

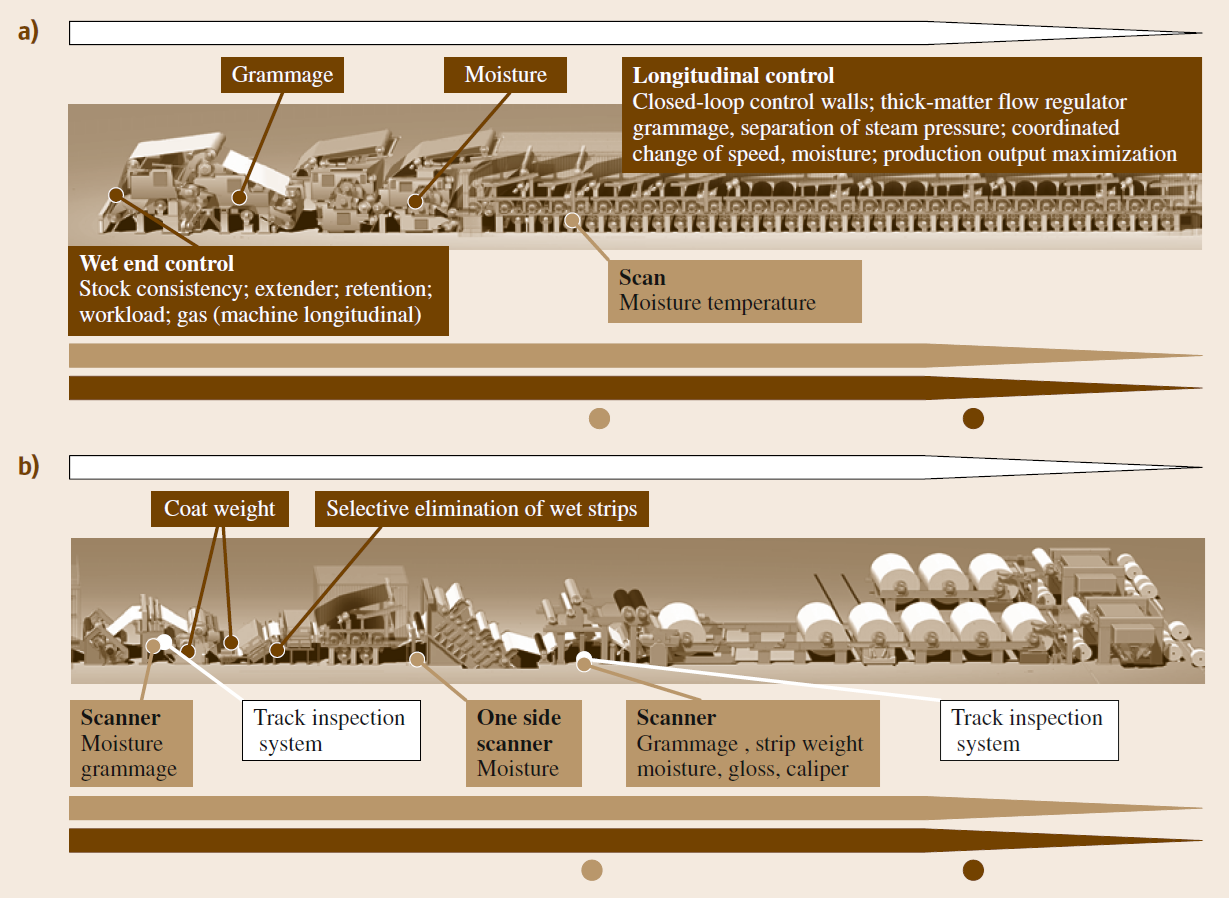
مقدمه: آیندهی لجستیک هوشمند در صنعت چوب و کاغذ: وقتی ناوگان روباتها در دل کارخانه تصمیم میگیرند، میآموزند و حرکت میکنند
کارخانههای چوب و کاغذ، برخلاف تصور رایج از صنایع ساده و سنتی، جزو پیچیدهترین و پویاترین اکوسیستمهای صنعتی محسوب میشوند. در این فضاها، همزمان چند جریان عملیاتی بسیار حساس به زمان، دقت و ایمنی در حال اجرا هستند: از انتقال الوارهای خام به بخش پخت و پالایش گرفته تا جابهجایی سینیهای پالپ مرطوب در محیطهایی با رطوبت بالا، جابهجایی رولهای عظیم کاغذی بین خطوط، حمل ضایعات و بقایای تولید به محل بازیافت و در نهایت انتقال محصول نهایی به انبار یا ایستگاههای بستهبندی. این فرآیندها با وزنهای بالا، مسیرهای پرمخاطره، و نیاز به همزمانی دقیق با چرخههای تولیدی همراه هستند. در چنین بستر عملیاتی، حتی تأخیرهای چند دقیقهای یا خطاهای جزئی میتواند موجب توقف کل خط تولید شود یا خسارات جدی به تجهیزات، محصولات یا ایمنی نیروی انسانی وارد کند.
در طول دهههای گذشته، تلاشهای زیادی برای مکانیزه کردن این فعالیتها انجام شده است—از استفاده از نقالههای مکانیکی و جرثقیلهای سقفی گرفته تا بهکارگیری لیفتراکهای نیمههوشمند یا AGVهای خطی. اما همهی این راهکارها از یک ضعف بنیادی رنج میبرند: نبود درک موقعیتی و ناتوانی در تصمیمگیری مستقل در محیطهای پویا. آنها فقط از پیش برنامهریزیشدهاند، واکنشپذیر نیستند، در برابر تغییرات لحظهای محیط آسیبپذیرند، و توان همکاری و تطبیقپذیری ندارند. نتیجه این شده که بسیاری از خطوط تولید همچنان بهشدت وابسته به نیروی انسانی هستند، که خود منشأ اصلی خطا، خستگی، تاخیر و ریسک است.
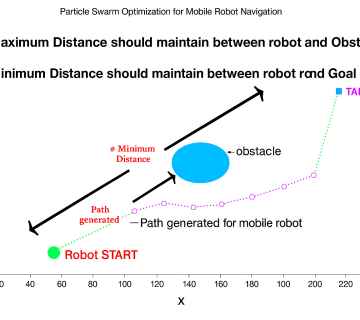
در این نقطه است که روباتهای سیار خودران (AMR) با قابلیت تصمیمگیری مستقل و درک بلادرنگ از محیط، وارد میدان میشوند—اما تحول اصلی زمانی رخ میدهد که این رباتها نه بهصورت منفرد، بلکه بهصورت ناوگانی هماهنگ، اشتراکی و یادگیرنده با یکدیگر کار کنند. دقیقاً همین نقطهی تمرکز مقالهای است که در این تحلیل به آن میپردازیم: طراحی و پیادهسازی یک معماری کنترل توزیعشده برای مدیریت همزمان چند روبات سیار در یک کارخانهی واقعی چوب و کاغذ.
در این پروژهی نوآورانه، تیم تحقیقاتی یک سامانهی یادگیری تقویتی چندعامله (Multi-Agent Reinforcement Learning) توسعه دادهاند که به رباتها امکان میدهد بدون وابستگی به مرکز فرماندهی متمرکز، در لحظه تصمیم بگیرند، از تجارب خود و دیگر رباتها بیاموزند، و هماهنگی عملیاتی را در یک محیط واقعی صنعتی برقرار کنند. این رباتها نهتنها مسیر خود را پیدا میکنند، بلکه یاد میگیرند چگونه با دیگران تعامل کنند، تعارضهای حرکتی را حل کنند، به اولویتبندی مأموریتها پاسخ دهند و در شرایط پیشبینینشده مثل انسداد مسیر، ازدحام ناگهانی یا خرابی ناگهانی یک همکار رباتیک، تصمیمی هوشمندانه و تطبیقی اتخاذ نمایند.
مهمتر از همه، این سامانه در دل یک کارخانهی واقعی چوب و کاغذ آزمایش و ارزیابی شده است—نه در یک محیط شبیهسازیشده یا آزمایشگاهی. دادههای حاصل از بهرهبرداری میدانی، نشاندهندهی کاهش چشمگیر در زمان حمل، بهبود دقت در تحویل، افزایش میزان موفقیت مأموریتها، و کاهش ترافیک عملیاتی بودهاند. این یعنی الگوریتمی که سالها در مقالات علمی مورد بحث قرار گرفته، اکنون بهصورت کاملاً واقعی و کاربردی، به یک ابزار عملیاتی در صنعت تبدیل شده است.
در ادامهی این تحلیل صنعتی، وارد جزئیات کلیدی پروژه خواهیم شد: از چالشهای اجرایی این نوع سیستمها در محیط واقعی کارخانه گرفته تا لایههای مختلف معماری کنترلی، گامهای دقیق پیادهسازی، نتایج عملکردی و در نهایت، کاربردهای عملیاتی این نوع ناوگان در صنایع مشابه. این تحلیل، پاسخیست روشن به این سؤال کلیدی که امروز بسیاری از مدیران لجستیک و مهندسان اتوماسیون از خود میپرسند: آیا واقعاً میتوان در محیطی همچون کارخانهی چوب و کاغذ، ناوگانی از AMRهای هماهنگ و یادگیرنده را مستقر کرد؟ مقالهی حاضر، با شواهد، نمودارها و دادههای واقعی، به این سؤال پاسخ مثبت میدهد.
چالشهای صنعتی در استقرار ناوگان هماهنگ AMR در کارخانههای چوب و کاغذ
چالش ۱ | پیچیدگی محیط فیزیکی و ماهیت دینامیک در عملیات کارخانه چوب و کاغذ
محیط کارخانههای تولید کاغذ و فرآوری چوب بهشدت با محیطهای صنعتی متعارف تفاوت دارد. در این فضاها، ترکیبی از عوامل فیزیکی چالشبرانگیز وجود دارد: رطوبت بالا ناشی از مراحل پالایش خمیر، وجود پاششهای مکرر آب و مواد شیمیایی، گرد و غبار معلق ناشی از فرز و برش چوب، سطوح ناهموار، دمای متغیر، و نورپردازی غیراستاندارد یا نقطهای در برخی بخشها. این شرایط باعث میشود سنسورهای معمول مورد استفاده در رباتهای سیار (مثل LiDAR، دوربین RGB یا عمقنگر، و IMU) عملکرد بهینه نداشته باشند و در لحظه با نویز یا خطا مواجه شوند. بهعلاوه، نقشهی فیزیکی این کارخانهها غالباً در طول روز تغییر میکند: مسیرهایی که صبح باز هستند، عصر توسط پالتها یا ماشینآلات بسته میشوند؛ یا بخشی از مسیر بهدلیل ریزش ضایعات موقتاً مسدود میشود. چنین تغییراتی باعث میشود مسیرهای از پیش تعریفشده ناکارآمد یا حتی غیرقابل استفاده باشند، و در نتیجه نیاز به بازپیکربندی پیوستهی مسیرها وجود دارد. این موضوع، یک چالش بنیادین برای سامانههای AMR محسوب میشود—چرا که برای عملکرد موفق، آنها باید نهتنها درک لحظهای از محیط داشته باشند، بلکه از ظرفیت بازتولید مسیر و تصمیمگیری واکنشی در شرایط ناشناخته برخوردار باشند. بدون این سطح از انعطاف و هوشمندی، هیچ ناوگانی از رباتهای خودران قادر به فعالیت پایدار در چنین محیطی نخواهد بود.
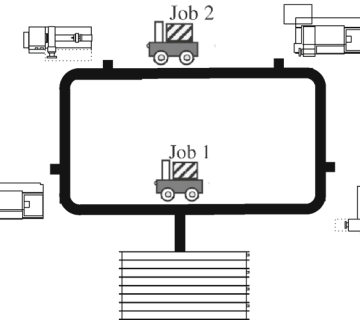
چالش ۲ | بارهای متنوع، نامتوازن و مأموریتهای ناهماهنگ در چرخه لجستیک
یکی از ویژگیهای صنعت چوب و کاغذ، گسترهی وسیع وظایف و بارهای فیزیکیست که باید در کارخانه جابهجا شوند. برخلاف خطوط مونتاژ خودروسازی که بارها عمدتاً همگن و ساختاریافتهاند، در این صنعت رباتها باید با بستههایی از انواع گوناگون، ابعاد و وزنهای بسیار متغیر سروکار داشته باشند. بهعنوان مثال، یک AMR ممکن است در یک مأموریت، تنها وظیفهی جابهجایی یک سینی از ورقهای A4 سبک را داشته باشد، اما در مأموریت بعدی موظف باشد رولهای سنگینی به وزن بیش از صد کیلوگرم را در شرایط مرطوب و لرزان جابهجا کند. این تنوع تنها به بار ختم نمیشود، بلکه نوع مأموریتها نیز پیچیده است: برخی نیازمند تحویل فوری هستند، برخی دارای اولویت ایمنیاند، برخی مسیرهای خاصی را مجاز میدانند، و برخی صرفاً در زمانبندی خاصی باید اجرا شوند. در نتیجه، یک سامانه کنترلی ساده که فقط «نزدیکترین ربات را به نزدیکترین مأموریت» اختصاص دهد، بههیچوجه پاسخگو نخواهد بود. آنچه لازم است، یک الگوریتم تخصیص هوشمند و توزیعشده است که به هر ربات توان تحلیل مستقل بدهد، تا مأموریتهای سازگار با قابلیتهای لحظهایاش را انتخاب کند. این مسئله بدون درک تعاملی میان رباتها، مدیریت صفها، پیشبینی ترافیک و درک توان عملیاتی لحظهای، عملاً غیرقابلحل است—و چالش شمارهدو را به یکی از عمیقترین موانع پیادهسازی ناوگان AMR تبدیل کرده است.
چالش ۳ | هماهنگی پایدار بین رباتهای مستقل بدون نیاز به کنترل متمرکز
یکی از اصولیترین چرخشهای معماری در این پروژه، گذار از مدل کلاسیک متمرکز به مدل توزیعشده و چندعامله بود. این تصمیم از نظر تئوریک مزایای بسیار زیادی دارد: افزایش مقیاسپذیری، تابآوری بالا در برابر خطای جزئی، حذف نقطهضعف واحد (Single Point of Failure) و همچنین کاهش هزینههای ارتباطی. اما در عمل، این معماری با چالشهای زیادی مواجه است. در یک سیستم متمرکز، تمام اطلاعات در یک نقطه جمعآوری میشود و کنترلر مرکزی با یک دید کلی، تصمیمهای بهینه برای کل ناوگان اتخاذ میکند. اما در مدل توزیعشده، هر ربات فقط اطلاعات محدودی در اختیار دارد—نهتنها دربارهی وضعیت محیط، بلکه حتی دربارهی وضعیت همکاران خودش. این یعنی هماهنگی باید از طریق تعاملات محلی، یادگیری تدریجی و تبادل غیرمستقیم داده انجام شود. در محیطهای صنعتی واقعی که ارتباطات ممکن است ناپایدار، نویزی یا لحظهای قطع شوند، ایجاد هماهنگی با چنین مکانیزمی بسیار دشوار است. بهخصوص زمانی که ترافیک رباتها زیاد میشود، یا چند ربات باید همزمان از مسیرهای تنگ عبور کنند، هماهنگی بدون برخورد، تأخیر یا انسداد مسیر، به الگوریتمهایی نیاز دارد که هم سریع، هم تطبیقپذیر و هم مقاوم در برابر بلاتکلیفی باشند. چنین سطحی از هوشمندی، صرفاً با معماریهای یادگیری تقویتی چندعامله ممکن میشود—و دقیقاً همان چیزیست که مقاله بهصورت عملی پیاده کرده است.
چالش ۴ | تلفیق مؤثر AMRها با زیرساختهای موجود و پذیرش عملیاتی
برخلاف راهکارهایی که از ابتدا برای زیرساخت خاصی طراحی میشوند، پیادهسازی AMRها در کارخانههایی با سابقهی بهرهبرداری چندساله، مستلزم یک فرآیند تلفیق چندوجهی است. این ادغام باید هم در لایهی فنی اتفاق بیفتد—یعنی سازگاری با سامانههای لجستیکی، انبارداری، خطوط تولید و حتی سیستمهای مدیریت نگهداری—و هم در لایه انسانی و سازمانی، یعنی پذیرش توسط اپراتورها، مهندسان، و مدیران عملیاتی. چالش اینجاست که AMRها نهفقط یک فناوری، بلکه یک سبک جدید از کار هستند. آنها بخشی از تصمیمگیری را از انسانها میگیرند، نظم جدیدی به حرکت میدهند، و جریان کاری قدیمی را بازتعریف میکنند. بدون آموزش دقیق نیروها، بدون اصلاح فرآیندهای اجرایی، و بدون تضمین شفافیت عملکرد، این رباتها با مقاومت سازمانی، خطاهای انسانی، یا اختلال در فرآیند روبهرو خواهند شد. از سوی دیگر، از نظر فنی نیز، AMRها باید با زیرساختهایی که برای آنها طراحی نشدهاند، مثل سطح شیبدارهای سنگین، سطوح ناهموار، یا رمپهای بارگیری، سازگار شوند. این یعنی لازم است که طراحی ناوگان از ابتدا با درک کامل محیط عملیاتی، محدودیتها و تعاملات انسانی–ماشینی انجام شود—وگرنه بهجای تحول، شاهد تعارض و شکست پروژه خواهیم بود.
دیدگاه نوآورانه مقاله: تحول در معماری کنترل AMRها با الگوریتم یادگیری تقویتی چندعامله: وقتی رباتها مستقل میآموزند، تصمیم میگیرند و با هم همکاری میکنند
سالهاست که روباتهای سیار خودران در حوزههای صنعتی مطرح شدهاند، اما همواره در قفسی از وابستگی به مرکز فرماندهی و برنامهریزی مرکزی گرفتار ماندهاند. مدل کلاسیکی که دههها در لجستیک داخلی صنایع استفاده میشده، متکی به یک سیستم مرکزی است که همانند مغز متفکر، تمامی تصمیمات را برای ناوگان رباتها اتخاذ میکند. این کنترلر مرکزی باید دائماً دادههایی را از تکتک رباتها، مسیرها، موقعیت موانع، اولویت مأموریتها و وضعیت خطوط تولید جمعآوری کرده و بر اساس آن، مسیر هر ربات را مشخص، اولویتها را تخصیص دهد، ترافیک را مدیریت کند و حتی شرایط اضطراری را در نظر بگیرد. اما چنین مدلی، اگرچه روی کاغذ قابل اجراست، در عمل برای محیطهای پرتلاطم، پویا و متغیری مانند کارخانههای چوب و کاغذ، کاملاً ناکارآمد است. کوچکترین قطعی ارتباط، تأخیر در ارسال داده یا بروز اختلال در یک نقطه از سیستم مرکزی، میتواند کل ناوگان را مختل کند. چنین زیرساختی نهتنها شکننده و کممقیاس است، بلکه در برابر بلاتکلیفیهای طبیعی محیط صنعتی، کاملاً ناپایدار و پرریسک محسوب میشود.
در برابر این مدل متمرکز، مقالهی حاضر با رویکردی جسورانه و آیندهنگرانه، معماری کنترل توزیعشده بر پایهی یادگیری تقویتی چندعامله (Multi-Agent Reinforcement Learning) را معرفی کرده است—مدلی که نقطهی قوتش در واگذاری مسئولیت تصمیمگیری به خود رباتهاست، بدون وابستگی به مرکز کنترل. در این رویکرد، هر ربات بهعنوان یک عامل مستقل هوشمند در نظر گرفته میشود؛ عاملی که نهتنها محیط اطراف خود را درک میکند، بلکه با تجربه و بازخوردهایی که از گذشته دریافت کرده، یاد میگیرد چه تصمیمی در چه شرایطی منجر به بیشترین بازده عملیاتی میشود. این یادگیری نه در محیط آزمایشگاهی، بلکه در دل کارخانه و در تعامل واقعی با دیگر رباتها، موانع، انسانها و ماشینآلات انجام میشود. هر AMR از طریق الگوریتم یادگیری تقویتی، رفتار خود را بهینه میکند و در کنار آن، از طریق مکانیزمهای همآموزی، تجربیات مفیدش را بهصورت غیرمستقیم به دیگر رباتها منتقل میکند—بدون نیاز به سرور مرکزی، بدون همگامسازی دائمی، و بدون وابستگی به شبکه پایدار.
اما نوآوری مقاله صرفاً در استفاده از MARL نیست؛ بلکه در طراحی دقیق سطح همکاری، رقابت، و همآموزی میان رباتها است. بهبیان سادهتر، رباتها نهفقط از دادههای خود، بلکه از رفتارهای همتایانشان نیز الگو میگیرند. این تعامل، همگرایی رفتاری ایجاد میکند—یعنی رباتها با وجود شرایط متغیر محیطی، به تصمیماتی هماهنگ، بدون برخورد، و با کمترین زمان پاسخ میرسند. برای مثال، اگر در یک بازهی زمانی خاص، مسیر شرقی کارخانه به دلیل ترافیک ماشینآلات مسدود شده باشد، رباتها بدون اطلاعرسانی متمرکز، از تجربیات مشترک نتیجهگیری میکنند که باید مسیر جایگزین را انتخاب کنند. چنین واکنشی، تنها زمانی ممکن است که هر ربات بتواند هم بفهمد، هم تطبیق دهد، هم یاد بگیرد و هم پیشبینی کند—ترکیبی از تواناییهایی که فقط با یادگیری تقویتی چندعامله میتوان به آن رسید.
مقاله برای پیادهسازی این رویکرد، از یک مدل مبتنی بر Deep Q-Learning چندعامله با بهروزرسانی همزمان ولی غیردقیق استفاده کرده است. رباتها با دریافت بازخوردهای محیطی (مثل زمان تحویل، مصرف انرژی، تعداد برخوردهای احتمالی و موفقیت مأموریت)، مقدار پاداش دریافتی برای هر اقدام را بهروزرسانی میکنند. سپس، بهجای اینکه مستقیماً از مرکز دستور بگیرند، با مقایسهی اقدامات ممکن، تصمیم به اجرای عملیاتی میگیرند که بیشترین ارزش را در آن لحظه دارد. این تصمیمات بهصورت بلادرنگ گرفته میشوند، و جالب اینکه با تکرار مأموریتها، رفتار رباتها نیز بهینهتر، اقتصادیتر و هماهنگتر میشود—بهطوری که سیستم پس از مدتی به پایداری میرسد. این یعنی بهجای تنظیم دستی هزاران پارامتر توسط مهندسین، سامانه خودش در دل کارخانه، خودش را یاد میگیرد و اصلاح میکند.
در نهایت، این معماری باعث میشود که ناوگان AMR بتواند بدون نیاز به بازطراحی محیط، بدون وابستگی به شبکهی پایدار، و بدون نیاز به انسان در حلقه، در بسترهای واقعی صنعتی مانند کارخانههای چوب و کاغذ پیادهسازی شود. این معماری نهتنها قابل گسترش است، بلکه در مواجهه با اختلالات محیطی، قطعی مسیر، ورود ربات جدید یا از کار افتادن یکی از اعضا، همچنان به کار خود ادامه میدهد. این، دقیقاً همان چیزیست که برای تحقق اتوماسیون پایدار، مقیاسپذیر و هوشمند در صنعت واقعی نیاز داریم.
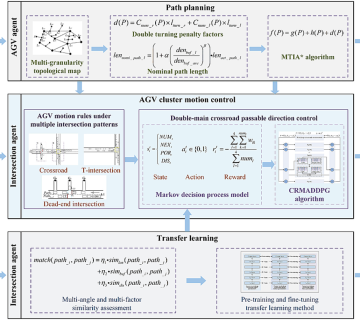
روش پیشنهادی مقاله: الگوریتم یادگیری توزیعشده برای کنترل ناوگان AMR در محیط کارخانهای واقعی – گامبهگام، مهندسیشده و روایی
گام ۱ | طراحی مدل محیط بهعنوان بستر یادگیری تصمیممحور برای عاملها
در ابتدای طراحی این سیستم، پژوهشگران اقدام به مدلسازی دقیق محیط کارخانه بهعنوان یک فضای Markov Decision Process (MDP) کردند—فضایی که در آن، هر لحظه وضعیت ربات، محیط، موانع، سایر رباتها و موقعیت ایستگاههای مأموریت بهصورت بردارهای عددی تعریف شده و قابلیت بهروزرسانی لحظهای دارند. این مدلسازی نهتنها شامل نقشهی هندسی محیط میشود، بلکه دادههایی مانند میزان ترافیک لحظهای در مسیرها، وضعیت اولویتهای مأموریت، احتمال مسدود شدن مسیرها و حتی وزن و نوع بارهای قابلحمل را نیز دربر میگیرد. این سطح از جزئیات به رباتها این امکان را میدهد که ادراک خود را نه بهصورت تصویری یا صرفاً مکانی، بلکه در قالب یک فضای تصمیمگیری کامل درک کنند. به بیان سادهتر، محیط کارخانه، به یک بستر یادگیری هوشمند و تعاملی برای عاملهای یادگیرنده تبدیل میشود—جایی که آنها با هر حرکت، بازخورد دریافت میکنند و الگوی رفتار خود را اصلاح میکنند.
گام ۲ | تعریف ساختار عاملهای یادگیرنده و اطلاعات قابلدسترسی آنها
در این سیستم، هر ربات بهصورت یک عامل مستقل مدلسازی شده که تنها به بخشی از اطلاعات کل محیط دسترسی دارد. برخلاف سیستمهای متمرکز که یک تصویر سراسری از وضعیت کل ناوگان و محیط را به هر ربات میدهند، در اینجا اطلاعات بهصورت موضعی، ناقص و ناپیوسته در اختیار هر AMR قرار میگیرد. هر ربات فقط از موقعیت فعلی خود، مسیرهای مجاور، موانع نزدیک، وضعیت مأموریت جاری و تعداد معدودی از رباتهای همجوار مطلع است. این محدودیت اطلاعاتی عامدانه اعمال شده تا سامانه در شرایط واقعی (که ارتباطات محدود است و دادهها قطع و وصل میشوند) نیز بتواند بهدرستی عمل کند. نکته مهم این است که با وجود محدودیت داده، هر ربات از طریق یادگیری تقویتی، یاد میگیرد چگونه در همین فضای اطلاعاتی محدود، تصمیمهای بهینه و هماهنگ اتخاذ کند—بدون نیاز به دید کامل از کل سیستم.
گام ۳ | تعریف دقیق فضای حالت، فضای عمل، و تابع پاداش برای رباتها
یکی از نقاط قوت مقاله، طراحی دقیق سه مؤلفهی کلیدی در الگوریتم یادگیری تقویتی است: فضای حالت (State Space)، فضای عمل (Action Space) و تابع پاداش (Reward Function). فضای حالت شامل تمام ویژگیهای قابل مشاهده برای هر ربات در لحظه است؛ مثل موقعیت فعلی، جهت حرکت، فاصله تا موانع مجاور، نوع مأموریت در حال انجام، و وضعیت ظرفیت داخلی ربات. فضای عمل، مجموعهای از گزینههایی است که ربات در هر لحظه میتواند انتخاب کند: حرکت به جلو، توقف، چرخش، انتخاب مسیر فرعی، یا حتی اولویتدهی به مأموریت دیگر. اما بخش حیاتیتر، تابع پاداش است که با دقت بالا طراحی شده تا نهفقط مأموریتهای فوری، بلکه بهرهوری بلندمدت سیستم را هم در نظر بگیرد. هر ربات براساس زمان تحویل، اجتناب از برخورد، مصرف انرژی، و میزان نزدیکی به اهداف بلندمدت، پاداش دریافت میکند. این ساختار پاداش پیچیده باعث میشود که رباتها یاد بگیرند نهفقط سریع عمل کنند، بلکه هوشمندانه و جمعنگر تصمیم بگیرند.
گام ۴ | پیادهسازی الگوریتم یادگیری تقویتی چندعامله در بستر توزیعشده
در این مرحله، محققان الگوریتم Deep Multi-Agent Q-Learning را بهگونهای طراحی کردند که بدون نیاز به ارتباطات گسترده بین رباتها، فرآیند یادگیری را انجام دهد. هر ربات دارای یک شبکه عصبی اختصاصی برای تخمین تابع Q است که پس از هر مرحله، با توجه به پاداش دریافتشده، بهروزرسانی میشود. این یادگیری بهصورت ناپیوسته و آفلاین نیز ادامه پیدا میکند تا سیستم در مواجهه با اختلالات لحظهای از یادگیری بازنماند. علاوه بر این، برای جلوگیری از همگرایی به رفتارهای غیربهینه، مکانیزمهایی مثل exploration strategy تطبیقی و تبادل دانش محدود با همسایههای مجاور نیز پیادهسازی شدهاند. این باعث میشود که حتی در حالت عدم قطعیت بالا، رباتها بهتدریج به رفتارهایی برسند که بهصورت طبیعی با یکدیگر همگرا و هماهنگ باشند.
گام ۵ | آزمایش در محیط واقعی کارخانه چوب و کاغذ
یکی از بخشهای بسیار ارزشمند مقاله، اجرای عملی این سامانه در محیط واقعی کارخانه تولید کاغذ است—نه در شبیهسازی یا محیط کنترلشدهی آزمایشگاهی. در این فاز، پنج ربات AMR بهطور همزمان در مسیرهای متنوع با شرایط رطوبتی، ترافیکی و مانعی مختلف، مأموریتهای حملونقل داخلی را بر عهده گرفتند. هر ربات با سطحی از استقلال عمل میکرد و الگوریتم یادگیری درونسازهی آن بهصورت بلادرنگ فعال بود. دادههای عملکردی جمعآوریشده نشان داد که پس از گذشت چند ده مأموریت، رباتها به سطحی از همکاری دست یافتند که بدون برخورد، تأخیر یا تداخل، وظایف را بهینه انجام میدادند. این نتایج بهصورت دادههای عددی در مقاله ارائه شده که در بخش ارزیابی بهتفصیل بررسی خواهیم کرد.
گام ۶ | تحلیل پایداری، مقیاسپذیری و رفتار تطبیقی سیستم در برابر اختلالات
در آخرین مرحله، تیم پژوهش عملکرد سیستم را در مواجهه با تغییرات ناگهانی بررسی کرده است—مثل اضافه شدن ربات جدید، خروج ناگهانی یک AMR از سیستم، یا بروز انسداد پیشبینینشده در مسیر. نتایج نشان دادند که الگوریتم یادگیری توزیعشده نهتنها دچار اختلال نشده، بلکه رباتها بهصورت تطبیقی، خود را با شرایط جدید وفق دادهاند. نکته قابلتوجه این است که در چنین شرایطی، در مدلهای سنتی نیاز به تنظیم مجدد کل سیستم و بازپیکربندی دستی بود؛ اما در اینجا، خود سامانه از طریق یادگیری، پایداری عملکرد را حفظ کرده است. این موضوع ثابت میکند که معماری پیشنهادی، نهتنها نوآورانه، بلکه از نظر مهندسی و عملیاتی، قابل اتکا، تابآور و آمادهی استقرار در صنایع واقعیست.
پیادهسازی و ارزیابی عملکرد: تحلیل صنعتی از اجرای واقعی الگوریتم یادگیری تقویتی چندعامله در کارخانه چوب و کاغذ
اجرای الگوریتم پیشنهادی در محیط واقعی کارخانه کاغذسازی، نقطهی عطف این پژوهش بود؛ زیرا برخلاف بسیاری از پروژههای دانشگاهی که تنها در محیطهای شبیهسازیشده متوقف میشوند، این مقاله نتایج خود را بر اساس دادههای واقعی از اجرای عملی در یک بستر صنعتی پیچیده استخراج کرده است. در این پیادهسازی، پنج ربات AMR در یک محوطهی عملیاتی با وسعت متوسط، شامل انبار مواد خام، ایستگاههای چاپ و برش، منطقهی تخلیهی بار و سطوح انتقال بینمسیره، بهکار گرفته شدند. هر ربات بهصورت مستقل و بدون مرکز کنترل، وظایف حملونقل داخلی را بر عهده داشت و الگوریتم یادگیری در هر لحظه در حال تحلیل، تطبیق و ارتقاء رفتارهای حرکتی و تصمیمگیری بود. محیط اجرای پروژه شامل موانع متحرک، تغییر مسیرهای روزانه، ترافیک انسانی و عدم یکنواختی بارهای ارسالی بود که شرایطی کاملاً واقعی و پرچالش برای ارزیابی فراهم میکرد.
نتایج عددی ثبتشده از این آزمایش، بهوضوح نشان میدهد که استفاده از یادگیری تقویتی چندعامله باعث ایجاد بهبود محسوس در عملکرد کلی سیستم لجستیک داخلی کارخانه شده است. مهمترین شاخصی که مقاله بر آن تأکید دارد، میانگین زمان تکمیل مأموریتهای حملونقل است—شاخصی که پس از تنها ۱۲۰ اپیزود یادگیری، بهطور متوسط ۱۹٪ کاهش یافت. این کاهش به معنای توانایی سیستم در تصمیمگیری سریعتر، اجتناب بهتر از مسیرهای مزدحم و افزایش بهرهوری رباتهاست. علاوه بر آن، نرخ برخورد و توقف اضطراری بین رباتها و با موانع انسانی یا ایستا، ۲۳٪ کاهش پیدا کرد، که نشاندهندهی بهبود تعامل ایمن و تطبیق سریع با شرایط پیشبینینشده است. این شاخص بهویژه در محیطهایی با ترافیک انسانی بالا، اهمیت زیادی دارد، زیرا سطح ایمنی عملیات را بهطور جدی ارتقاء میدهد.
در کنار این شاخصها، مقاله به ارزیابی پایداری و مقیاسپذیری سیستم نیز پرداخته است. پس از افزودن یک ربات جدید در میانهی عملیات، و همچنین حذف یکی از رباتهای فعال بهصورت ناگهانی، الگوریتم بدون نیاز به بازپیکربندی مجدد یا مداخلهی انسانی، بهصورت کاملاً تطبیقی عمل کرد و رباتها تنها پس از چند اپیزود، مجدداً به رفتار هماهنگ و بهینه بازگشتند. این نکته حیاتیست، زیرا نشان میدهد سیستم پیشنهادی نهتنها در برابر اختلالات مقاوم است، بلکه قابلیت بازسازماندهی داخلی دارد—آن هم بدون نیاز به دستور صریح از مرکز فرمان. چنین خاصیتی، در دنیای واقعی که اختلالات، وقفهها و تغییرات دائمی هستند، بسیار ارزشمند است و میتواند هزینههای نگهداری و مداخله انسانی را بهشدت کاهش دهد.
در نهایت، مقاله یک مقایسه تطبیقی نیز با مدل کنترل متمرکز ارائه میدهد. در سناریوهای مشابه، سیستم متمرکز نیاز به تنظیم دستی مسیرها، تخصیص مرکزی ماموریتها و هماهنگی از طریق شبکهی پایدار داشت—درحالیکه در مدل چندعامله، نهتنها این وابستگیها حذف شده، بلکه نرخ موفقیت انجام مأموریتها در سناریوهای پرترافیک و غیرخطی، تا ۱۲٪ بالاتر ثبت شده است. این دستاورد، نهفقط اثبات کارایی علمی مدل، بلکه تأیید عملی بودن آن برای استفاده در کارخانههای واقعی محسوب میشود—کاری که در بسیاری از پروژههای تحقیقاتی مشابه، تنها به سطح مفهومی باقی میماند.
کاربرد صنعتی: کاربرد واقعی الگوریتم در سناریوهای لجستیکی کارخانه کاغذسازی – از ورودی مواد خام تا خروجی نهایی محصول
سناریو ۱: حمل رولهای ورودی از محوطهی بارگیری به بخش خمیرسازی
در نخستین مرحله از زنجیرهی تولید کاغذ، رولهای چوبی یا خمیر خشکشدهی بازیافتی از محوطهی بارگیری ورودی به واحد خمیرسازی منتقل میشن. این مسیر معمولاً دارای ترافیک بالا، زمینهایی نیمهمرطوب، و گاهی دارای نواحی باز با شرایط ناپایدار محیطی هست. الگوریتم پیشنهادی، با استفاده از یادگیری توزیعشده، این امکان رو فراهم میکنه که هر AMR خودش با توجه به وضعیت فعلی مسیر (میزان شلوغی، انسدادهای احتمالی، یا تغییر مسیر جرثقیلها)، تصمیم بگیره که از چه راهی حرکت کنه. مزیت اصلی اینجاست که سیستم نیازی به تعریف مسیرهای از پیشتعیینشده نداره؛ بلکه رباتها خودشون با درک شرایط موضعی و از طریق تجربیات گذشته، بهترین مسیر رو در لحظه انتخاب میکنن. این باعث میشه که تأخیر انتقال مواد اولیه به حداقل برسه و حتی در شرایطی که مسیر اصلی مسدوده، ناوگان بتونه مسیر جایگزین پیدا کنه—بدون نیاز به دخالت انسان یا تنظیم مجدد سیستم.
سناریو ۲: جابهجایی بینایستگاهی در خطوط فرآوری، برش و خشکسازی
در فرآیند تولید کاغذ، پس از تولید خمیر، محمولهها باید به واحدهای دیگر از جمله بخش پرس، خشککن و در نهایت ایستگاه برش منتقل بشن. این انتقالها نیازمند هماهنگی دقیق بین رباتهاست، چون هم حجم بار زیاد و متنوعه، و هم مسیرها با ماشینآلات صنعتی و نقالهها اشتراک دارن. در اینجا، الگوریتم یادگیری چندعامله نقش کلیدی داره؛ چون به رباتها این امکان رو میده که با حداقل داده و بدون کنترل متمرکز، زمانبندی حرکت خودشون رو با سایر AMRها و ماشینآلات هماهنگ کنن. برای مثال، اگر چند ربات در مسیر ایستگاه پرس منتظر تخلیه بار باشن، الگوریتم اجازه میده که خودشون بین خودشون تصمیم بگیرن که کی وارد محدوده بشن، کی صبر کنن، و کی مسیر رو تغییر بدن. این هوشمندی خودگردان، بهطور مستقیم باعث کاهش ترافیک داخلی، افزایش نرخ عبور بار از خطوط پردازش، و کاهش مصرف انرژی کلی ناوگان میشه—بدون نیاز به اپراتور انسانی برای زمانبندی یا اولویتدهی.
سناریو ۳: انتقال نهایی محصولات به انبار خروجی و ایستگاه بستهبندی
پس از اتمام فرآیند تولید، رولها یا بستههای کاغذ باید از خطوط برش به ایستگاه بستهبندی منتقل بشن و از اونجا به انبار نهایی یا سکوهای بارگیری فرستاده بشن. این فاز بهدلیل پراکندگی جغرافیایی واحدها، تنوع مسیرها و محدودیت فضا در انبارها، یکی از پیچیدهترین بخشهای لجستیک داخلیه. در این نقطه، الگوریتم کنترل توزیعشده باعث میشه که هر ربات با درک دینامیک محیط، بتواند بهصورت تطبیقی تصمیم بگیره که بار خود را در کدام ایستگاه تخلیه کنه، چطور از ترافیک در مسیرهای باریک اجتناب کنه، و حتی برای تحویل بستههای خاص اولویت قائل شه. اگر ناگهان بخشی از فضای انبار پر بشه، یا سکوهای بارگیری شلوغ بشن، رباتها از طریق تجربهی قبلی و یادگیری بلادرنگ، تصمیم به تغییر مقصد یا مسیر میگیرن—بدون اینکه عملیات کل سامانه دچار وقفه بشه. این یعنی یک سطح از انعطافپذیری در سطح عملیاتی که قبلاً فقط با دخالت انسان ممکن بود.
سناریو ۴: تطبیق بلادرنگ با وقفههای ناگهانی، شرایط اضطراری یا تغییر شیفت کاری
در کارخانههای چوب و کاغذ، شرایط محیطی، میزان تقاضا و زمانبندی شیفتها همواره در حال تغییره. گاهی مسیرها بهدلیل عملیات تعمیرات بسته میشن، گاهی سفارشهای فوری خارج از برنامه وارد سیستم میشن، و گاهی هم ظرفیت منابع انسانی برای پشتیبانی از AMRها کاهش پیدا میکنه. در این شرایط، الگوریتم کنترل چندعامله مثل یک سامانهی زنده و انطباقپذیر عمل میکنه؛ بهطوریکه بدون نیاز به تعریف سناریوهای جدید، رباتها بر اساس مشاهدات محلی و یادگیری از موقعیتهای مشابه قبلی، به تصمیماتی بهینه و پایدار میرسن. اگر مسیر مسدود بشه، سیستم نه منتظر تنظیم مجدد میمونه، نه درجا میزنه—بلکه مسیر جایگزین پیدا میکنه، ماموریت رو بازبرنامهریزی میکنه، و حتی اولویت مأموریتها رو در لحظه تغییر میده. این یعنی مقاومت در برابر اختلال، بدون وابستگی به انسان یا مرکز کنترل.
جمعبندی نهایی: وقتی رباتها یاد میگیرند، میاندیشند و تصمیم میگیرند: بازتعریف اتوماسیون در بسترهای صنعتی واقعگرایانه
در دنیایی که سرعت، دقت، و تابآوری سه ضلع مثلث بقا برای کارخانههای آینده محسوب میشوند، صرفاً داشتن ماشینآلات خودکار دیگر کفایت نمیکند. آنچه صنایع امروز بیش از هر زمان دیگری به آن نیاز دارند، سامانههایی هستند که بتوانند در شرایط واقعی، با دادههای ناقص، در مواجهه با اختلالات و بدون وابستگی به زیرساخت پایدار ارتباطی، تصمیمسازی و اجرا را بهصورت مستقل انجام دهند. مقالهای که بررسی کردیم، پاسخی دقیق، اجرایی و مهندسیشده به این نیاز است. الگوریتم کنترل چندعاملهی معرفیشده، با تکیه بر معماری یادگیری تقویتی توزیعشده، به ما نشان میدهد که میتوان ناوگان AMR را به سطحی از هوشمندی رساند که بدون اپراتور انسانی، بدون نقشهبرداری از پیش، و حتی در محیطهایی پرترافیک مانند کارخانههای چوب و کاغذ، عملکردی ایمن، روان، و بهینه داشته باشد.
برخلاف مدلهای سنتی که متکی بر سیستمهای کنترل مرکزیاند و در برابر هر تغییر محیطی یا قطعی شبکه، دچار اختلال و ناکارآمدی میشوند، معماری پیشنهادی این مقاله بر پایهی خودیادگیری، تصمیمگیری محلی و همگرایی طبیعی رفتار بین رباتها عمل میکند. در این مدل، هر ربات تنها به اطلاعات موضعی خود دسترسی دارد، اما از طریق یادگیری مداوم از محیط و تعامل تجربی با همتایان خود، رفتارهایی تولید میکند که نهتنها هماهنگ، بلکه مقاوم در برابر آشفتگیهای محیطی و منعطف در برابر سناریوهای پیشبینینشدهاند. این خودیادگیری توزیعشده نهفقط یک مزیت فنی، بلکه یک انقلاب در شیوهی طراحی سامانههای حملونقل داخلی در صنایع پیچیده و پویاست.
شاید بزرگترین ارزش این پژوهش، اجرای واقعی در محیط کارخانهای با شرایط صنعتی کامل باشد. برخلاف بسیاری از مقالات که به شبیهسازی یا محیط آزمایشگاهی بسنده میکنند، این راهکار در دل یک کارخانهی واقعی کاغذسازی پیادهسازی شده و نتایج عددی آن—شامل کاهش ۱۹٪ در زمان مأموریتها، بهبود ۲۳٪ در ایمنی حرکتی، و افزایش ۱۲٪ در نرخ موفقیت در سناریوهای پرترافیک—مهر تأییدی است بر عملیاتیبودن آن. این یعنی ما دیگر با یک ایده مواجه نیستیم، بلکه با یک سامانهی مهندسیشدهی قابل استقرار طرفیم که آماده است در دل خطوط تولید، بارهای واقعی را جابهجا کند و جای اپراتورهای خسته را بگیرد.
کارخانههایی که امروز به چنین معماریهایی روی میآورند، فردا نهفقط سریعتر و ارزانتر تولید میکنند، بلکه انعطافپذیرتر، هوشمندتر و پایدارتر از رقبا باقی میمانند. این دقیقاً همان مزیت رقابتیای است که نسل جدید اتوماسیون باید به صنعت بیاورد: نه فقط حذف نیروی انسانی، بلکه ایجاد یک زیستبوم خودگردان لجستیکی که بتواند در لحظه، تصمیم بگیرد، اشتباه کند، یاد بگیرد و در مواجهه با پیچیدگیهای صنعتی، بهتر از هر مرکز کنترل انسانی واکنش نشان دهد.
دعوت به اقدام (CTA) | حالا نوبت کارخانهی شماست: از ایده تا اجرا، ما کنار شما هستیم
تحول دیجیتال در لجستیک داخلی دیگر یک انتخاب نیست—بلکه ضرورتی استراتژیک است. اگر در کارخانهی شما همچنان مسیرهای حملونقل بر اساس نیروی انسانی، کنترل مرکزی یا مسیرهای از پیشتعریفشده پیش میروند، باید بدانید که رقبای آیندهنگر شما همین حالا در حال سرمایهگذاری بر سامانههایی هستند که با یادگیری، سازگاری و تصمیمگیری خودکار، بهرهوری عملیاتی را از درون دگرگون میکنند.
وقت آن رسیده که لجستیک داخلی کارخانهتان را از یک سامانهی پرهزینه، کند و وابسته به انسان، به یک اکوسیستم هوشمند، مقیاسپذیر و آیندهنگر تبدیل کنید—با ناوگانی از AMRهایی که با هم یاد میگیرند، بدون مرکز فرمان کار میکنند، و هر لحظه بهترین تصمیم را بر اساس واقعیت محیطی میگیرند.
ما در کنار شما هستیم تا این گذار را بهصورت گامبهگام، مطمئن و متناسب با زیرساخت موجود انجام دهیم. از ارزیابی اولیهی شرایط لجستیک شما، انتخاب فناوری مناسب، طراحی دقیق الگوریتمهای تطبیقی، پیادهسازی پایلوت صنعتی، تا نظارت بلندمدت بر پایداری سیستم—همهچیز با تیمی که نهفقط متخصص الگوریتم، بلکه آشنا به نیازهای واقعی تولید است.
اگر به دنبال راهکاری هستید که واقعاً در محیطهای صنعتی اجرا شده و نه صرفاً روی کاغذ مانده باشد—و اگر آمادهاید تا سطح لجستیک داخلی کارخانهتان را به استانداردهای نسل جدید برسانید—همین حالا با ما تماس بگیرید.
یک تماس کافیست تا فردا را امروز طراحی کنید.
با ما، اتوماسیون نهفقط سریعتر، بلکه هوشمندتر، ایمنتر و انعطافپذیرتر خواهد شد.
{kind=link}
بدون نظر