، زودتر خاتمه مییابند تا از یادگیری مسیرهای اشتباه جلوگیری شود.
این فرایند، با ساختار شبکه سبک و قابل اجرا روی سختافزارهای تعبیهشده، نهتنها کارآمد، بلکه آماده برای انتقال به سیستمهای رباتیک واقعی در شرایط بلادرنگ است.
تحلیل عملکرد مدل SAC+PER در سناریوهای آزمایش و مقایسه با روشهای دیگر
پس از آموزش مدل در محیطهای متنوع شبیهسازی، نوبت به ارزیابی دقیق عملکرد آن در سناریوهایی با پیچیدگیهای بالا میرسد — محیطهایی که شامل موانع متحرک، اختلالات مسیر، شروع از حالت تصادفی، و حضور چند مانع همزمان هستند. هدف از این مرحله، بررسی میزان تعمیمپذیری، ایمنی، دقت و پایداری سیاست یادگرفتهشده در مواجهه با شرایط عملیاتی مشابه دنیای واقعی است.
۱. تحلیل رفتار کنترلی ربات پس از یادگیری: تصمیمسازی هوشمند در محیطهای متغیر
پس از طی مرحله آموزش، مدل ترکیبی SAC+PER قادر است سیاستی حرکتی تولید کند که نهتنها به سمت هدف گرایش دارد، بلکه در برابر تغییرات لحظهای محیط و رفتارهای دینامیکی موانع نیز واکنشی تطبیقی، سریع و ایمن نشان میدهد. بازوی رباتیک در مواجهه با موانع متحرک، بدون نیاز به توقف یا اجرای حرکات پرنوسان، مسیر خود را در لحظه تغییر میدهد. مشاهدات رفتاری مدل در اجرای واقعی شامل موارد زیر است:
هنگامی که مانعی با سرعت متوسط از روبرو به ربات نزدیک میشود، مدل بهجای متوقفسازی یا عقبگرد، مفاصل را بهگونهای تنظیم میکند که اندافکتور از سمت امن و بدون نیاز به انحراف شدید، عبور کند.
در زمان ورود ناگهانی مانع، مدل بهجای واکنش اضطرابی یا جهش کنترل، یک انحراف نرم و پیوسته ایجاد کرده و سپس مجدداً به مسیر اصلی بازمیگردد.
در تمام مراحل، حرکت بازو بهشکل پایدار، پیوسته و فاقد نوسان شدید یا توقف ناگهانی صورت میگیرد؛ حتی در محیطهای چندمانعه یا دارای ساختارهای پیچیده هندسی.
این مشاهدات نشان میدهند که مدل نهفقط واکنشپذیر، بلکه پیشبین نیز شده و توانایی تصمیمگیری بلادرنگ را بدون اتکا به مسیرهای از پیشتعریفشده کسب کرده است. چنین ویژگیهایی برای کاربردهای صنعتی بلادرنگ و محیطهای چندعامل ضروریاند.
۲. بررسی سناریوهای آزمایشی متنوع: پایداری رفتار در حضور موانع متحرک
برای ارزیابی عملکرد مدل، نویسندگان چندین سناریو آزمایشی متنوع طراحی کردهاند تا بتوانند سیاست یادگرفتهشده را در مواجهه با شرایط عملیاتی واقعی محک بزنند. در این سناریوها، موقعیت اولیه بازو، موقعیت هدف، و رفتار موانع (از ثابت تا متحرک و نامنظم) تغییر میکند تا میزان تعمیمپذیری مدل سنجیده شود.
در سناریوی اول که شامل یک مانع ثابت و یک مانع متحرک است، بازو در بیش از ۹۷ درصد موارد، بدون برخورد به نقطه هدف رسیده و مسیر حرکت را بهصورت پایدار حفظ کرده است. در سناریوی دوم، با دو مانع متحرک با جهت حرکت متضاد، بازو توانسته با دقت بالا فضای بین آنها را مدیریت کند و در ۹۲ درصد اپیزودها موفق به رسیدن به هدف شده است.
سناریوی سوم شامل حرکت زیگزاگی و نامنظم موانع بوده است. حتی در این وضعیت غیرقابل پیشبینی، مدل رفتار ایمنی از خود نشان داده و با انحراف حداقلی از مسیر اصلی، مسیر امن جایگزین را انتخاب کرده است.
در پیچیدهترین سناریو، مانع بهصورت ناگهانی وارد مسیر ربات در لحظهی پیشروی میشود. برخلاف بسیاری از مدلهای کلاسیک که در چنین شرایطی یا توقف کامل انجام میدهند یا منجر به برخورد میشوند، مدل SAC+PER مسیر حرکتی خود را با کنترل بسیار نرم بازتنظیم کرده و بدون نیاز به توقف، مأموریت را ادامه داده است.
این نتایج نشان میدهند که سیاست یادگرفتهشده از حافظهی تجربی خود برای انطباق رفتاری استفاده میکند؛ نهفقط واکنشگر بلکه پیشبینیگر است.
۳. شاخصهای عددی و تحلیل مقایسهای با سایر روشها
برای مقایسه عملکرد مدل با سایر روشهای رایج در یادگیری تقویتی، چهار شاخص اصلی مورد بررسی قرار گرفتهاند: نرخ موفقیت در رسیدن به هدف، نرخ برخورد با موانع، طول مسیر متوسط تا هدف، و میزان نوسان فرمان کنترلی.
در مقایسه با روشهایی مانند DDPG، TD3 و یک کنترل قاعدهمحور کلاسیک، مدل SAC+PER در تمام این شاخصها عملکرد بهتری ارائه کرده است:
نرخ موفقیت در دستیابی به هدف در مدل SAC+PER بیش از ۹۶ درصد گزارش شده؛ در حالیکه TD3 حدود ۸۸ درصد و DDPG حدود ۸۵ درصد موفقیت داشتهاند. مدل کلاسیک rule-based تنها در حدود ۶۰ درصد اپیزودها به نقطه هدف رسیده است.
نرخ برخورد با موانع در مدل پیشنهادی کمتر از ۲ درصد بوده، در مقایسه با نرخ ۵ تا ۷ درصد در مدلهای RL بدون PER، و نرخ بالای ۲۰ درصد در مدلهای rule-based.
طول مسیر حرکت تا هدف در SAC+PER کوتاهتر و بهینهتر بوده؛ چون مدل اجتناب را با حفظ حرکت کلی بهسوی هدف انجام میدهد، نه با انحراف شدید.
رفتار فرمان کنترلی نیز در مدل SAC+PER روان و فاقد پرش یا نوسان گزارش شده، در حالیکه در DDPG و مدلهای کلاسیک، حرکات لرزشی، تغییر گشتاورهای شدید یا سکون ناگهانی مشاهده شدهاند.
این شاخصها بهخوبی نشان میدهند که ترکیب SAC با PER نهتنها منجر به یادگیری ایمنتر میشود، بلکه کیفیت اجرای مانورها را از نظر زمان، دقت و نرمی نیز بهبود میدهد — عاملی که برای سیستمهای واقعی بسیار حیاتی است.
۴. مقاومت در برابر اختلالات و توانایی پایدارسازی تطبیقی
در محیطهای واقعی، اختلالات جزئی مانند خطا در اندازهگیری سنسور، ورود ناگهانی جسم خارجی، یا تغییر در مکان هدف امری اجتنابناپذیر است. در چنین شرایطی، سیاست کنترلی نباید رفتارهای گسسته یا بحرانی نشان دهد؛ بلکه باید با واکنش نرم، سریع و هدفمند به وضعیت جدید پاسخ دهد.
در آزمایشهای اضافی مقاله، مدل SAC+PER در معرض شرایط اختلالی زیر قرار گرفته است:
تزریق نیروی جانبی تصادفی به بازو در طول مسیر حرکت
تغییر موقعیت هدف در میانه حرکت
حذف موقت دادههای مربوط به موقعیت مانع برای چند مرحله زمانی
در تمامی این سناریوها، مدل توانسته ظرف چند گام، وضعیت جدید را شناسایی کرده و رفتار حرکتی خود را مجدداً تنظیم کند. برخلاف برخی مدلها که دچار توقف کامل یا رفتار نوسانی میشوند، این مدل سیاست خود را بهگونهای تنظیم کرده که بازو مجدداً به وضعیت پایدار بازگردد. این ویژگی نشانه آن است که مدل صرفاً به ورودی لحظهای وابسته نیست، بلکه از ساختار پاداش، حافظه تجربی و سیاست تعمیمیافتهای استفاده میکند که قادر است در برابر ناپایداریها و تغییرات، پایداری عملیاتی خود را حفظ کند.
کاربردهای صنعتی مدل SAC+PER در کنترل هوشمند رباتهای متحرک و بازویی
مدل پیشنهادی مقاله، با تکیه بر دو ستون قدرتمند یعنی کنترل تطبیقی یادگیرنده (SAC) و یادگیری تجربیات اولویتدار (PER)، تنها یک چارچوب تئوریک برای ناوبری بازوهای رباتیک نیست؛ بلکه یک سیستم آماده برای استقرار در محیطهای واقعی، با شرایط عملیاتی دشوار، نااطمینان محیطی و محدودیت پردازشی است. در این بخش، کاربردهای عملی و قابلیتهای توسعه این مدل در حوزههای مختلف صنعت را بررسی میکنیم.
۱. بازوهای رباتیک چنددرجهآزادی در خطوط تولید مدرن
در بسیاری از خطوط تولید پیشرفته، بهویژه در صنایع خودروسازی، تجهیزات الکترونیکی، پزشکی و بستهبندی، بازوهای رباتیک با درجات آزادی بالا بهعنوان مهرههای کلیدی در انجام فرآیندهایی همچون جوشکاری، لحیمکاری، پیچکاری، مونتاژ، و بارگیری قطعات عمل میکنند. این بازوها بهدلیل ساختار چندمفصلی و نیاز به دقت بالا، باید در فضایی محدود، در کنار سایر ماشینآلات و حتی اپراتور انسانی، بهصورت پیوسته و ایمن حرکت کنند.
اما در عمل، محیط خطوط تولید ایستا نیست؛ هر لحظه امکان ورود اپراتور، تغییر مسیر ابزار، یا اختلالات غیرمنتظره وجود دارد. اینجاست که مدل SAC+PER با ساختار یادگیرندهی خود، بهعنوان کنترلکنندهی حرکتی سطح پایین، میتواند کنترلی تطبیقی، بلادرنگ و ایمن را برای این بازوها فراهم کند. با این معماری:
ربات میتواند بهجای حرکت در مسیری از پیش تعریفشده، بر اساس درک آنی از محیط و تجربیات قبلی، مسیر خود را تطبیق دهد.
در صورت نزدیکشدن یک اپراتور یا مانع، بهصورت لحظهای، جهت حرکت مفصلها را تنظیم میکند تا از برخورد جلوگیری شود، بدون نیاز به توقف کلی عملیات یا صدور خطای اضطراری.
همچنین، چون سیاست حرکتی از قبل آموخته شده و درون شبکه عصبی تعبیه شده، نیازی به اجرای الگوریتمهای سنگین در زمان اجرا وجود ندارد — چیزی که برای خطوط تولید با نرخ تولید بالا بسیار حیاتی است.
در نتیجه، این معماری میتواند در خطوطی که به سمت Industry 4.0 حرکت میکنند، رباتهای موجود را از حالت «فرمانپذیر» به «هوشمند تطبیقپذیر» ارتقا دهد؛ بدون نیاز به بازطراحی کامل ساختار سختافزاری یا پیادهسازی سامانه کنترل مرکزی جدید.
۲. سامانههای AGV و AMR در لجستیک داخلی با ناوبری هوشمند
در انبارهای مدرن، بیمارستانها، کارخانهها و مراکز توزیع، سیستمهای حملونقل خودکار مانند AGV (وسایل هدایتشونده خودکار) و AMR (رباتهای موبایل خودمختار) روزبهروز گستردهتر میشوند. این رباتها باید بتوانند در محیطهایی با ترافیک بالا، تداخل انسانی، و تغییر مسیرهای ناگهانی، جابهجایی ایمن و بلادرنگ انجام دهند. مدل SAC+PER بهواسطهی ساختار سیاست یادگیرندهی خود، توانسته بهعنوان هسته تصمیمگیری حرکتی در این پلتفرمها عمل کند. قابلیتهایی که در این زمینه ارزشمند هستند، عبارتاند از:
عدم وابستگی به مسیر از پیش تعیینشده: برخلاف AGVهای کلاسیک که تنها روی نوار مغناطیسی یا مسیر نقشهشده حرکت میکنند، AGV مجهز به SAC+PER میتواند در صورت بستهشدن مسیر، راه جایگزین مناسب را خود انتخاب و اجرا کند.
اجتناب تطبیقی در ترافیک انسانی: در انبارهای باز یا بیمارستانها، AGV ممکن است با بیماران، پرسنل یا سایر رباتها روبهرو شود. مدل ما این امکان را فراهم میکند که بدون توقف کامل، تنها با تنظیم نرم فرمانها، از مانع عبور کند و به مسیر اصلی بازگردد.
سازگاری با پردازندههای سبک onboard: با توجه به اینکه inference تنها نیاز به یک forward pass دارد، اجرای آن روی بردهای تعبیهشده مانند Jetson Nano یا Raspberry Pi عملی است؛ و این ویژگی برای پروژههایی با محدودیت انرژی، وزن و هزینه بسیار کلیدی است.
در چنین سیستمهایی، SAC+PER تبدیل به مغز حرکتی AGV میشود — بدون نیاز به مسیر مرکزی، بدون محاسبه مسیر در هر لحظه، و بدون وابستگی به شبکه یا GPS.
۳. رباتهای همکاریپذیر (Cobots) در فضاهای مشترک انسانی–ماشینی
یکی از جذابترین تحولات رباتیک صنعتی، ورود رباتهای همکاریپذیر یا Cobots به فضاهای مشترک با انسانهاست. برخلاف بازوهای کلاسیک که در محفظههای حفاظدار کار میکردند، Cobots باید در نزدیکی انسان، بدون قفس، و با تعامل بلادرنگ و ایمن عمل کنند. این به آن معناست که کنترلکننده این رباتها باید: توانایی درک سریع رفتار انسان در محیط، پیشبینی حرکت دست یا بدن اپراتور و تنظیم واکنش ایمن، آرام و پیشبینیپذیر را داشته باشد.
مدلی مانند SAC+PER بهدلیل ویژگیهای زیر، برای Cobots ایدهآل است:
سیاست حرکتی تصادفی با آنتروپی بالا: که به ربات اجازه میدهد در شرایط نادقیق یا ناآشنا، رفتار افراطی نداشته باشد.
یادگیری از برخوردهای نادر و تنظیم واکنش نرم: بهجای توقف سختگیرانه در مواجهه با انسان، ربات مسیر خود را بدون شوک تغییر میدهد.
انعطاف در مواجهه با رفتارهای انسانی متنوع: چون در زمان آموزش، مدل در محیطهای مختلف تمرین کرده، میتواند الگوهای حرکتی انسانی را در لحظه تفسیر و درک کند.
در نتیجه، Cobots مجهز به چنین مدلی میتوانند در کاربردهایی مثل مونتاژ مشترک، پیچکاری دستی–رباتی، یا تحویل ابزار به اپراتور نقش فعالی ایفا کنند — بدون ترس از برخورد، ناپایداری یا نیاز به توقف سیستم.
۴. کاربردهای گسترده در صنایع پزشکی، کشاورزی، حملونقل و خدمات عمومی
فراتر از صنایع تولیدی و لجستیک، مزایای ساختاری SAC+PER آن را برای طیف گستردهای از کاربردهای نوظهور نیز مناسب میسازد. بهویژه در حوزههایی که محیطها نیمهساختاریافته یا غیرقابل پیشبینی هستند، رباتها در تماس با انسان یا طبیعت عمل میکنند، واکنش در زمان بسیار کوتاه حیاتی است و منابع پردازشی محدودند. چند نمونه بارز از این کاربردها:
جراحی رباتیک و پزشکی: در رباتهای جراحی، حرکت باید دقیق، بدون نوسان، و مقاوم در برابر ارتعاش یا تغییر ناگهانی شرایط بافت باشد. SAC+PER با یادگیری از رفتارهای موفق جراحی، میتواند تصمیمات ایمنتری نسبت به کنترلهای خطی اتخاذ کند.
رباتهای کشاورزی: در مزارع، رباتها باید میان گیاهان متحرک در باد، موانع ناهموار و موجودات زنده حرکت کنند. مدل SAC+PER با ادراک لحظهای و رفتار انعطافپذیر، گزینهای ایدهآل برای ناوبری در چنین محیطهاییست.
حملونقل خودکار درونسازهای: قایقهای خودران صنعتی، رباتهای انبار درونساختمانی، و خودروهای هدایتشونده در کارخانهها، همگی از مدلهایی با قدرت تصمیمگیری مستقل، سریع و ایمن سود میبرند — ویژگیهایی که SAC+PER بهطور همزمان فراهم میکند.
مزایای تکنیکی مدل SAC+PER نسبت به سایر روشها و مسیر توسعه آینده
در دنیای رباتیک پیشرفته، تصمیمگیری برای انتخاب یک معماری کنترلی هوشمند، وابسته به ارزیابی دقیق و مهندسیشدهی آن در برابر روشهای موجود است. مدل ترکیبی SAC+PER در مقاله حاضر، با رویکردی تلفیقی، توانسته است عملکردی ارائه دهد که از نظر دقت، واکنش بلادرنگ، ایمنی حرکتی و استقلال از مسیرهای از پیش تعیینشده، فراتر از بسیاری از معماریهای کلاسیک یا یادگیرنده عمل میکند. در ادامه، به بررسی مزایای فنی این مدل پرداخته و مسیرهایی برای ارتقاء و توسعهی آن در پروژههای آینده ارائه میکنیم.
الف) مزیت الگوریتمی: ترکیب سیاست تصادفی نرم و یادگیری تجربیات بحرانی
یکی از نقاط قوت کلیدی SAC، تکیه بر سیاستهای تصادفی با آنتروپی بالا است. برخلاف DDPG و TD3 که خروجی قطعی و گاه شکننده دارند، SAC سیاستی تولید میکند که در برابر دادههای نادقیق یا نویز، مقاومت بیشتری دارد. این ویژگی در محیطهای واقعی که دادههای سنسور دچار خطا، تاخیر یا ناپایداری هستند، یک برتری محسوب میشود. از سوی دیگر، استفاده از PER باعث شده فرآیند یادگیری بهجای تصادف، بر اساس اهمیت تجربیات تنظیم شود. این باعث: افزایش نرخ یادگیری در محیطهای پیچیده، تمرکز بر تجربیات برخورد و اجتناب بحرانی و یادگیری سریعتر رفتارهای ایمن میشود. این ترکیب بهگونهای عمل میکند که در مدت زمان کوتاهتری، سیاستی پایدار، متعادل و قابلاتکا یاد گرفته میشود.
ب) مزیت اجرایی: عملکرد بلادرنگ روی سختافزارهای سبک
در بسیاری از پروژههای رباتیکی، از جمله AGVها، AMRها و Cobots، محدودیت در منابع پردازشی یک مانع جدی در پیادهسازی الگوریتمهای یادگیری عمیق است. اما در این مدل:
اجرای سیاست یادگرفتهشده تنها نیازمند یک forward pass سریع در شبکه عصبی سبک است.
این شبکهها روی بردهایی مانند Jetson Nano، Raspberry Pi، یا حتی MCUهای صنعتی قدرتمند قابل اجرا هستند.
در زمان اجرا، نیازی به حل مسئله یا محاسبه مسیر بهینه وجود ندارد؛ تصمیمگیری از حافظهی یادگیری انجام میشود.
این یعنی: مدل میتواند بدون زیرساخت محاسباتی سنگین، در لبه سیستم (edge) اجرا شود — ویژگیای که برای مقیاسپذیری صنعتی حیاتی است.
ج) مزیت رفتاری: پایداری دینامیکی و انعطاف در محیطهای غیرایستا
رفتار یادگرفتهشده توسط این مدل، در مقایسه با کنترلرهای سنتی یا شبکههای بدون حافظه، چند مزیت کیفی دارد:
حرکات نرم، بدون نوسان و قابلاعتماد در مجاورت موانع
اجتناب بدون انحراف افراطی از هدف
بازگشت به مسیر اصلی پس از مانور تطبیقی
توانایی تنظیم بلادرنگ رفتار بدون نیاز به توقف سیستم
این پایداری و انعطاف رفتاری، بهویژه در حضور اپراتور انسانی یا دیگر رباتها، مزیتی تعیینکننده است؛ زیرا مانع از بروز وقفه، برخورد یا رفتارهای غیرمنتظره میشود.
د) مسیر توسعهی آینده: ارتقاء به سیستمهای چندعاملی و یادگیری توزیعشده
اگرچه مقاله تمرکز بر کنترل بازوی رباتیک منفرد دارد، اما همین معماری قابلیت گسترش به موارد زیر را نیز دارد:
کنترل چندرباته (Multi-Robot Coordination): با گسترش فضای حالت و افزودن اطلاعات موقعیتی سایر رباتها، میتوان سیاستهای اجتناب مشارکتی یاد گرفت.
یادگیری انتها–به–انتها (End-to-End): اتصال مستقیم دادههای سنسوری (مثل لیدار یا دوربین) به ورودی شبکه برای حذف لایههای دستی پردازش
یادگیری انتقالپذیر (Transfer Learning): آموزش در محیط شبیهسازی و انتقال رفتار به محیط واقعی بدون نیاز به بازآموزی کامل
یادگیری چندهدفه (Multi-Objective RL): برای تنظیم همزمان اهداف انرژی، ایمنی، دقت و زمان
در پروژههایی با معماری کنترل توزیعشده، این مدل میتواند با ساختار سبک و مستقل خود، در هر عامل رباتیکی بهصورت محلی اجرا شود و با سایر عوامل، تنها در سطح تبادل وضعیت (state-sharing) تعامل کند — بدون نیاز به کنترل مرکزی یا همگامسازی پیچیده.
جمعبندی | از الگوریتم تا اجرا: آیندهی کنترل تطبیقی در رباتهای صنعتی
با گذر از مراحل پیچیده طراحی، آموزش، و ارزیابی مدل یادگیری تقویتی SAC+PER، اکنون میتوان بهصراحت گفت که ما با یکی از کاربردیترین معماریهای کنترلی نسل جدید روبهرو هستیم. مدلی که برخلاف بسیاری از الگوریتمهای تئوریک، نهتنها توانایی اجرا در محیطهای واقعی را دارد، بلکه در حضور موانع متحرک، عدم قطعیت، و محدودیتهای صنعتی، عملکردی پایدار، دقیق و هوشمند از خود نشان میدهد.
از خطوط تولید هوشمند و Cobotهای همکاریپذیر گرفته تا سیستمهای حملونقل خودکار و رباتهای پزشکی، مدل SAC+PER میتواند بهعنوان هستهی تصمیمساز حرکتی، نقش تعیینکنندهای در افزایش ایمنی، کاهش توقف، و ارتقاء کیفیت تعامل انسان–ماشین ایفا کند.
ترکیب سیاستهای تصادفی مقاوم (SAC) با یادگیری اولویتمحور تجربیات بحرانی (PER)، نهتنها باعث افزایش سرعت و دقت یادگیری شده، بلکه مسیر توسعه به سوی کنترلهای چندعاملی و تطبیقی در پروژههای صنعتی آینده را نیز هموار میسازد.
چگونه این مدل را در پروژههای صنعتی واقعی پیادهسازی کنیم؟
ما در برند شما (یا تیم توسعه صنعتیتان)، آمادهایم تا:
این معماری را روی پلتفرمهای سختافزاری شما پیادهسازی و بهینهسازی کنیم
آموزش مدل را برای رباتهای خاص خط تولید شما در محیطهای شبیهسازیشده انجام دهیم
آن را روی بردهای صنعتی سبک یا GPUهای edge مثل Jetson Xavier پیاده کنیم
و در کنار تیم شما، مسیر استقرار آن در سیستمهای رباتیکی واقعی را طراحی و اجرا کنیم
اگر پروژهی شما نیازمند کنترل حرکتی هوشمند، انعطافپذیر، مقاوم در برابر موانع، و قابل پیادهسازی در زمان بلادرنگ است — ما آمادهایم تا این مسیر را با شما طی کنیم.
{kind=link}
بدون نظر