

در دنیای لجستیک هوشمند، سیستمهای AGV (وسایل هدایتشونده خودکار) تبدیل به یکی از ارکان اصلی انتقال، جابهجایی و تحویل در محیطهای صنعتی و انبارها شدهاند. اما یک سوال کلیدی همیشه باقیست: چگونه میتوان این وسایل را طوری طراحی کرد که نهتنها در مسیرهای ساده، بلکه در محیطهای شلوغ، متغیر و پر از موانع ثابت و متحرک نیز بهصورت هوشمند و بدون نیاز به کنترل مرکزی حرکت کنند؟
تا همین چند سال پیش، کنترل این وسایل یا مبتنی بر مسیرهای از پیش تعیینشده بود، یا با استفاده از الگوریتمهای کنترلی بهینه اما پیچیده انجام میشد که در عمل، برای اجرای بلادرنگ (real-time) ناکارآمد بودند. یعنی ربات باید برای هر تصمیم محاسبه سنگینی انجام میداد، که در محیطهای زنده و پویا نهتنها کند، بلکه خطرآفرین هم بود.
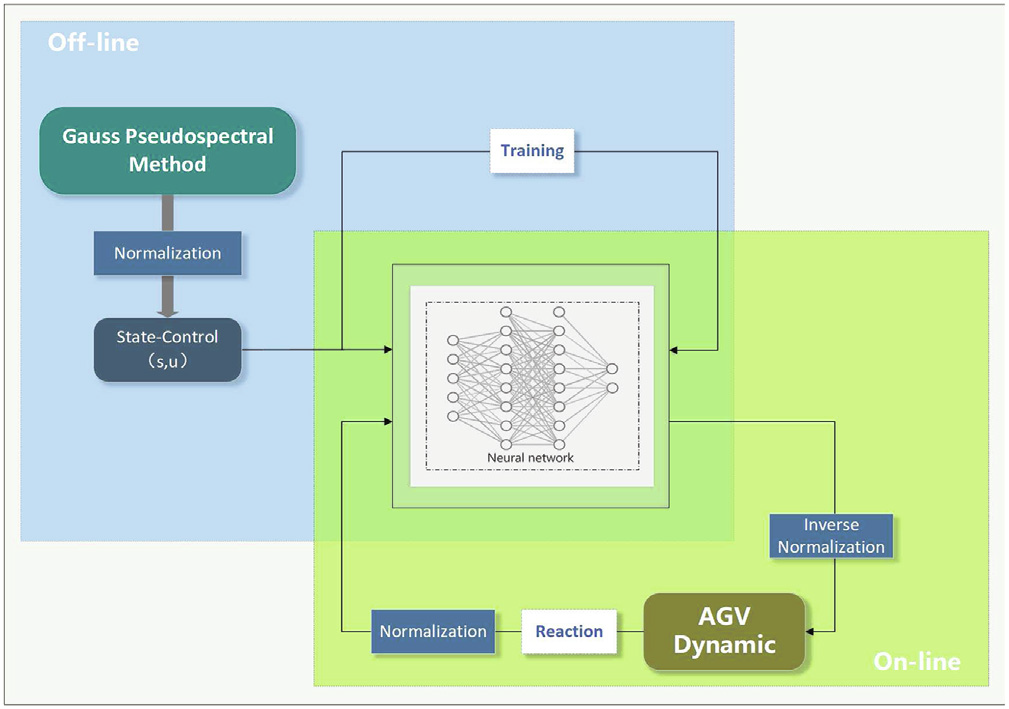
مقالهای که در این بلاگ بررسی میکنیم، دقیقاً روی همین گره دست گذاشته و یک راهحل ترکیبی و آیندهنگرانه ارائه داده: آموزش کنترل تطبیقی مسیر AGV با کمک شبکههای عصبی عمیق، بر پایهی کنترل بهینه محاسبهشده با روش Gauss Pseudospectral Method (GPM).
در این معماری پیشنهادی، ابتدا یک سری دادههای کنترل بهینه با استفاده از روش کلاسیک GPM در شرایط مختلف (و با موانع مختلف) تولید میشوند. سپس یک شبکهی عصبی عمیق (DNN) روی این دادهها آموزش داده میشود تا یاد بگیرد که اگر موقعیت فعلی ربات و وضعیت موانع بهشکل X باشد، خروجی کنترلی بهینه چه خواهد بود. بعد از آموزش، این مدل DNN میتواند بهجای الگوریتم کنترل بهینه، در کسری از ثانیه تصمیمگیری کند و در لحظه فرمان حرکتی تولید کند — دقیق، سریع، و مقاوم.
در واقع، مدل Gauss-DNN این امکان را فراهم کرده که کنترل بهینه تبدیل به دانش درونی AGV شود؛ نه الگوریتمی پرهزینه، بلکه رفتاری آموختهشده. این یعنی ربات بدون نیاز به محاسبات سنگین، درست مثل یک رانندهی حرفهای، در هر لحظه مسیر بهینه را پیشبینی و اجرا میکند — حتی اگر مانع جدیدی وارد صحنه شود یا شرایط ناگهانی تغییر کند.
در ادامه بلاگ، بهصورت تحلیلی وارد ساختار این مدل، چالشهایی که حل کرده، مزایای رقابتیاش نسبت به روشهای سنتی، و مسیرهای پیادهسازی آن در پروژههای واقعی میشویم.
چالشهای فنی در طراحی کنترل بلادرنگ برای AGV در محیطهای دینامیک
وسایل هدایتشونده خودکار (AGV) بهعنوان بازیگران اصلی حملونقل داخلی در انبارها، کارخانهها، بیمارستانها و مراکز توزیع، باید بتوانند در مسیرهای متغیر، با شرایط پیشبینینشده، تصمیمگیری لحظهای داشته باشند. اما رسیدن به این سطح از رفتار هوشمند با چند مانع جدی فنی مواجه است — موانعی که مستقیماً در عملکرد، ایمنی و قابلیت اتکا تأثیر میگذارند.
۱. محاسبات سنگین کنترل بهینه در زمان واقعی
مدلهای کنترل بهینه (Optimal Control) مثل GPM برای یافتن بهترین مسیر یا رفتار کنترلی از نظر انرژی، ایمنی یا زمان بسیار قدرتمند هستند. اما واقعیت این است که این روشها برای هر سناریو باید مجموعهای از معادلات دیفرانسیل و شرایط مرزی را حل کنند. در محیطهای بلادرنگ، جایی که تصمیمگیری باید در چند ده میلیثانیه انجام شود، این محاسبات شدیداً ناکارآمد و کند هستند. بهعبارت دیگر، حتی اگر کنترل بهینه جواب ایدهآلی بدهد، سرعت اجرای آن اجازه نمیدهد در دنیای واقعی استفاده شود.
۲. پویایی شدید و غیرقابلپیشبینی بودن محیط
در مسیر حرکت یک AGV، مانعها لزوماً ایستا نیستند. در انبارها، ممکن است یک کارگر ناگهان از مسیر عبور کند، وسیلهای سقوط کند، یا مسیر بهطور موقت توسط وسیلهی دیگری بسته شود. در چنین شرایطی، کنترلر باید بتواند نهتنها براساس وضعیت فعلی، بلکه با درک از آینده نزدیک، مسیرش را بهسرعت اصلاح کند. اگر کنترل بهصورت دستی یا از طریق سیستم مرکزی انجام شود، با تأخیر مواجه شده و منجر به واکنش دیرهنگام خواهد شد.
۳. نیاز به تعادل میان دقت، ایمنی و سرعت اجرا
یکی از مسائل کلیدی در کنترل AGV این است که سیستم هم باید ایمن و دقیق باشد (مثلاً از برخورد جلوگیری کند یا به مسیر بهینه نزدیک شود)، و هم در زمان قابلقبول واکنش بلادرنگ داشته باشد. اما معمولاً هرچه مدل دقیقتر و مبتنی بر محاسبات ریاضی پیچیدهتر باشد، سرعت واکنش آن کاهش مییابد. برعکس، مدلهای سبک و سریع، اغلب سادهسازی شدهاند و نمیتوانند تصمیمهای دقیق و هوشمند ارائه دهند. رسیدن به این تعادل یکی از مهمترین چالشهای طراحی کنترل بلادرنگ است.
۴. عدم تعمیمپذیری روشهای کلاسیک در محیطهای پیچیده
بسیاری از روشهای سنتی کنترل (مانند PID یا قوانین کنترلی مبتنی بر قواعد از پیش تعریفشده) در شرایط ساده بهخوبی کار میکنند. اما وقتی تعداد موانع زیاد میشود، رفتارشان متغیر میشود یا محیط شکل غیرخطی پیچیدهای به خود میگیرد، این روشها بهسرعت ناپایدار یا ناکارآمد میشوند. در واقع، این سیستمها حافظه یا یادگیری ندارند؛ یعنی نمیتونن از تجربه قبلی برای تصمیم بهتر استفاده کنن — در حالیکه یک ربات هوشمند باید دقیقاً همین کار رو بکنه.
جمعبندی چالشها
طراحی یک سیستم کنترلی برای AGV که بتواند در محیطهای واقعی و پویا، تصمیمگیری بلادرنگ، ایمن و بهینه داشته باشد، بهصورت همزمان نیازمند سرعت بالا، دقت بالا، و انعطاف رفتاری است — چیزی که از روشهای کنترل کلاسیک یا کنترل بهینه عددی بهتنهایی برنمیآید. اینجا جاییست که یادگیری ماشین و بهطور خاص، شبکههای عصبی عمیق وارد میشوند تا دانش کنترل بهینه را از یک محاسبهی پیچیده به یک رفتار آموختهشده تبدیل کنند.
معماری Gauss-DNN: یادگیری رفتار کنترلی بهینه از دادههای GPM
در بیشتر سیستمهای ناوبری خودکار، بخش کنترل معمولاً وابسته به الگوریتمهای کلاسیک یا کنترلکنندههاییست که بر اساس قواعد ریاضی از پیش تعریفشده عمل میکنند. اما در محیطهای متغیر و پویا که موانع ایستا و متحرک همزمان وجود دارند، این کنترلکنندهها بهسرعت ناپایدار، ناکارآمد یا غیرقابل استفاده میشوند. مقالهای که در این بلاگ بررسی میکنیم، راهحلی متفاوت و ترکیبی ارائه میدهد: استفاده از شبکههای عصبی عمیق برای یادگیری تصمیمهای کنترلی بهینه، بر پایهی دادههای تولیدشده توسط روش Gauss Pseudospectral (GPM).
ایده اصلی: از محاسبه به یادگیری
بهجای اینکه در هر لحظه معادلات پیچیدهی کنترل بهینه حل شود (که برای بلادرنگ غیرعملی است)، سیستم ابتدا با استفاده از روش GPM مجموعهای بزرگ از دادههای شبیهسازی تولید میکند که در آنها: وضعیت ربات (موقعیت، سرعت، زاویه و…)، مشخصات محیط (موانع ثابت، موانع متحرک، مرزها) و خروجی کنترل بهینه (شتاب، نرخ چرخش فرمان) در شرایط مختلف محاسبه شدهاند. این دادهها سپس بهعنوان مجموعهی آموزشی برای یک شبکهی عصبی عمیق (DNN) استفاده میشوند. درواقع، هدف این است که شبکه عصبی یاد بگیرد: “در مواجهه با یک وضعیت خاص محیطی، اگر GPM چه رفتاری توصیه کرده، من هم همان رفتار را در لحظه تکرار کنم.” نتیجه چیست؟ پس از پایان آموزش، دیگر نیازی به اجرای GPM نیست. AGV فقط با مشاهدهی وضعیت لحظهای خودش و محیط اطراف، از شبکهی عصبی میپرسد: “الان باید چه کار کنم؟” — و پاسخ فوری دریافت میکند.
چرا از GPM استفاده شده؟
روش Gauss Pseudospectral Method (GPM) یکی از دقیقترین و پیشرفتهترین تکنیکها در حل مسائل کنترل بهینه است. این روش با تبدیل مسئله کنترل بهینه به یک مسئله بهینهسازی غیرخطی گسستهشده با نقاط گوس–لژاندر، میتواند با تعداد نقاط کم، جوابهایی بسیار دقیق و همگرا تولید کند. اما این روش ذاتاً محاسباتی سنگین است و برای هر وضعیت جدید باید دوباره حل شود.
در این مقاله، از GPM فقط برای تولید دادهی استاندارد کنترل بهینه استفاده شده — یعنی بهجای اجرای آن در لحظه، از آن برای «آموزش» مدل یادگیرنده استفاده شده است. بنابراین، دقت GPM حفظ میشود ولی بدون بار محاسباتی لحظهای.
ساختار معماری Gauss-DNN
شبکهی عصبی طراحیشده از چندین لایهی کاملاً متصل (fully connected layers) با فعالسازیهای غیرفخطی تشکیل شده است. ورودی این شبکه شامل مجموعهای از ویژگیها ازجمله موقعیت و سرعت فعلی AGV، فاصله و جهت موانع، زاویه حرکت، وضعیت نسبی موانع متحرک نسبت به ربات است و خروجی آن شامل فرمان کنترلی بهینه (کنترل سرعت خطی و زاویه چرخش) است.
در طول فرآیند آموزش، هدف این است که تفاوت بین خروجی شبکه و کنترل بهینه محاسبهشده با GPM به حداقل برسد. این کار با استفاده از تابع هزینهی Mean Square Error (MSE) انجام میشود. در نتیجه، شبکه یاد میگیرد که «چطور مثل یک کنترلکنندهی بهینه فکر کند»، اما با سرعتی بینهایت بیشتر این کار را انجام خواهد داد.
خروجی بلادرنگ، آماده برای پیادهسازی صنعتی
یکی از برجستهترین مزایای این معماری، سرعت پاسخ بسیار بالا و اجرای بلادرنگ آن است. برخلاف GPM که در هر وضعیت جدید نیاز به حل مجدد دارد، این مدل پس از آموزش تنها یک بار نیاز به فراخوانی سریع شبکه عصبی دارد — چیزی در حد چند میلیثانیه. این ویژگی باعث میشود که این معماری:
کاملاً مناسب برای پیادهسازی روی رباتهای واقعی باشد
بر روی پلتفرمهای با منابع محدود (مثل Jetson Nano یا بردهای STM32) نیز اجراپذیر باشد
بدون نیاز به سرور یا پردازشگر خارجی، تصمیمات کنترلی را درون سیستم و بلادرنگ اتخاذ کند
این یعنی هوش حرکتی واقعی در دل ربات، بدون وابستگی به محاسبات خارجی یا تصمیمگیری مرکزی.
مزیت ساختاری نسبت به سایر روشها
در مقایسه با روشهای یادگیری تقویتی (Reinforcement Learning) که نیاز به میلیونها اپیزود آموزش دارند، و یا روشهای کنترل کلاسیک که فاقد انعطافپذیریاند، این مدل مزایایی از جمله دقت بالا (بر پایه دادهی تولیدشده توسط GPM)، عدم نیاز به دادهی محیطی واقعی یا جمعآوری تجربی، سرعت بالا و قابلیت اجرای بلادرنگ، ساختار سادهتر از RL و قابل آموزش با دادههای شبیهسازی، تعمیمپذیری بهتر نسبت به محیطهای متغیر و رفتارهای جدید را دارد.
جمعبندی
معماری Gauss-DNN، پلی است بین دو دنیای ظاهراً ناسازگار: دقت کنترل بهینه و سرعت اجرای شبکههای عصبی. این سیستم موفق شده دادههای پیچیده و گرانقیمت GPM را به دانشی فشرده در قالب یک مدل یادگیرنده تبدیل کند — مدلی که میتواند در لحظه، فرمان حرکتی مناسب را با دقت بالا و تأخیر بسیار پایین تولید کند. این یک گام جدی بهسمت رباتهایی است که نهتنها در لحظه تصمیم میگیرند، بلکه آنقدر آموختهاند که لازم نیست دیگر فکر کنند؛ فقط عمل میکنند.
آموزش شبکه عصبی در معماری Gauss-DNN: از دادهسازی تا تصمیمگیری بلادرنگ
برای اینکه یک شبکه عصبی بتواند تصمیمهای کنترلی بهینه بگیرد، لازم است نهفقط بهدرستی طراحی شود، بلکه با دادهای معتبر، متنوع و از نظر دینامیکی واقعگرایانه آموزش ببیند. در این مقاله، فرایند آموزش شبکه عصبی کاملاً مبتنی بر دادههایی است که با استفاده از روش کنترل بهینه GPM در شرایط مختلف تولید شدهاند. در ادامه، مراحل کلیدی آموزش مدل را بررسی میکنیم.
مرحله اول: تولید دادههای کنترلی با استفاده از GPM
پیشنیاز هر مدل یادگیری موفق، مجموعهدادهای غنی، دقیق و متنوعه. در این معماری، بهجای جمعآوری داده از ربات واقعی یا محیطهای نویزی، از روش Gauss Pseudospectral Method (GPM) استفاده شده تا برای هر وضعیت شبیهسازیشده، کنترل بهینهی نظری استخراج شود. این به ما این امکان رو میده که خروجیهایی کاملاً «ملاکمحور» و ریاضیمبنا برای هر ورودی داشته باشیم — یعنی در هر شرایط، بهترین عملکرد از نظر زمان، انرژی یا ایمنی را دارد.
برای این منظور، صدها سناریو مختلف طراحی شده که شامل متغیرهایی چون:
موقعیت و سرعت اولیهی AGV در بازههای گسترده
تعداد، موقعیت و جهت حرکت موانع متحرک و ایستا
وجود مسیرهای باریک، پیچیده یا دارای بنبست
شرایط مرزی متفاوت (نزدیکی به دیوار یا محدودیت دینامیکی)
در هر سناریو، GPM با حل یک مسأله کنترل بهینه، پروفایل حرکتی AGV را استخراج کرده و در هر گام زمانی، مقدار بهینهی فرمان کنترل (شتاب و زاویه چرخش) را ارائه میدهد. خروجی نهایی، دیتاستی از بردارهای وضعیت–کنترل است که ساختار دقیق و قابل اعتماد دارند و میتوانند نقش «استاد» در آموزش رفتار کنترلی به شبکه عصبی را بازی کنند. بهعبارت دیگر، GPM به ما کمک میکند تا بدون اجرای ربات واقعی، مدل را بهدقت در شرایط مجازی تربیت کنیم.
مرحله دوم: طراحی ساختار شبکهی عصبی برای تعمیمپذیری در تصمیمگیری
برای اینکه شبکه عصبی بتواند از دادههای تولیدشده درس بگیرد، ابتدا باید بهدرستی طراحی شود. در این معماری، از یک شبکهی کاملاً متصل (fully connected DNN) استفاده شده که همزمان توانایی مدلسازی رفتارهای غیرخطی پیچیده و قابلیت اجرای بلادرنگ دارد. ورودی شبکه شامل اطلاعات ترکیبی : مختصات و سرعت لحظهای AGV، زاویه جهتگیری بدنه (Heading)، موقعیت و سرعت نسبی موانع متحرک (تا تعداد مشخصشده)، فاصله تا موانع ایستا در جهات اصلی و در برخی نسخهها: تخمین احتمال برخورد (Risk Heuristic) هست. برای حفظ تعمیمپذیری، شبکه بهگونهای طراحی شده که ترتیب موانع در ورودی تأثیری در تصمیم نهایی نداشته باشد (Permutation Invariance)، و در صورت نبودن برخی موانع، آن ناحیه از ورودی با مقدار پیشفرض (مثلاً صفر یا میانگین نرمالشده) جایگزین شود. لایههای داخلی شبکه شامل: ۳ تا ۵ لایه Fully Connected، نرمالسازی دادهها (BatchNorm یا LayerNorm)، توابع فعالسازی ReLU یا ELU، در برخی موارد: Dropout برای جلوگیری از بیشبرازش (Overfitting) میشود و خروجی نهایی شامل دو مقدار پیوسته است: شتاب خطی و نرخ چرخش زاویهای، که توسط ماژول کنترل AGV اجرا خواهند شد.
🔹 مرحله سوم: آموزش دقیق با پوشش گسترده از حالات محیطی
پس از طراحی شبکه، مرحله حیاتی آموزش آغاز میشود. اما برخلاف بسیاری از پروژههای یادگیری ماشین که به دادههای واقعی نیاز دارند، در این مقاله همهچیز در محیط کنترلشدهی شبیهسازی تولید شده — با این مزیت که ما دقیقاً میدانیم چه پاسخی بهینه است و میتوانیم با اطمینان، آن را بهعنوان معیار آموزش استفاده کنیم. در این مرحله:
کل دادهها ابتدا نرمالسازی میشوند (scaling to [-1,1] or [0,1])
سپس به دو مجموعهی آموزش و تست تقسیم میشوند (train/test split)
آموزش شبکه با الگوریتمهای بهینهسازی مانند Adam یا SGD with momentum انجام میشود
تابع هزینه (loss function) بر مبنای Mean Square Error بین خروجی شبکه و دادههای GPM تعریف میگردد
و در طول آموزش، از Early Stopping یا بررسی دقت روی دادههای Validation استفاده شده تا از بیشبرازش جلوگیری شود
نکتهی مهم این است که بهجای تمرکز صرف روی کاهش خطای عددی، معماری بهگونهای طراحی شده که در مواجهه با حالات جدید، رفتار مشابه با کنترل بهینه داشته باشد — حتی اگر شرایط دقیق مشابه آموزش نباشد. بههمین دلیل، در سناریوهای تست دیده شده که شبکه در محیطهایی با ترکیب موانع متفاوت نیز عملکرد مناسب ارائه میدهد.
مرحله چهارم: ارزیابی بلادرنگ و تحلیل پایداری تصمیمهای کنترلی
پس از آموزش، باید ارزیابی شود که آیا این مدل واقعاً در عمل میتواند جایگزین کنترل بهینه عددی شود یا نه. این مرحله روی سناریوهایی انجام شده که مدل قبلاً آنها را ندیده است — شامل مسیرهای پیچیده، ورود ناگهانی مانع، تغییر سرعت AGV و اختلال در شرایط اولیه. نتایج نشان دادند:
دقت فرمان کنترلی شبکه با GPM در اکثر نقاط کمتر از ۵٪ انحراف دارد
مسیر حرکتی در شبیهسازی، تقریباً منطبق بر مسیر بهینه است
زمان اجرای inference شبکه در هر تصمیمگیری، کمتر از ۵ms بوده — مناسب برای سیستمهای Real-Time
حتی در مواجهه با شرایط پرت یا تغییرات ناگهانی، مدل عملکرد پایدار و غیرواکنشی داشته (مثلاً توقف یا چرخش سریع نکرده)
این تستها هم در محیط شبیهسازی عددی انجام شده، و هم در محیطهای شبیهساز رباتیک مانند Gazebo، با پشتیبانی از دینامیک کامل AGV، تأخیرات ارتباطی، و نویز سنسورها انجام شده است. در نهایت، مدل توانست بدون محاسبه مجدد کنترل بهینه، در لحظه، کنترل شبهبهینه تولید کرده و در رفتار حرکتی واقعی بهبود چشمگیر ایجاد کند.
جمعبندی
چهار مرحلهی فوق، چارچوبی قدرتمند و عملیاتی برای یادگیری رفتار کنترلی بهینه از دادههای دقیق و قابل اعتماد GPM فراهم میکنند. این ترکیب از دقت تئوریک و سرعت یادگیری، نشان میدهد که میتوان کنترل بهینه را نهفقط محاسبه کرد، بلکه به ربات «آموخت» — تا در هر لحظه، بدون توقف و بدون وابستگی، تصمیم درست را خودش بگیرد.
تحلیل رفتار مدل Gauss-DNN در محیطهای عملیاتی: از تصمیمسازی تا حرکت تطبیقی
وقتی صحبت از پیادهسازی کنترل تطبیقی بلادرنگ در AGVها میشه، تمام وعدههای تئوریک و آموزشهای دقیق تنها در صورتی ارزش دارن که مدل در محیط واقعی یا شبهواقعی، بتونه در لحظه، تصمیم درست بگیره و بهنرمی و ایمنی، در میان موانع حرکت کنه. در این بخش، دقیقاً همین موضوع بررسی عملکرد مدل Gauss-DNN در شرایط عملیاتی ارزیابی میشود. مدلی که با دادههای کنترل بهینه GPM آموزش دیده، حالا در موقعیتی قرار گرفته که باید بدون محاسبه لحظهای، فقط با مشاهده وضعیت فعلی AGV و محیط، تصمیم کنترلی خودش رو اتخاذ کنه. سؤال کلیدی اینه که آیا این مدل میتونه مثل یک سیستم هوشمند انسانی، نهتنها مسیر ایمن انتخاب کنه، بلکه بهموقع، روان، و بدون رفتاری ناپایدار عمل کند.
سناریوهای شبیهسازیشده: شرایطی نزدیک به دنیای واقعی
برای ارزیابی مدل، مجموعهای از سناریوهای پیچیده در محیط شبیهسازی طراحی شد که هر کدوم بخشی از واقعیتهای صنعتی و شهری رو بازنمایی میکنن:
حرکت در مسیر مستقیم با موانع ایستا در طرفین: این حالت برای تست توانایی حفظ جهت و جلوگیری از انحراف غیرضروری طراحی شده.
عبور از مسیر باریک با مانع متحرک روبهرو: یک سناریوی رایج در انبارها، جایی که ممکنه یک لیفتراک یا چرخدستی از روبهرو در حال نزدیکشدن باشه.
مواجهه با دو مانع متحرک که از جهات مختلف بهصورت متقاطع وارد مسیر میشن: این حالت برای ارزیابی تصمیمگیری تطبیقی و پیشبینی برخورد طراحی شده.
ورود ناگهانی مانع از کنار (عابر یا شی پرتابشده): برای سنجش توانایی واکنش اضطراری مدل.
حرکت در محیط پیچخورده با دیوارهها، ناحیههای بنبست و محدودیت شعاع گردش: برای سنجش رفتار پایداری در شرایط محدود هندسی.
در تمام این سناریوها، مدل Gauss-DNN جایگزین کامل کنترل بهینه عددی شده و فقط با دادههای حسگر مجازی ورودی (موقعیت AGV و موانع)، تصمیمگیری میکنه.
رفتار تطبیقی مدل: هوشمندی حرکتی بدون توقف یا سردرگمی
آنچه در اجرای این سناریوها مشاهده شد، نشاندهندهی بلوغ رفتار کنترلی یادگرفتهشده توسط مدل بود. در مواجهه با مانع متحرک، مدل بدون توقف کامل، مسیر خودش رو بهصورت انحراف نرم تنظیم میکرد؛ یعنی بهجای رفتاری تدافعی و محافظهکارانه، بهصورت پیشدستانه و روان مسیر بهتری رو انتخاب میکرد. این نشان میده که مدل بهجای پاسخ واکنشی (Reactive)، از نوعی درک ضمنی آیندهی نزدیک برخورداره — نتیجهای از آموزش دادههای غنی GPM.
در مسیرهای باریک، AGV تحت کنترل Gauss-DNN بهخوبی تعادل بین نزدیکشدن به مانع و حفظ مسیر بهینه رو رعایت میکرد. یعنی نه بیش از حد محافظهکار بود، نه ریسک بالا داشت. در شرایطی که دو مانع بهصورت همزمان از دو جهت وارد میشدن، مدل توانست نقطه تعادل جدیدی در مسیر حرکت ایجاد کنه، بدون اینکه نیاز به بازطراحی مسیر یا توقف کامل داشته باشه.
حتی در مواجهه با مانعهای ناگهانی، مدل با کاهش نرم سرعت و اصلاح جهت، از برخورد جلوگیری کرد؛ بدون اینکه ربات دچار لرزش، رفتار هیجانی یا مسیر شکسته بشه. این موضوع نشوندهندهی وجود سطحی از پایداری دینامیکی یادگرفتهشده در رفتار مدل بود — یعنی مدل صرفاً خروجی حفظ نکرده، بلکه الگوهای واکنشی را درک کرده.
مقایسه با روشهای کلاسیک: برتری در روانی، سرعت و پایداری
برای بررسی بهتر عملکرد، مدل Gauss-DNN با دو روش رایج دیگر مقایسه شد:
کنترل PID کلاسیک: ساده، سریع، ولی فاقد درک از آینده یا تطبیق با تغییرات غیرخطی
کنترل مبتنی بر قواعد دستی (Rule-Based): قابل پیادهسازی سریع، ولی شکننده و ناسازگار با پیچیدگی
در اکثر سناریوها، PID اگرچه سریع پاسخ میداد، اما در مواجهه با تغییر همزمان چند مانع یا مسیرهای باریک، بهراحتی دچار نوسان یا overshoot میشد. Rule-Based هم در ابتدا خوب عمل میکرد، ولی بهمحض تغییر یک متغیر — مثلاً ورود مانع از کنار یا تغییر زاویه حرکت — کنترل را از دست میداد یا رفتارهای غیرقابلپیشبینی نشان میداد.
در مقابل، Gauss-DNN نهتنها در شرایط نرمال، بلکه در تغییرات لحظهای، پاسخ پیوسته، قابل پیشبینی و با حداقل تأخیر داشت. ربات دچار پرش فرمان، توقف ناگهانی، یا نوسان شدید نشد. این مدل بهخوبی درک کرده بود که چطور در مسیر باقی بماند، سرعت را مدیریت کند و تعادل بین امنیت و کارایی را حفظ کند.
تأخیر تصمیمگیری و امکان اجرای بلادرنگ
یکی از دغدغههای اصلی در سیستمهای هوشمند، سرعت پاسخ است. در این مقاله، زمان تصمیمگیری (Inference Time) برای مدل آموزشدیده در پلتفرمهای سبک، مانند بردهای Jetson Nano و حتی روی PC با قدرت متوسط، کمتر از ۵ میلیثانیه ثبت شده — که کاملاً مناسب برای رباتهای بلادرنگ صنعتی است. برخلاف GPM که برای هر وضعیت باید یک مسئلهی بهینهسازی سنگین حل کند (در حد ثانیهها)، این مدل میتواند در زمان بسیار کم، خروجی بسیار نزدیک به همان سطح دقت تولید کند. این برتری، Gauss-DNN را به یکی از معدود گزینههایی تبدیل میکند که هم دقت و هم زمان پاسخ را توأمان دارد.
جمعبندی: رفتار رباتی که میفهمد، نه فقط اجرا میکند
مدلی که با معماری Gauss-DNN آموزش دیده، در عمل نشان داد که میتواند در محیطهای واقعی، بدون وابستگی به الگوریتمهای سنگین عددی یا تنظیمات سخت، رفتار ایمن، پایدار، و هوشمند ارائه دهد. برخلاف سیستمهایی که فقط عکسالعمل نشان میدهند، این مدل حرکت پیشبینیمحور، تطبیقی و متوازن دارد — دقیقاً همان چیزی که برای حرکت در میان انسانها، وسایل متحرک، و محیطهای صنعتی پویا نیاز است. این معماری، گام بلندی در مسیر واقعیسازی کنترل تطبیقی مبتنی بر یادگیری عمیق برای وسایل خودران صنعتی محسوب میشه و از این منظر، کاملاً آماده برای انتقال از محیط تحقیقاتی به اجرای عملیاتی است.
کاربردهای صنعتی و موقعیتهای پیادهسازی معماری Gauss-DNN
معماری Gauss-DNN بهعنوان یک راهکار ترکیبی مبتنی بر یادگیری عمیق و کنترل بهینه، واجد شاخصههای لازم برای استقرار در طیفی از کاربردهای صنعتی در کلاس AGV (وسایل هدایتشونده خودکار) و AMR (رباتهای متحرک خودران) است. این معماری، با بهرهگیری از دادههای مرجع حاصل از حل دقیق معادلات کنترل بهینه (با روش GPM)، و انتقال آن به فضای یادگیری شبکههای عصبی عمیق، قادر است تصمیمات کنترلی شبهبهینه را در زمانهای کمتر از چند میلیثانیه تولید کند — که نیاز به حل عددی در لحظه ندارد. در این بخش، کاربردهای عملیاتی این معماری در صنایع لجستیک، پزشکی، تولید و حملونقل درونسازمانی مورد تحلیل قرار میگیرند.
۱. سیستمهای AGV در انبارهای چندعامله و محیطهای با ترافیک انسانی
در سامانههای مدیریت انبار با ناوگان رباتیک چندعامله، چالش اصلی، مدیریت همزمان حرکت در حضور موانع ایستا و دینامیک، بدون توقف و با حفظ پایداری مسیر است. معماری Gauss-DNN، با فراهمکردن کنترل بلادرنگ از طریق شبکهای آموزشدیده بر پایه رفتارهای بهینه، میتواند جایگزین الگوریتمهای کلاسیک پرریسک (PID، Rule-based) شود. ویژگیهای کلیدی در این محیطها:
واکنش نرم و پیوسته در برابر رفتارهای انسانی یا حرکت سایر AGVها
قابلیت اجرا بر روی پردازندههای سبک، مناسب برای پیادهسازی کاملاً onboard
حفظ تعادل میان انرژی مصرفی، ایمنی و زمان تکمیل مسیر
۲. سامانههای حملونقل داخلی در تأسیسات درمانی و بیمارستانی
مراکز درمانی نیازمند سیستمهایی هستند که هم از نظر حرکتی پایدار و بیصدا باشند، هم از نظر ایمنی توانایی اجتناب از برخورد در مسیرهای باریک و پویای انسانی را داشته باشند. در این زمینه، Gauss-DNN با کنترل مبتنی بر الگوی یادگرفتهشده از دادههای کنترل بهینه، توانایی تولید رفتارهای آرام، ایمن و پیشبینیپذیر دارد،همچنین وابستگی به کنترل متمرکز یا مسیرهای ثابت ندارد. ویژگی بحرانی در این کاربرد، پیشبینی دقیق واکنش به موانع انسانی با زمان پاسخ پایین است، که در مدل مذکور، با تأخیر کمتر از ۵ میلیثانیه حاصل شده است.
۳. مسیرهای بینسازمانی در محیطهای صنعتی، خطوط مونتاژ و مجتمعهای تولیدی
AGVهایی که در محیطهای نیمهساختیافته (مانند خطوط مونتاژ، فضای باز بین سولهها یا مناطق پرترافیک تجهیزات سنگین) فعالیت میکنند، به یک سیستم کنترل با تطبیقپذیری بالا نیاز دارند. معماری Gauss-DNN، با پایداری حرکتی، انعطاف در مواجهه با اختلالات محیطی و حفظ فرمان شبهبهینه در مسیرهای ترکیبی، قابلیت استقرار در این فضاها را داراست.مهمترین مزیت این معماری در این حوزه، عدم وابستگی به زیرساختهای موقعیتیابی پیچیده (GPS صنعتی، RFID) و قابلیت تصمیمگیری محلی است.
۴. رباتهای تحویل خودران در شهرکهای صنعتی و فضاهای شهری نیمهساختیافته
در پروژههای حمل درونشهری سبک، مانند رباتهای تحویل بسته یا انتقال مواد بین واحدهای صنعتی، رفتار ربات باید هم قابل اطمینان باشد و هم با سنجش بلادرنگ از وضعیت محیط، قابلیت انطباق با تغییرات ناگهانی (مانند عبور رهگذر یا مانع متحرک) را داشته باشد. Gauss-DNN با ایجاد یک نگاشت پایدار از فضای ورودی حسی به فضای فرمان کنترلی، میتواند بدون طراحی مجدد مسیر، انحراف بهینه لحظهای ایجاد کرده و از موانع اجتناب کند. مزیت معماری در این کاربرد، پایداری دینامیکی در حضور اختلال، اجرای local، و عدم نیاز به تنظیمات خاص برای هر محیط جدید است.
نتیجهگیری کاربردی
مدل Gauss-DNN، با ارائه یک کنترلر یادگیرنده و سبک، که قادر است رفتارهای کنترل بهینه را با سرعت بالا و دقت مناسب بازتولید کند، برای محیطهای صنعتی واقعی با محدودیت منابع محاسباتی، شرایط متغیر و نیاز به تصمیمگیری ایمن، یک گزینه مناسب و پیشرفته محسوب میشود. ویژگیهای تعیینکننده این معماری عبارتاند از:
تأخیر پایین (<5ms) در تولید فرمان
استقلال از محاسبات عددی در لحظه
سازگاری با سنسورهای سبک و ارزان (مانند RGB-D یا اولتراسونیک)
مناسب برای پیادهسازی edge یا onboard در رباتهای صنعتی
مزیتهای فنی و مسیر توسعه آینده معماری Gauss-DNN
مدل کنترل تطبیقی پیشنهادی در این مقاله، یک معماری صرفاً ترکیبی از یادگیری و کنترل بهینه نیست؛ بلکه یک چارچوب کاملاً صنعتیشده، ماژولار و مقیاسپذیر برای استقرار رفتار کنترلی در رباتهای متحرک هوشمند بهشمار میرود. این سیستم در عین دقت محاسباتی، از قابلیت اجرای بلادرنگ برخوردار است و نقطهی تلاقی میان محاسبه عددی و اجرای یادگیرندهمحور را محقق میسازد. در ادامه، نوآوریها و برتریهای کلیدی این معماری در قیاس با مدلهای موجود در صنعت تحلیل میشوند.
۱. نوآوری کلیدی: استخراج دانش کنترل بهینه از GPM و فشردهسازی آن در قالب مدل یادگیرنده سبک
در معماری Gauss-DNN، نقطه تمایز بنیادی در نحوهی تلفیق تئوری کنترل بهینه با یادگیری عمیق نهفته است. برخلاف روشهای رایج که یا بهدنبال حل عددی مسئله کنترل بهینه بهصورت بلادرنگ هستند (که بسیار زمانبر است)، یا از سیاستهای یادگیری تقویتی برای اکتشاف و یادگیری رفتار شبهبهینه استفاده میکنند (که هزینه محاسباتی و دادهای بالایی دارد)، این مدل مسیر سوم و بسیار مهندسیتری را در پیش گرفته است.
در این معماری، ابتدا با استفاده از روش Gauss Pseudospectral — یکی از دقیقترین روشهای حل مسائل کنترل بهینه پیوسته — برای مجموعهای متنوع از شرایط اولیه و محیطی، دادههای مرجع (control trajectories) تولید میشود. این دادهها شامل توالی حالت–فرمان هستند که در آنها، کنترل بهینه در برابر قیودی نظیر اجتناب از برخورد، حداقلسازی انرژی یا زمان، بهطور کامل لحاظ شده است.
این دانش، سپس بهجای اجرای مستقیم، در قالب یک شبکه عصبی کاملاً متصل (Fully Connected DNN) با ساختار سبک، کدگذاری میشود. نتیجه آن است که تصمیمگیری کنترلی، از یک مسئله بهینهسازی عددی پیچیده، به یک نگاشت غیرخطی ساده تبدیل میشود — نگاشتی که تنها با یک forward pass در شبکه، و در کسری از میلیثانیه قابل اجراست.
این فرآیند، معادل با فشردهسازی دانش کنترل بهینه در حافظه یک مدل یادگیرنده است. مدل پس از آموزش، دیگر نیازی به تکرار حل بهینهسازی ندارد؛ بلکه از دانشی که از GPM گرفته، بهعنوان الگوی رفتاری در مواجهه با محیطهای پویا بهره میگیرد. این مفهوم، نمایانگر یک تغییر پارادایم در طراحی کنترلکننده برای سیستمهای حرکتی بلادرنگ است.
۲. برتری نسبت به معماریهای متداول در کنترل صنعتی و یادگیری حرکتی
معماری Gauss-DNN از چندین جهت نسبت به روشهای سنتی و حتی پیشرفتهی رایج در کنترل رباتیک، مزیت دارد. برای درک این تفاوت، باید دو منظر «کیفیت کنترلی» و «عملیاتیبودن» را توأماً در نظر گرفت.
در قیاس با کنترلکنندههای کلاسیک (PID، Fuzzy, Rule-Based): این مدل برخلاف روشهای مبتنی بر قوانین ایستا یا پارامترهای تنظیمشده دستی، دارای انعطاف ذاتی در پاسخدهی به شرایط متغیر محیطی است. در مواجهه با رفتارهای دینامیکی و غیرخطی، رفتار این معماری پایدار، نرم، و قابل پیشبینی باقی میماند، در حالیکه PID و مدلهای قاعدهمحور بهسرعت دچار نوسان، اغتشاش یا توقف میشوند.
در مقایسه با کنترل پیشبین مدلمحور (MPC): MPC با وجود عملکرد دقیق، نیازمند حل مسئله بهینهسازی مقید در هر لحظه است که با افزایش ابعاد حالت و محدودیتهای دینامیکی، زمان محاسبه بهطور چشمگیری افزایش مییابد. این امر اجرای بلادرنگ را با محدودیت مواجه میسازد. در حالیکه Gauss-DNN با استفاده از دانش پیشمحاسبهشدهی GPM، این محاسبه را به یک تصمیم لحظهای بدون تأخیر تبدیل میکند.
در برابر سیستمهای یادگیری تقویتی (Reinforcement Learning): RL به تعداد بسیار بالایی از اپیزودهای شبیهسازیشده و تعمیمهای پیچیده نیاز دارد و در بیشتر موارد رفتارهایی ناپایدار یا غیربازگشتپذیر ایجاد میکند. اما در Gauss-DNN، سیاست حرکتی از ابتدا بر پایهی مسیرهای بهینهی تأییدشده شکل میگیرد، که باعث ایجاد رفتاری با بنیان نظری مستحکمتر، قابل تحلیلتر، و قابل تضمینتر میشود.
در مجموع، Gauss-DNN مدل منحصربهفردی را ارائه میدهد که در آن کیفیت کنترل نزدیک به MPC، سرعت اجرا بالاتر از کنترل کلاسیک، و ساختار یادگیرندهای قابل تعمیمتر از RL فراهم شده است — بدون هیچیک از نقاط ضعف رایج آنها.
۳. معماری سبک، قابل استقرار روی سختافزارهای تعبیهشده و پردازشگرهای مرزی (Edge Devices)
یکی از مزایای کلیدی معماری Gauss-DNN، بهینهبودن آن از نظر پیچیدگی محاسباتی و منابع سختافزاری موردنیاز برای اجرا است. درحالیکه اغلب مدلهای یادگیری عمیق برای اجرا نیازمند GPU یا سرورهای پرقدرت هستند، این مدل با طراحی سبک شبکهی عصبی خود، کاملاً قابل استقرار بر روی سیستمهای تعبیهشده مانند:
NVIDIA Jetson Nano / Xavier
Raspberry Pi 4 با شتابدهنده Coral
مینیکامپیوترهای صنعتی x86
حتی برخی پردازندههای ARM با شتابدهنده شبکه عصبی
ساختار شبکه بهگونهای تنظیم شده که فاقد لایههای سنگین مانند convolution یا attention بوده و بهجای آن، بر روی نگاشت غیرفخطی بین بردار حالت محیط و فرمان کنترلی متمرکز است. همچنین با حذف نیاز به پردازش تصویر یا یادگیری online، مصرف حافظه و توان بهحداقل رسیده است. این مزیت سختافزاری باعث میشود این معماری برای پروژههایی با بودجه محدود، فضای فیزیکی کم، یا نیاز به استقلال محاسباتی ربات، کاملاً مناسب باشد. معماری Gauss-DNN در عمل، قابلیت تعبیه شدن بهصورت local در برد کنترل حرکتی AGV را دارد و از این طریق، وابستگی به سیستمهای بیرونی یا ارتباط بلادرنگ را از میان میبرد — عاملی بسیار مهم برای پایداری عملیاتی و کاهش تأخیر.
۴. مسیر توسعهپذیر در جهت سامانههای چندعامله و معماریهای مقیاسپذیر کنترل تطبیقی
با وجود آنکه نسخه فعلی مدل برای کنترل یک ربات منفرد در محیطهای ایستا و دینامیکی طراحی شده، اما معماری Gauss-DNN از نظر ساختار منطقی، بهراحتی قابل تعمیم به سامانههای چندعامله (Multi-Agent Systems)، محیطهای همکاریمحور، و حتی رباتهای هوشمند متصل به زیرساخت V2X است.
چشماندازهای توسعه آتی این معماری شامل:
یکپارچهسازی با سیستمهای موقعیتیابی تطبیقی (SLAM + Gauss-DNN): برای رباتهایی که در محیطهای ناشناخته یا تغییرپذیر حرکت میکنند.
مدلسازی مشارکت در ناوگان رباتیک با بهاشتراکگذاری داده کنترلشده: از طریق پروتکلهای ROS2 یا DDS برای اجرای همزمان رفتارهای همکاریمحور.
اتصال به سیستمهای کنترل بالادستی (Supervisor Systems): که تصمیمگیری سطح مأموریت (Task-Level) را انجام میدهند و Gauss-DNN سطح حرکتی را مدیریت میکند.
پیادهسازی همزمان چند مدل سبکشده Gauss-DNN روی هر ربات با قابلیت سوییچ بین سیاستها: برای انطباق سریع با سناریوهای مختلف (مثلاً محیط شلوغ، مأموریت حساس، ترافیک بالا و…).
در نهایت، این معماری میتواند بهعنوان هستهی کنترلی سطح پایین برای ناوبری بلادرنگ، در چارچوبی گستردهتر از یک سیستم رباتیک هوشمند یکپارچه شود — از خطوط تولید تا ناوگان شهری.
جمعبندی نهایی و مسیر همکاری صنعتی برای پیادهسازی Gauss-DNN
در عصر رباتیک صنعتی و ناوبری هوشمند، جایی که محیطها پویا، پرریسک، و چندعاملهاند، معماریهای کنترلی باید هم هوشمندانه طراحی شوند و هم قابلیت اجرا در شرایط محدود و بلادرنگ را داشته باشند. مدل Gauss-DNN دقیقاً بر اساس همین الزامات شکل گرفته است: تبدیل رفتارهای کنترل بهینه به مدل یادگیرندهای سبک، سریع، تعمیمپذیر و قابلپیادهسازی.
این مدل با ترکیب دادههای حاصل از حل دقیق مسائل کنترل بهینه با ساختار شبکه عصبی ساده و قابل اجرا بر روی سختافزارهای صنعتی سبک، نشان داده که میتوان بدون نیاز به محاسبهی مستمر، در هر لحظه تصمیمهای شبهبهینهای برای حرکت ربات اتخاذ کرد — آن هم در شرایطی که هم موانع دینامیکی و هم محدودیتهای فیزیکی وجود دارند. از منظر صنعتی، Gauss-DNN بهعنوان یک ماژول کنترل سطح پایین (low-level motion controller) میتواند در سامانههای AGV، AMR، رباتهای بیمارستانی، رباتهای تحویلمحور، و سیستمهای حملونقل خودکار داخلی مورد استفاده قرار گیرد. چه در محیطهای انبار و لجستیک، چه در خطوط تولید و چه در شهرکهای دانشگاهی یا کارخانهای، این معماری آمادگی دارد تا بهعنوان «مغز حرکتی ربات» نقشآفرینی کند — مستقل، سریع، و قابل اطمینان.
مزایای استراتژیک برای صنایع داخلی
در پروژههایی که در ایران و منطقه غرب آسیا با چالشهایی مانند محدودیت منابع سختافزاری، عدم وجود زیرساختهای دقیق موقعیتیابی، یا الزامات هزینهای مواجهاند، Gauss-DNN مزیتهای زیر را دارد:
عدم وابستگی به GPUهای گرانقیمت یا زیرساخت محاسباتی مرکزی
قابلیت اجرا روی پردازندههای سبک صنعتی
امکان آموزش اولیه با دادههای شبیهسازیشده و عدم نیاز به جمعآوری دادهی واقعی
پشتیبانی کامل از ROS/ROS2 برای یکپارچگی با ماژولهای موجود
و مهمتر از همه: قابل انتقال، قابل تحلیل، و قابل بومیسازی
پیشنهاد مسیر همکاری یا توسعه سفارشی
اگر شما در حال اجرای پروژهای در یکی از حوزههای زیر هستید:
طراحی سامانه AGV یا AMR برای یک مجموعه صنعتی، انبار یا بیمارستان
توسعه MVP برای سامانه حمل خودکار یا لجستیک داخلی
پیادهسازی رباتهای تحویل سبک در محیطهای بسته یا نیمهباز
یا طراحی ماژول کنترلی با قابلیت انطباق برای سیستمهای ناوبری
ما میتوانیم در کنار شما، مسیر زیر رو با معماری Gauss-DNN اجرا کنیم:
تحلیل نیاز پروژه و استخراج سناریوهای کنترل هدف
تولید دادههای مرجع GPM برای شرایط شما
آموزش اختصاصی شبکه DNN متناسب با نقشه و دینامیک
پیادهسازی مدل روی سختافزار شما (Jetson, Pi, STM32 و…)
تست عملیاتی در محیط واقعی و بهینهسازی بر پایه دادههای تست
با ما تماس بگیرید تا مدل را متناسب با نیازهای شما بومیسازی و اجرایی کنیم.
{kind=link}
بدون نظر