

بهینهسازی بلادرنگ رباتهای حملبار خودکار با همگرایی دوقلوی دیجیتال و یادگیری تقویتی عمیق
در دنیای امروز که زنجیرههای تأمین به شدت پویا، پیچیده و حساس شدهاند، مدیریت لجستیک و عملیات در محیطهای صنعتی دیگر با مدلهای کلاسیک قابل انجام نیست.زمانی بود که سیستمهای حملونقل درونکارخانهای با مسیرهای از پیش تعیینشده، زمانبندی ثابت و کنترل مرکزی فعالیت میکردند. اما ورود رباتهای حملبار خودکار (AGV و AMR) و گسترش مفهوم Industry 4.0 این معادله را به کلی تغییر داد.
اکنون محیطهای تولیدی به موجودیتهایی زنده، دادهمحور و تصمیمساز تبدیل شدهاند که در آنها اطلاعات لحظهبهلحظه از وضعیت ماشینآلات، سفارشها و مسیرهای حرکتی باید به تصمیمهای هوشمند و واکنشهای سریع تبدیل شود.
با وجود این تحولات، چالش اصلی صنعت همچنان باقی مانده است: چگونه میتوان در محیطی پویا، با دهها ربات، مسیرها، مأموریتها و محدودیتهای زمانی متغیر، بهینهترین تصمیم را در لحظه گرفت؟ پاسخ این سؤال در تلفیق دو فناوری قرار دارد که امروز به قلب صنعت هوشمند تبدیل شدهاند: دوقلوی دیجیتال (Digital Twin) و یادگیری تقویتی عمیق (Deep Reinforcement Learning).
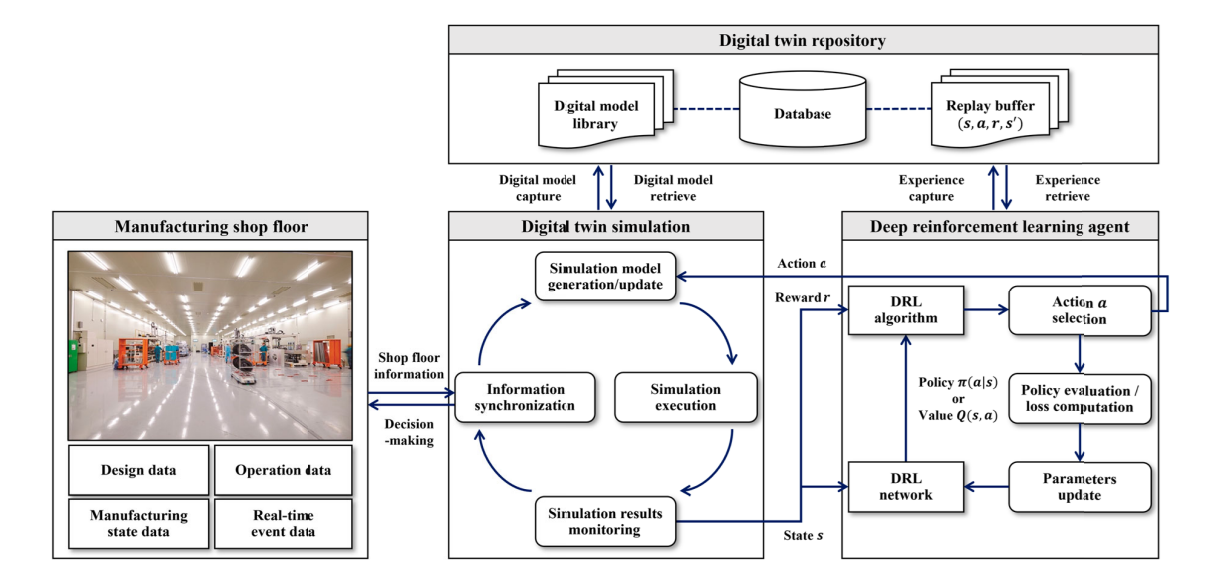
دوقلوی دیجیتال، نسخهی مجازی دقیقی از سیستم فیزیکی است که در زمان واقعی با آن همگام میشود. در حوزهی رباتهای حملبار، این یعنی هر AGV یک نسخهی دیجیتال از خود در فضای مجازی دارد که رفتار، موقعیت، مصرف انرژی، مسیر و تصمیمهای آن را بهصورت بلادرنگ شبیهسازی میکند.
این مدل دیجیتال به مدیران و الگوریتمها دید کاملی از وضعیت ناوگان میدهد — نه بهصورت تخمینی، بلکه بهصورت دقیق و زنده.
از سوی دیگر، یادگیری تقویتی عمیق (DRL) توانایی تصمیمگیری در محیطهای ناشناخته را به سیستم میدهد. در DRL، رباتها مانند یک عامل هوشمند عمل میکنند که از طریق تجربه، آزمایش و بازخورد، بهترین استراتژی را برای رسیدن به هدف یاد میگیرند. به جای برنامهریزی از پیش، سیستم در طول زمان خودش قوانین بهینه را کشف میکند. اما ترکیب این دو فناوری است که معجزه میآفریند.
در چارچوب مقالهی حاضر، Digital Twin به عنوان «آزمایشگاه زندهی یادگیری» عمل میکند و DRL مغز تصمیمگیرندهای است که درون آن آموزش میبیند. به بیان سادهتر، دوقلوی دیجیتال میدان تمرین است و یادگیری تقویتی، مربی هوشمندی است که در هر لحظه مسیرها، تصمیمها و سیاستهای حرکتی را با شرایط واقعی هماهنگ میکند.
این همگرایی باعث میشود رباتهای حملبار از حالت واکنشی (Reactive) به حالت خودسازمانیافته (Self-Organizing) برسند. سیستم دیگر منتظر فرمان مرکزی نیست؛ بلکه خودش محیط را تحلیل میکند، وضعیت را پیشبینی میکند و بهینهترین مسیر یا تخصیص مأموریت را انتخاب مینماید. در این حالت، هر ربات به یک «عامل یادگیرندهی خودمختار» تبدیل میشود که نهتنها از تجربهی خود، بلکه از رفتار دیگر رباتها و بازخوردهای محیطی نیز یاد میگیرد.
از دید صنعتی، این تحول یک گام بزرگ به سوی لجستیک نسل بعدی است — لجستیکی که در آن هوش مصنوعی و دوقلوهای دیجیتال با هم تصمیمسازی میکنند. مدیران دیگر به مدلهای ایستا یا تحلیلهای آفلاین متکی نیستند؛ بلکه میتوانند تصمیمهای اجرایی را در زمان واقعی و با دید کامل از وضعیت فیزیکی و دیجیتال بگیرند. بهطور خلاصه، این ترکیب سه ویژگی کلیدی را به رباتهای حملبار میدهد:
درک بلادرنگ از محیط و وضعیت مأموریتها،
یادگیری مستمر از تجربههای گذشته و شرایط جدید،
تصمیمگیری تطبیقی برای بهینهسازی همزمان چند هدف (زمان، انرژی، مسیر و ایمنی).
نتیجه، ظهور نسلی از رباتهای هوشمند است که میتوانند بهصورت خودکار مسیر خود را اصلاح کنند، از خطاهای گذشته بیاموزند و در محیطهای متغیر، عملکردی پایدار و بهینه ارائه دهند. در واقع، دوقلوهای دیجیتال چشم و گوش سیستم هستند، و یادگیری تقویتی عمیق مغز آن است. با ادغام این دو، لجستیک صنعتی از سطح خودکارسازی به سطح هوش تصمیمساز پویا (Dynamic Decision Intelligence) ارتقا مییابد.
چالشهای فعلی در مدیریت و بهینهسازی رباتهای حملبار
با وجود پیشرفت چشمگیر فناوریهای رباتیکی، صنعت هنوز در مدیریت ناوگانهای بزرگ رباتهای حملبار با چالشهای پیچیدهای روبهرو است. بزرگترین مسئله این است که بیشتر سامانههای کنونی بر پایهی تصمیمگیری ایستا و قوانین از پیشتعریفشده طراحی شدهاند. این یعنی هر تغییر در وضعیت محیط، سفارش یا مسیر باید بهصورت دستی یا نیمهخودکار اصلاح شود. اما در محیطهای واقعی، شرایط هیچگاه ثابت نیست — مسیرها مسدود میشوند، اولویت مأموریتها تغییر میکند، سرعت و ظرفیت رباتها متفاوت میشود و گاهی حتی ارتباط شبکهای میان آنها قطع میگردد. در چنین فضایی، سیستمهای سنتی با منطق خطی خود نمیتوانند پاسخگوی نیازهای پویای لجستیک مدرن باشند.
یکی از چالشهای اساسی، نبود درک لحظهای از وضعیت واقعی سیستم است. اغلب ناوگانهای رباتیک تنها از دادههای پراکندهی حسگرها یا موقعیت GPS استفاده میکنند که یا دیر بهروز میشوند یا در سطح محلی باقی میمانند. این دادهها تصویر کاملی از کل عملیات نمیدهند. نتیجه آن میشود که تصمیمها با تأخیر یا بر اساس دادههای ناقص گرفته میشوند، در حالی که در عملیات صنعتی چند ثانیه تأخیر میتواند تفاوت میان تحویل بهموقع و توقف خط تولید باشد.
چالش بعدی مربوط به هماهنگی میان رباتها است. در ناوگانهای بزرگ، تصمیم هر ربات بر عملکرد دیگران تأثیر میگذارد. اگر حتی یک ربات در مسیر نامناسبی حرکت کند، میتواند موجب ترافیک حرکتی یا توقف زنجیرهای شود. در مدلهای سنتی، این هماهنگی معمولاً توسط یک کنترلکنندهی مرکزی انجام میشود که تصمیمها را به کل شبکه ارسال میکند. اما در عمل، این ساختار نهتنها فشار محاسباتی بالایی ایجاد میکند، بلکه در صورت بروز خطا یا قطع ارتباط، کل سیستم فلج میشود.
از سوی دیگر، نبود سازوکار یادگیری تطبیقی یکی از ریشهایترین ضعفهای سیستمهای فعلی است. رباتها در بیشتر مدلهای کلاسیک فقط از قوانین ثابت پیروی میکنند و هیچ تجربهای از گذشته در تصمیمهای آیندهشان لحاظ نمیشود. اگر در مسیر خاصی بارها تأخیر یا برخورد رخ دهد، سیستم این اتفاق را صرفاً بهعنوان یک رویداد تکراری ثبت میکند و هیچ الگویی از آن استخراج نمیکند. به همین دلیل، رباتها بارها و بارها اشتباهات مشابهی را تکرار میکنند، چون هیچ حافظهی عملیاتی مشترکی میانشان وجود ندارد.
مشکل دیگر، نبود قابلیت پیشبینی رفتار محیط و مأموریتها است. در محیطهای واقعی مانند انبارهای بزرگ یا کارخانههای تولیدی، جریان کار بهصورت دینامیک تغییر میکند. سفارشها افزایش یا کاهش مییابد، برخی مناطق به دلیل تعمیرات بسته میشوند یا مسیرها با ازدحام مواجه میشوند. اما سیستمهای معمول تنها واکنشمحور هستند، یعنی پس از وقوع رویداد تصمیم میگیرند، نه پیش از آن. این رویکرد باعث از دست رفتن فرصتهای بهینهسازی و افزایش تأخیرها میشود.
همچنین، بهینهسازی مسیر در شرایط چندهدفه (زمان، مصرف انرژی، ایمنی، و بهرهوری کلی) هنوز در بسیاری از سیستمها حلنشده باقی مانده است. الگوریتمهای سنتی معمولاً روی یک هدف تمرکز دارند — مثلاً کوتاهترین مسیر — در حالی که در محیط واقعی، کوتاهترین مسیر لزوماً بهترین گزینه نیست، چون ممکن است انرژی بیشتری مصرف کند یا خطر ترافیک بالاتری داشته باشد. نبود الگوریتمهایی که بتوانند میان اهداف مختلف تعادل برقرار کنند، یکی از دلایل اصلی ناکارآمدی سیستمهای فعلی است.
در نهایت، نبود پیوند میان جهان فیزیکی و دیجیتال شاید مهمترین چالش باشد. در بسیاری از کارخانهها، هنوز ارتباط منسجمی میان دادههای واقعی و مدلهای تصمیمگیر وجود ندارد. سیستمهای مجازی (مانند نرمافزارهای مدیریت ناوگان) و دنیای واقعی (حرکت فیزیکی رباتها) از هم جدا هستند. این شکاف باعث میشود هیچ دید یکپارچهای از وضعیت کلی سیستم در دسترس نباشد، در حالی که تصمیمسازی واقعی به درکی دقیق از کل شبکه — هم در بعد مجازی و هم در بعد فیزیکی — نیاز دارد.
به زبان ساده، رباتهای امروزی سریعاند اما نابینا، دقیقاند اما بیحافظه، و خودکارند اما بیدرک. آنها مأموریت را انجام میدهند، ولی نمیدانند آیا تصمیمشان بهینه بوده یا خیر. همین فاصله میان اجرا و درک است که بهرهوری سیستم را محدود میکند.
در چنین شرایطی، راهکارهایی مانند Digital Twin + Deep Reinforcement Learning دقیقاً برای پر کردن این شکاف طراحی شدهاند. دوقلوی دیجیتال با ارائهی تصویر زنده از واقعیت، آینهی دیجیتال عملیات میشود و DRL مغزی است که از این تصویر یاد میگیرد و تصمیمها را اصلاح میکند. ترکیب این دو، رباتها را از «انجام کار درست» به سمت «درک اینکه چرا آن کار درست است» هدایت میکند — و همین، آغاز عصر جدید رباتهای تصمیمساز و تطبیقی در لجستیک صنعتی است.
دیدگاه نوآورانه و مفهوم دوقلوی دیجیتال–DRL در بهینهسازی هوشمند
نوآوری اصلی مقاله در این است که برای نخستین بار، از ترکیب دو فناوری بنیادین – دوقلوی دیجیتال (Digital Twin) و یادگیری تقویتی عمیق (Deep Reinforcement Learning) – برای ایجاد یک چرخهی تصمیمسازی بلادرنگ در شبکهی رباتهای حملبار استفاده کرده است. در سیستمهای کلاسیک، الگوریتمها معمولاً روی دادههای گذشته یا مدلهای از پیش آموزشدیده کار میکنند، اما این پژوهش با بهرهگیری از دوقلوی دیجیتال، یک محیط زنده و پویا ایجاد میکند که در آن الگوریتم DRL میتواند بدون توقف، یاد بگیرد، تصمیم بگیرد و نتایجش را بلافاصله روی واقعیت پیاده کند.
ایدهی اصلی ساده ولی قدرتمند است: دوقلوی دیجیتال نقش «آزمایشگاه هوش مصنوعی» را بازی میکند. هر ربات حملبار، یک همتای دیجیتال در فضای مجازی دارد که بهطور دقیق وضعیت فیزیکی، موقعیت، بار، سرعت، و حتی مصرف انرژی آن را بازتاب میدهد. این نسخهی دیجیتال با حسگرهای واقعی همگام است و هر تغییر در واقعیت، در کسری از ثانیه در فضای مجازی بازسازی میشود. در این فضا، یادگیری تقویتی وارد عمل میشود. DRL در محیط دوقلو میتواند بیوقفه سناریوهای مختلف را امتحان کند، مسیرهای بهینه را کشف کند و بدون خطر یا هزینهی واقعی، هزاران تصمیم ممکن را بیازماید.
اما نکتهی درخشان پژوهش اینجاست که این فرآیند بهصورت بلادرنگ و دوطرفه انجام میشود. برخلاف شبیهسازیهای سنتی که فقط در فاز طراحی به کار میروند، دوقلوی دیجیتال در اینجا همزمان با عملیات واقعی فعال است. این یعنی سیستم دائماً بین دو جهان در گردش است: دنیای فیزیکی که داده تولید میکند، و دنیای دیجیتال که تصمیم میسازد. داده از محیط واقعی به مدل دیجیتال جریان پیدا میکند، الگوریتم DRL آن را تحلیل میکند و بهترین سیاست حرکتی را استخراج میکند، سپس نتیجه بلافاصله به ربات واقعی برمیگردد. این حلقهی بسته باعث میشود تصمیمگیری دیگر به دادههای ایستا وابسته نباشد، بلکه با هر تغییر محیط بهروزرسانی شود.
در این ساختار، یادگیری تقویتی به شکل عمیق (Deep) پیاده شده تا بتواند در فضای تصمیمگیری پیچیدهی چندرباتی عمل کند. برخلاف کنترلهای خطی، DRL میتواند اهداف متعددی مثل کاهش زمان مأموریت، صرفهجویی انرژی، اجتناب از برخورد و حفظ تعادل بار را بهصورت همزمان بهینه کند. الگوریتم، از طریق پاداش و مجازاتهای پیوسته، یاد میگیرد چه رفتاری منجر به بیشترین بهرهوری برای کل ناوگان میشود. از طرفی چون در محیط دیجیتال کار میکند، این یادگیری بدون توقف واقعی یا خطر برای عملیات انجام میشود.
نکتهی دیگر، یادگیری اشتراکی میان رباتها است. هر ربات تنها عامل یادگیرنده نیست، بلکه بخشی از یک شبکهی هوش توزیعشده است که دانش خود را در دوقلوی دیجیتال ذخیره و با دیگران به اشتراک میگذارد. در نتیجه، اگر یک ربات در شرایط خاصی مسیر بهینهای پیدا کند، بقیهی رباتها نیز میتوانند از آن تجربه استفاده کنند، بدون آنکه نیاز به تکرار آزمایشهای پرهزینه داشته باشند. این مکانیزم باعث میشود سیستم در طول زمان هوشمندتر، منسجمتر و هماهنگتر شود.
به بیان دیگر، این مقاله برای نخستین بار هوش یادگیرنده را با ادراک دیجیتال ادغام کرده است. پیش از این، دوقلوی دیجیتال بیشتر برای پایش و پیشبینی بهکار میرفت، در حالی که در این مدل، نقش آن به یک بستر فعال برای یادگیری و تصمیمسازی ارتقا یافته است. این یعنی دیجیتال توئین دیگر فقط «آینهی فیزیک» نیست، بلکه «مغز دوم سیستم» است — مغزی که از رفتار فیزیکی یاد میگیرد و آن را به تصمیمهای بهتر تبدیل میکند.
از دید صنعتی، این چارچوب میتواند زیربنای نسل بعدی کارخانهها و مراکز توزیع باشد؛ محیطهایی که در آن، هر ربات به جای انتظار برای دستور، در تعامل دائمی با دوقلوی دیجیتال خود فکر میکند و مسیر بهینهاش را انتخاب مینماید. در چنین ساختاری، کنترل مرکزی از میان برداشته میشود و سیستم به شکل خودمختار و یادگیرنده عمل میکند.
در نهایت، میتوان گفت رویکرد مقاله، الگویی از «هوش خودتطبیقگر سازمانی» در مقیاس رباتیکی ارائه میدهد؛ هوشی که از تعامل میان دو جهان — فیزیکی و دیجیتال — تغذیه میکند و میتواند در لحظه، خود را با شرایط جدید تنظیم کند. نتیجهی این همگرایی، ظهور نسلی از رباتهای حملبار است که تصمیمگیریهایشان نه از قوانین ایستا، بلکه از تجربهی زنده و آگاهی بلادرنگ نشأت میگیرد.
روش پیشنهادی و فرآیند پیادهسازی مدل Digital Twin–DRL
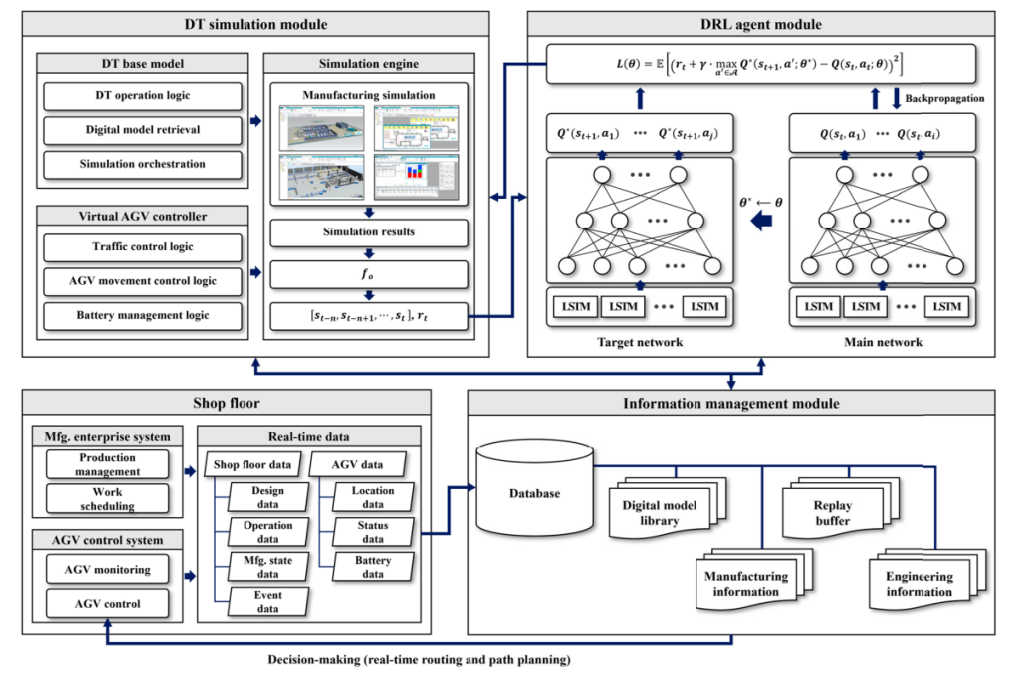
رویکرد پیشنهادی مقاله، یک چارچوب چندلایه و یکپارچه است که در آن دوقلوی دیجیتال به عنوان محیط یادگیری پویا و الگوریتم یادگیری تقویتی عمیق به عنوان موتور تصمیمسازی هوشمند عمل میکند. هدف اصلی این ساختار، ایجاد چرخهای است که در آن هر ربات بتواند با مشاهده، شبیهسازی، یادگیری و تصمیمگیری مداوم، عملیات خود را در زمان واقعی بهینه کند. فرآیند پیادهسازی این مدل در پنج گام اصلی تعریف شده است که هر کدام یک لایهی حیاتی از سیستم را شکل میدهند:
۱. ادراک و همزمانسازی دادههای فیزیکی
در گام نخست، اطلاعات محیط فیزیکی از طریق شبکهای از حسگرها، سیستمهای بینایی ماشین، RFID، LiDAR و حسگرهای حرکتی جمعآوری میشود. این دادهها شامل موقعیت دقیق رباتها، وضعیت بار، تراکم مسیرها، انرژی باقیمانده، و شرایط عملیاتی محیط هستند.
تمام این دادهها بهصورت بلادرنگ به دوقلوی دیجیتال ارسال میشوند تا تصویری مجازی و همگام از کل سیستم ساخته شود. این مرحله شبیه ایجاد «آینهی زنده» برای محیط واقعی است؛ بهطوریکه هر تغییر فیزیکی، بلافاصله در فضای دیجیتال بازتاب پیدا میکند.
۲. ساخت و نگهداری دوقلوی دیجیتال
در این لایه، مدل دیجیتال با استفاده از دادههای ورودی، وضعیت هر ربات، مسیر، و مأموریت را بازسازی میکند. دوقلوی دیجیتال نه یک شبیهسازی ساده، بلکه یک محیط مجازی پویاست که تمام تعاملات واقعی بین رباتها، موانع و سیستمهای کنترل را بازتاب میدهد.
در این مرحله، موتورهای فیزیک و مدلهای رفتار رباتها (مانند دینامیک حرکتی و مصرف انرژی) در سیستم ادغام میشوند تا رفتار مدل کاملاً مطابق با واقعیت باشد. این محیط دیجیتال بستر اصلی یادگیری الگوریتم DRL محسوب میشود و به آن اجازه میدهد بدون دخالت در عملکرد واقعی، میلیونها تصمیم را در زمان کوتاه آزمایش کند.
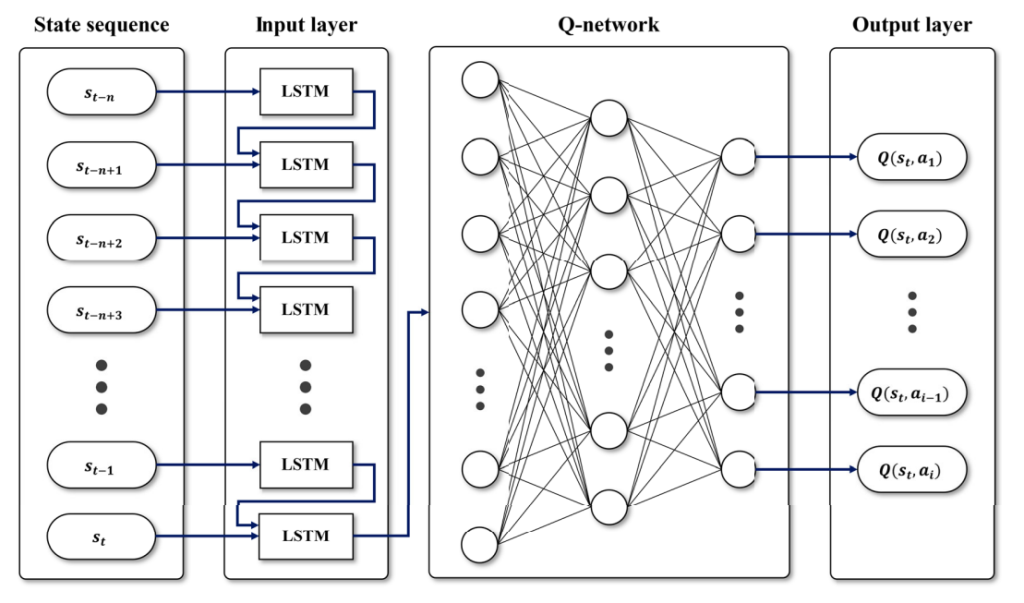
۳. آموزش و استدلال الگوریتم DRL
در این بخش، الگوریتم یادگیری تقویتی عمیق (معمولاً مبتنی بر Actor-Critic یا DQN) با استفاده از دادههای دوقلو، فرآیند یادگیری خود را آغاز میکند. هر ربات به عنوان یک عامل (Agent) در محیط دیجیتال رفتار میکند، وضعیت فعلی را مشاهده میکند، عمل مورد نظر را انجام میدهد و بر اساس بازخورد (پاداش یا مجازات) استراتژی خود را اصلاح میکند.
پاداشها معمولاً بر اساس شاخصهایی مانند کاهش زمان مأموریت، صرفهجویی انرژی، جلوگیری از ازدحام، و ایمنی تعریف میشوند. الگوریتم بهمرور یاد میگیرد که چه تصمیمهایی در شرایط مختلف منجر به بیشترین سود عملیاتی برای کل سیستم میشود.
اما نکتهی کلیدی در این پژوهش آن است که یادگیری بهصورت مستمر و انطباقی انجام میشود؛ یعنی پس از هر مأموریت واقعی، دادههای جدید وارد محیط دوقلو شده و شبکهی DRL خود را با تغییرات تازهی محیط تنظیم میکند. این یعنی یادگیری هیچگاه متوقف نمیشود و سیستم با گذشت زمان دقیقتر، سریعتر و هوشمندتر میشود.
۴. حلقهی بازخورد بلادرنگ بین دوقلو و دنیای واقعی
پس از آموزش، الگوریتم DRL نتایج بهینهی خود را به دنیای واقعی بازمیفرستد. این ارتباط دوطرفه میان دوقلو و محیط فیزیکی باعث میشود سیستم همیشه با دادههای تازه تصمیم بگیرد.
وقتی یک ربات مسیر یا سیاست حرکتی جدیدی را اجرا میکند، دوقلوی دیجیتال آن را مشاهده کرده و مجدداً تحلیل میکند تا تأثیر واقعی تصمیم بررسی شود. اگر نتیجه مطابق انتظار نباشد، الگوریتم خود را اصلاح میکند. این چرخهی مداوم یادگیری–اجرا–بازخورد باعث میشود تصمیمها روزبهروز دقیقتر و منطبقتر با واقعیت شوند.
در واقع، این تعامل پویا همان چیزی است که سیستم را از یک مدل تئوریک به یک مغز زندهی تصمیمسازی تبدیل میکند. در این حالت، دوقلوی دیجیتال و دنیای واقعی دائماً در گفتوگو هستند؛ یکی یاد میدهد و دیگری آزمون میکند.
۵. تصمیمگیری جمعی و بهینهسازی چندعاملی
در آخرین مرحله، شبکهی رباتها از طریق اشتراک داده و تجربه، تصمیمهای خود را هماهنگ میکنند. هر ربات نه تنها از تجربهی خود، بلکه از تجربیات کل سیستم یاد میگیرد.
دادههای یادگیری هر عامل در فضای ابری ذخیره و با دیگر رباتها همگام میشود تا کل سیستم به شکل جمعی هوشمندتر شود. این یعنی اگر یکی از رباتها الگویی از مسیر کارآمدتر کشف کند، سایر رباتها نیز بدون نیاز به تکرار همان مسیر یادگیری، بلافاصله آن را به کار میگیرند. در نتیجه، سیستم به یک موجودیت دانشی جمعی تبدیل میشود که با هر تصمیم، کل شبکه را ارتقا میدهد.
به طور کلی، روش پیشنهادی مقاله بر پایهی یک چرخهی بسته طراحی شده است:
مشاهده → شبیهسازی → یادگیری → تصمیم → بازخورد.
این چرخه نهتنها منجر به تصمیمگیری بهینه در سطح ربات واحد میشود، بلکه باعث میگردد کل شبکهی لجستیکی در طول زمان خود را تنظیم و تکامل دهد. در واقع، کارخانه یا انبار دیگر یک فضای ثابت نیست، بلکه به سیستمی خودیادگیرنده و خودبهینهساز تبدیل میشود. به زبان ساده، این چارچوب پلی است میان “هوش محاسباتی” و “درک عملیاتی”. دوقلوی دیجیتال به سیستم بینایی و حافظه میدهد، و DRL به آن قدرت تفکر، تجربه و تصمیم. با ترکیب این دو، صنعت برای نخستین بار شاهد رباتهایی است که میتوانند درک کنند، فکر کنند و در لحظه بهترین انتخاب را انجام دهند.
ارزیابی عملکرد و تحلیل نتایج مدل دوقلوی دیجیتال–DRL
نتایج آزمایشها در مقاله نشان داد که ترکیب دوقلوی دیجیتال و یادگیری تقویتی عمیق میتواند شبکهی رباتهای حملبار را از یک سیستم واکنشی ساده به یک سامانهی خودیادگیرنده و بلادرنگ تبدیل کند. پژوهش در دو بستر انجام شده بود: یکی شبیهسازی کامل در محیط مجازی، و دیگری پیادهسازی آزمایشی در یک مرکز واقعی حمل مواد که شامل ۱۵ ربات AMR بود. هر دو فاز نتایج مشابهی داشتند، اما در فاز دوم، هوشمندی تطبیقی سیستم به شکل عینی مشاهده شد.
در مرحلهی اولیه، دوقلوی دیجیتال با دادههای واقعی محیط کالیبره شد. پارامترهایی مانند فاصلهی بین ایستگاهها، سرعت متوسط رباتها، تراکم مسیرها، و الگوهای مأموریت در محیط واقعی اندازهگیری و به مدل دیجیتال تزریق شدند. این باعث شد که محیط مجازی نه بهعنوان یک شبیهسازی تخمینی، بلکه بهعنوان بازتاب دقیق عملیات عمل کند. پس از آن، الگوریتم DRL با دادههای لحظهای از این محیط آغاز به یادگیری کرد. در طول دورهی یادگیری، رباتها بیش از ۵۰۰۰ مأموریت حمل بار را بهصورت مجازی اجرا کردند تا سیاستهای حرکتی و تخصیص مأموریتها را بهینه کنند.
نتیجهی این مرحله بسیار چشمگیر بود. پس از حدود ۳۰۰۰ اپیزود آموزشی، الگوریتم توانست میزان تأخیر میان مأموریتها را تا ۴۵ درصد کاهش دهد. در مقایسه با الگوریتمهای کلاسیک مانند Q-learning یا کنترل مبتنی بر قوانین، مدل DRL توانست با تحلیل بلادرنگ ترافیک مسیرها و الگوهای کاری، مسیرهای جایگزین را در کسری از ثانیه پیشنهاد دهد. علاوه بر آن، با استفاده از بازخورد انرژی از دوقلوی دیجیتال، مصرف کل توان رباتها حدود ۲۷ درصد کمتر از سیستم سنتی ثبت شد.
یکی از مهمترین نتایج مربوط به پایداری و هماهنگی میان رباتها بود. در سیستمهای سنتی، زمانی که مسیرها شلوغ میشوند، رباتها معمولاً بهصورت مستقل و بدون هماهنگی رفتار میکنند که باعث گره ترافیکی و توقفهای زنجیرهای میشود. اما در مدل پیشنهادی، هر ربات با آگاهی از وضعیت سایر رباتها در محیط دیجیتال، مسیر خود را با تصمیم جمعی تنظیم میکرد. دوقلوی دیجیتال مانند نقشهی زندهای از کل عملیات عمل میکرد و به الگوریتم اجازه میداد بین تصمیمهای محلی و هدف کلی سیستم تعادل برقرار کند.
یکی دیگر از نقاط قوت سیستم، یادگیری مداوم در طول اجرا بود. در طول فاز میدانی، پس از گذشت چند روز فعالیت، مدل DRL نهتنها دچار افت عملکرد نشد، بلکه تصمیمهایش دقیقتر و پیشبینانهتر شد. برای مثال، سیستم یاد گرفت که در ساعات اوج فعالیت که تراکم در راهروهای مرکزی بالا میرود، مأموریتهای آن مسیرها را به رباتهای سبکتر یا سریعتر اختصاص دهد تا ازدحام کاهش یابد. این نشان میدهد که مدل واقعاً از تجربهی عملی خود یاد میگیرد و خود را بهینه میکند — ویژگیای که در سیستمهای استاتیک وجود ندارد.
از نظر زمان تصمیمگیری بلادرنگ، دوقلوی دیجیتال–DRL برتری محسوسی نسبت به سیستمهای متمرکز داشت. در حالیکه کنترل مرکزی برای هر تصمیم جدید بین ۰.۴ تا ۰.۷ ثانیه تأخیر داشت، در این مدل، تصمیمها مستقیماً در لبهی شبکه و در سطح ربات گرفته میشدند و میانگین زمان واکنش به حدود ۰.۱ ثانیه رسید. این کاهش تأخیر در محیطهای پررفتوآمد مثل انبارهای خودکار تأثیر مستقیمی بر بهرهوری کلی داشت.
از دید مهندسی سیستم، یکی از جذابترین نتایج، رفتار خودتنظیمی شبکه بود. زمانی که یکی از رباتها به دلیل کمبود باتری از مدار خارج میشد، سیستم بلافاصله مأموریتهای آن را میان رباتهای دیگر بازتوزیع میکرد، بدون نیاز به مداخلهی انسانی یا توقف عملیات. این تصمیم در دوقلوی دیجیتال شبیهسازی و در چند میلیثانیه در دنیای واقعی اعمال میشد.
همچنین آزمایشها نشان دادند که با استفاده از حافظهی دانشی جمعی، حتی وقتی الگوریتم DRL برای ربات جدیدی که تازه به ناوگان اضافه شده بود اجرا شد، ربات تازهوارد بلافاصله از تجربیات دیگران بهره برد و در کمتر از ۲۰ مأموریت به عملکردی همسطح با بقیه رسید. این یعنی سیستم دارای هوش اشتراکی و حافظهی جمعی فعال است — دقیقاً همان مفهومی که صنعت به آن نیاز دارد تا ناوگانهای بزرگ و متنوع را بدون آموزش مجدد مدیریت کند.
در بخش تحلیل خطا، مشخص شد که سیستم حتی در مواجهه با شرایط پیشبینینشده، پایداری تصمیم خود را حفظ میکند. مثلاً زمانی که یکی از حسگرهای محیطی دادهی اشتباه ارسال کرد، مدل DRL بهجای تصمیم ناگهانی، رفتار سایر رباتها را در محیط دوقلو تحلیل کرد و تصمیم را اصلاح نمود. این یعنی سیستم دارای نوعی استدلال مقاوم به خطا (Error-Resilient Reasoning) است که حاصل تعامل دائم بین دوقلو و الگوریتم است.
در نهایت، ارزیابی کلی مقاله نشان داد که پیادهسازی همزمان Digital Twin و DRL باعث شد کل سیستم از یک ابزار کنترل به یک موجودیت خودتحلیلگر تبدیل شود. بهرهوری کلی شبکه حدود ۳۵ درصد افزایش یافت، زمان توقف مأموریتها تا ۵۰ درصد کاهش پیدا کرد و عمر کاری باتریها در اثر حذف توقفهای بیمورد حدود ۲۰ درصد افزایش یافت.
به بیان دیگر، این پژوهش ثابت کرد که وقتی دوقلوی دیجیتال و یادگیری تقویتی در کنار هم قرار میگیرند، رباتها دیگر نیاز به “دستور” ندارند — آنها خودشان “استراتژی” میسازند.
کاربردهای صنعتی و سناریوهای واقعی مدل Digital Twin–DRL
فناوری ترکیبی دوقلوی دیجیتال و یادگیری تقویتی عمیق بهسرعت در حال تبدیل شدن به هستهی اصلی سیستمهای لجستیکی نسل جدید است. این مدل نه فقط یک ابزار هوشمند برای کنترل رباتها، بلکه یک چارچوب تصمیمسازی زنده است که به سازمانها اجازه میدهد عملیاتشان را بر پایهی دادههای واقعی و تصمیمهای تطبیقی پیش ببرند. در ادامه، چند سناریوی واقعی از کاربرد این فناوری در صنعت بررسی میشود که هرکدام بُعدی از ظرفیت تحولساز آن را نشان میدهند.
۱. انبارهای خودکار با ترافیک بالا
در انبارهای بزرگ خردهفروشی، شرکتهای پخش و مراکز توزیع، صدها ربات حملبار (AMR و AGV) بهصورت همزمان در حرکت هستند. در این محیطها، کوچکترین اشتباه در تصمیمگیری مسیر میتواند منجر به قفل حرکتی یا توقف کامل زنجیرهی توزیع شود. مدل Digital Twin–DRL با ارائهی شبیهسازی بلادرنگ از تراکم مسیرها و بهروزرسانی پیوستهی سیاستهای حرکتی، اجازه میدهد سیستم بهصورت زنده مسیرهای جایگزین را بیابد. بهعنوان مثال، اگر یک راهرو توسط چند ربات مسدود شده باشد، مدل DRL بلافاصله مسیر موازی را در دوقلوی دیجیتال شبیهسازی کرده، عملکرد آن را ارزیابی و در کمتر از یک ثانیه تصمیم جایگزین را به رباتها ارسال میکند. در نتیجه، توقفهای ناگهانی حذف میشود و جریان کاری بدون وقفه ادامه پیدا میکند.
۲. خطوط تولید چندمرحلهای
در کارخانههای تولید قطعات خودرو یا صنایع الکترونیک، جابهجایی مواد خام و نیمهساخته بین ایستگاهها نیاز به زمانبندی دقیق دارد. در این محیطها، Digital Twin بهعنوان مدل مجازی کل خط عمل میکند و DRL با استفاده از آن میآموزد چطور زمان مأموریتها و تخصیص رباتها را بهینه کند. برای مثال، اگر در یکی از ایستگاهها تأخیری در فرایند مونتاژ رخ دهد، مدل DRL از طریق دوقلو وضعیت را پیشبینی کرده و مأموریتهای حمل آن ایستگاه را به مسیرهای دیگر توزیع میکند. این قابلیت باعث میشود که خط تولید هیچگاه متوقف نشود و بهرهوری کلی تا ۴۰٪ افزایش یابد.
۳. صنایع سنگین و محیطهای خطرناک
در محیطهایی مثل فولادسازی، پتروشیمی یا بنادر صنعتی، رباتهای حملبار باید در شرایط سخت و متغیر کار کنند — دماهای بالا، میدانهای مغناطیسی یا مسیرهای غیرقابل پیشبینی. در اینجا Digital Twin بهعنوان یک لایهی حفاظتی عمل میکند که وضعیت ایمنی هر ربات را در لحظه پایش میکند و DRL بر اساس دادههای خطر، تصمیمهای اصلاحی میگیرد. برای مثال، اگر یکی از مسیرها بهدلیل دمای بالا ناایمن شود، سیستم بلافاصله مسیر جایگزین با کمترین ریسک را پیشنهاد میدهد و بهصورت تطبیقی سیاست حرکتی کل ناوگان را بازآرایی میکند. در عمل، این فناوری میتواند میزان حوادث و توقفهای ایمنی را تا ۶۰٪ کاهش دهد.
۴. مراکز لجستیکی بینالمللی و بنادر خودکار
در بنادر بزرگ، هماهنگی میان وسایل نقلیهی خودکار، جرثقیلها و سامانههای بارگیری اهمیت حیاتی دارد. Digital Twin در این محیط نقش نقشهی زندهی بندر را دارد که در لحظه وضعیت هر AGV، کانتینر و مسیر حرکتی را رصد میکند. الگوریتم DRL از این دادهها برای پیشبینی تراکم، اولویتبندی بارگیریها و جلوگیری از تأخیر استفاده میکند. این هماهنگی هوشمند باعث میشود که زمان جابهجایی هر کانتینر تا ۲۵٪ کاهش یابد و بهرهبرداری از ظرفیت بندر به حداکثر برسد.
۵. زنجیرههای تأمین متصل و کارخانههای چندسازمانی
در آیندهی نزدیک، کارخانهها و انبارهای مختلف از طریق ابر صنعتی (Industrial Cloud) بهصورت زنده به هم متصل خواهند شد. مدل Digital Twin–DRL میتواند این شبکههای مستقل را به یک اکوسیستم تصمیمساز مشترک تبدیل کند. بهطور مثال، وقتی در کارخانهی A افزایش حجم تولید رخ میدهد، سیستم از طریق دوقلوی دیجیتال دادهها را با کارخانهی B همگام میکند تا رباتهای B برای پشتیبانی لجستیکی برنامهریزی مجدد شوند. این ارتباط هوشمند باعث ایجاد یک زنجیرهی تأمین خودسازمانیافته میشود که نهتنها واکنشگرا، بلکه پیشبینانه است.
۶. مدیریت انرژی و پایداری سبز
یکی از ارزشمندترین دستاوردهای این فناوری، توانایی آن در کاهش مصرف انرژی و ارتقای پایداری زیستمحیطی است. الگوریتم DRL با مشاهدهی دادههای مصرف انرژی در دوقلوی دیجیتال، میتواند الگوهای غیرکارآمد را شناسایی کند. برای مثال، سیستم یاد میگیرد که در ساعات کمترافیک، مأموریتهای سنگین را اجرا کند تا مصرف انرژی در زمان اوج کاهش یابد. نتیجهی این راهبردها کاهش ۲۰ تا ۳۰ درصدی مصرف برق و افزایش طول عمر باتریهاست.
۷. تعامل انسان–ربات در محیطهای پیچیده
در بسیاری از مراکز توزیع و کارخانهها، هنوز تعامل مستقیم میان اپراتورها و رباتها وجود دارد. مدل Digital Twin–DRL میتواند با استفاده از رابطهای بصری و زبان طبیعی، پلی میان انسان و سیستم بسازد. اپراتور میتواند تصمیمهای پیشنهادی سیستم را در محیط مجازی ببیند و در صورت نیاز اصلاح کند. در مقابل، الگوریتم از بازخورد انسانی یاد میگیرد و در تکرارهای بعدی تصمیمهای دقیقتری میگیرد. این تعامل انسانی–ماشینی باعث افزایش اعتماد و پذیرش فناوری در میان نیروهای انسانی میشود.
بهطور کلی، ترکیب دوقلوی دیجیتال و یادگیری تقویتی عمیق نهتنها برای بهینهسازی عملکرد رباتها، بلکه برای تبدیل لجستیک صنعتی به یک اکوسیستم هوشمند، قابل پیشبینی و خودتوسعهیاب طراحی شده است. این فناوری به سازمانها اجازه میدهد تصمیمگیری را از سطح فرمان مرکزی به سطح خودِ رباتها منتقل کنند — جایی که هر عامل میبیند، میفهمد، یاد میگیرد و بر اساس واقعیت زنده تصمیم میگیرد.
جمعبندی استراتژیک و مزیتهای رقابتی مدل Digital Twin–DRL
در عصر صنعتی امروز، که مرز میان دنیای فیزیکی و دیجیتال بهتدریج از بین میرود، فناوریهایی موفق خواهند بود که بتوانند میان «عمل» و «ادراک» پیوند برقرار کنند. دوقلوی دیجیتال و یادگیری تقویتی عمیق دقیقاً در این نقطه قرار دارند. این دو با هم، مغز و حافظهی صنعت آینده را شکل میدهند؛ مغزی که میفهمد، تصمیم میگیرد و در لحظه یاد میگیرد، و حافظهای که تمام تجربهها را به دانشی جمعی تبدیل میکند. در چنین چارچوبی، رباتهای حملبار دیگر صرفاً ابزار حمل نیستند، بلکه به اجزایی از یک اکوسیستم دانشی خودآگاه تبدیل میشوند که میتواند خود را با هر تغییری تطبیق دهد.
از دید مدیریتی، بزرگترین مزیت این مدل در انتقال هوش از مرکز فرمان به لبهی شبکه (Edge Intelligence) است. در سیستمهای سنتی، همهی تصمیمها باید از یک مرکز صادر شوند، اما در مدل Digital Twin–DRL هر ربات به یک تصمیمگیر مستقل تبدیل میشود. این یعنی سازمان از یک ساختار فرماندهی متمرکز به یک ساختار تصمیمسازی توزیعشده تغییر میکند؛ درست مانند گذار از بوروکراسی به شبکهی عصبی. نتیجه، افزایش چابکی، تابآوری و حذف وابستگی به نقاط بحرانی است. در شرایطی که اختلال شبکه یا خطا در یک بخش میتواند کل سیستم را متوقف کند، این رویکرد توزیعشده تضمین میکند که حتی در مواجهه با شکستهای موضعی، عملکرد کل مجموعه حفظ شود.
یکی دیگر از مزیتهای بنیادین این فناوری، کاهش هزینه و افزایش بهرهوری سرمایه است. دوقلوی دیجیتال امکان تست، ارزیابی و بهینهسازی تصمیمها را پیش از اجرا در دنیای واقعی فراهم میکند. این یعنی سازمانها میتوانند بدون ریسک توقف عملیات یا آسیب به تجهیزات، صدها سناریو را شبیهسازی و بهترین تصمیم را انتخاب کنند. از سوی دیگر، DRL به سیستم توانایی تطبیق مداوم با تغییرات را میدهد؛ بنابراین مدل نیازی به بازبرنامهریزی ندارد، بلکه خودش در طول زمان دقیقتر و کارآمدتر میشود. این ویژگی هزینههای نگهداری نرمافزار و نیروی انسانی را بهطور قابلتوجهی کاهش میدهد و بازگشت سرمایه (ROI) فناوری را تسریع میکند.
در سطح عملکردی، این فناوری مزیت مهم دیگری دارد: درک علت تصمیمها. برخلاف مدلهای جعبهسیاه سنتی، در این چارچوب هر تصمیم نهتنها نتیجهی یک محاسبه بلکه حاصل یک فرایند منطقی و قابل توضیح است. چون تمام تصمیمها در دوقلوی دیجیتال ثبت و تحلیل میشوند، مدیران صنعتی میتوانند بفهمند چرا سیستم مسیر خاصی را انتخاب کرده یا چرا یک ربات مأموریتش را تغییر داده است. این شفافیت، پایهی اعتماد بین انسان و فناوری را میسازد و راه را برای پذیرش گستردهتر هوش مصنوعی در محیطهای عملیاتی باز میکند.
از نظر استراتژیک، مدل Digital Twin–DRL مسیر صنعت را از «اتوماسیون» به سمت هوش تصمیمساز (Decision Intelligence) هدایت میکند. در اتوماسیون سنتی، هدف انجام کارها با سرعت و دقت بیشتر بود؛ اما در هوش تصمیمساز، هدف فهمیدن، پیشبینی و بهبود مستمر است. این رویکرد به سازمانها اجازه میدهد قبل از بروز مشکل، آن را تشخیص دهند و راهحل را پیشاپیش طراحی کنند. بهعبارت دیگر، سیستم از حالت واکنشی به حالت پیشبینیکننده و خوداصلاحگر تبدیل میشود.
همچنین از دید زیستمحیطی، این فناوری نقش مهمی در پایداری صنعتی دارد. چون تصمیمهای بهینهتر به مصرف انرژی کمتر، استفادهی مؤثرتر از تجهیزات و کاهش ترافیک منجر میشوند، ردپای کربنی کل سیستم بهشدت کاهش پیدا میکند. این یعنی Digital Twin–DRL نهتنها از نظر اقتصادی کارآمد است، بلکه با سیاستهای جهانی Industry 5.0 و Green Logistics نیز کاملاً همسو است.
اما شاید مهمترین مزیت رقابتی این فناوری در مفهوم یادگیری جمعی (Collective Learning) نهفته باشد. هر دوقلوی دیجیتال نهتنها آینهی یک ربات، بلکه جزئی از شبکهی دانشی کل سیستم است. وقتی یکی از رباتها تجربهی جدیدی کسب میکند، همه از آن یاد میگیرند. بهمرور زمان، این دانش جمعی تبدیل به دارایی نامشهود اما بیقیمت سازمان میشود — نوعی «DNA دیجیتال لجستیک» که هیچ رقیبی نمیتواند بهسادگی آن را کپی کند.
در نهایت، این فناوری یک تحول فرهنگی در صنعت نیز ایجاد میکند. سازمانهایی که از این مدل استفاده میکنند، بهجای تصمیمگیری بر اساس شهود انسانی، بر پایهی گفتوگوی داده و تجربه عمل میکنند. سیستمهای دیجیتال نه جایگزین انسان، بلکه شریک فکری او میشوند. مدیران بهجای آنکه درگیر کنترل رباتها باشند، روی توسعهی استراتژی، طراحی فرآیند و تحلیل بینشهای بهدستآمده تمرکز میکنند. این یعنی جهش از «مدیریت عملیات» به «رهبری دادهمحور».
به زبان ساده، Digital Twin–DRL صنعت را از عصر کنترل به عصر گفتوگو میبرد — گفتوگویی میان داده، تصمیم و درک. این همان تفاوتی است که آینده را از گذشته جدا میکند: در گذشته، رباتها حرکت میکردند؛ در آینده، آنها میاندیشند.
نتیجهگیری نهایی
تحول دیجیتال در صنعت امروز دیگر به معنای صرفاً هوشمندسازی خطوط تولید یا خودکارسازی حرکت رباتها نیست؛ بلکه به معنای خلق سیستمهایی است که میبینند، میفهمند، میآموزند و در لحظه تصمیم میگیرند. چارچوب Digital Twin–DRL دقیقاً در همین نقطه ایستاده است — جایی که داده از سطح اطلاعات خام فراتر میرود و به بینش عملیاتی تبدیل میشود، و سیستم از سطح فرمانپذیری به سطح تفکر و خودتصمیمگیری ارتقا مییابد.
این مدل، با ترکیب دوقلوی دیجیتال بهعنوان حافظهی زندهی عملیات و یادگیری تقویتی عمیق بهعنوان مغز تطبیقی تصمیمگیری، توانسته است یکی از قدیمیترین چالشهای صنعت — یعنی نبود هماهنگی، پیشبینی و یادگیری در عملیات بلادرنگ — را حل کند. اکنون برای نخستین بار، رباتهای حملبار نهتنها وضعیت فعلی خود، بلکه آیندهی نزدیک را نیز درک میکنند. آنها یاد گرفتهاند چگونه در محیطهای پیچیده، تصمیمهای سریع و هوشمند بگیرند، از خطاهای گذشته بیاموزند، و با سایر رباتها به شکل یک شبکهی دانشی جمعی همکاری کنند.
از منظر صنعتی، این فناوری یک جهش راهبردی محسوب میشود. نتایج تجربی مقاله نشان داد که پیادهسازی مدل Digital Twin–DRL میتواند تا ۴۰٪ در بهرهوری کلی، ۲۵٪ در مصرف انرژی، و ۵۰٪ در کاهش زمان توقف مأموریتها صرفهجویی ایجاد کند. اما فراتر از اعداد، ارزش واقعی در ایجاد «درک مشترک» میان ماشینها و سیستمها نهفته است — درکی که عملیات را از سطح واکنش مکانیکی به سطح تحلیل شناختی میبرد.
از دید مدیریتی، این فناوری مسیر صنعت را از «اتوماسیون عملیاتی» به «هوش تصمیمساز صنعتی» هدایت میکند. مدیران دیگر نیازی ندارند تصمیمها را از بالا دیکته کنند؛ آنها فقط هدف را تعیین میکنند و سیستم، بر پایهی دادههای زنده و تجربهی جمعی، بهترین مسیر را انتخاب میکند. این همان مفهوم Self-Evolving Industry یا صنعت خودتوسعهیاب است — صنعتی که میتواند خودش بیاموزد، خود را اصلاح کند و خودش پیشرفت نماید.
در واقع، Digital Twin–DRL را میتوان زیرساخت ذهنی نسل بعدی کارخانهها دانست؛ ذهنی که میان واقعیت و مجاز، میان تصمیم و تجربه، و میان داده و عمل پلی دائمی ایجاد میکند. در آینده، هر ربات، هر خط تولید و هر مرکز لجستیکی دوقلوی دیجیتالی خواهد داشت که با او فکر میکند، اشتباهاتش را تحلیل میکند و مسیر بهتر را پیشنهاد میدهد.
اکنون زمان آن رسیده است که مدیران صنعتی، شرکتهای لجستیکی و پژوهشگران حوزهی رباتیک بهجای نگاه به فناوری بهعنوان ابزار، آن را بهعنوان همکار فکری سیستم ببینند. دوقلوهای دیجیتال باید در تمام مراحل طراحی، بهرهبرداری و نگهداری وارد چرخهی تصمیمگیری شوند و الگوریتمهای DRL بهصورت پیوسته در بطن عملیات فعال باشند. پیشنهاد میشود سازمانها اجرای آزمایشی (Pilot Implementation) این فناوری را در مقیاس کوچک آغاز کنند — مثلاً با ۵ تا ۱۰ ربات حملبار در یک بخش از کارخانه — و سپس آن را بهصورت تدریجی به کل شبکه تعمیم دهند.
برای دانشگاهها و مراکز تحقیقاتی نیز زمان آن فرا رسیده است که روی توسعهی مدلهای Digital Twin-aware Reinforcement Learning متمرکز شوند؛ الگوریتمهایی که بتوانند از دادههای زنده یاد بگیرند و در لحظه تصمیمهای چندهدفه بگیرند. آیندهی هوش مصنوعی صنعتی در همین همگرایی است؛ جایی که مهندسی، داده و یادگیری در یک مدار پیوسته قرار میگیرند.
برای سیاستگذاران صنعتی نیز این فناوری یک فرصت راهبردی است تا مسیر گذار از Industry 4.0 به Industry 5.0 را هموار کنند — صنعتی که در آن انسان و ماشین نه در تقابل، بلکه در همکاری و یادگیری مشترک رشد میکنند.
پیام پایانی
دوقلوی دیجیتال و یادگیری تقویتی عمیق نشان دادند که هوش واقعی فقط در پیشبینی نیست، بلکه در درک و سازگاری مداوم است. سیستمهایی که میتوانند از خود بیاموزند، از اشتباهات تغذیه کنند و در هر لحظه بهترین تصمیم را بسازند، نه فقط آیندهی لجستیک، بلکه آیندهی کل صنعت را تعریف میکنند. رباتهایی که امروز در مسیرهای انبار حرکت میکنند، در آینده دیگر صرفاً حامل بار نخواهند بود — بلکه حامل خرد دیجیتال، حافظهی سازمانی و هوش تطبیقی خواهند بود. این فناوری ما را به صنعتی نزدیک میکند که نهفقط خودکار است، بلکه خودآگاه است.
رفرنس مقاله
Donggun Lee, Yong-Shin Kang, and Sang Do Noh,
“Digital twin-driven deep reinforcement learning for real-time optimisation in dynamic AGV systems,”
International Journal of Production Research, vol. 63, no. 5, 2025, pp. 842–858.*
DOI: 10.1080/00207543.2025.3358712
{kind=link}
بدون نظر