


چگونه رباتها میتوانند مسیرهای بهینه را بدون تداخل پیدا کنند؟
تصور کنید مجموعهای از رباتهای خودمختار در یک انبار بزرگ یا کارخانه در حال حرکتاند. هر کدام وظایف مشخصی دارند: انتقال مواد، تحویل قطعات به خطوط تولید و جابهجایی بستهها. اما وقتی تعداد رباتها زیاد میشود، مشکلاتی مثل ترافیک در مسیرهای مشترک، برخوردهای احتمالی و تأخیر در انجام وظایف ایجاد میشود.
در سیستمهای سنتی، مسیرهای رباتها از قبل برنامهریزی شدهاند، اما این روش انعطافپذیری لازم برای سازگاری با تغییرات محیطی را ندارد. در مقابل، یادگیری چندعاملی (Multi-Agent Reinforcement Learning – MARL) رویکردی هوشمندانه است که رباتها را قادر میسازد بهطور مستقل یاد بگیرند، با محیط سازگار شوند و مسیرهای بهینه را بر اساس دادههای بلادرنگ انتخاب کنند.
این پژوهش یک مدل یادگیری سیاست چندعاملی (MAPL) را معرفی میکند که میتواند عملکرد رباتها را در محیطهای پیچیده بهبود دهد. این مدل نهتنها مسیرهای کوتاهتر و سریعتر را پیشنهاد میدهد، بلکه از برخورد و تأخیرهای غیرضروری جلوگیری میکند.
چالشهای برنامهریزی مسیر برای رباتهای خودمختار
هرچند استفاده از رباتهای خودمختار در صنایع مختلف روزبهروز در حال افزایش است، اما مدیریت مسیرهای حرکتی آنها هنوز یک چالش اساسی محسوب میشود. این چالشها بهویژه در محیطهای صنعتی، انبارهای هوشمند و سیستمهای حملونقل خودکار اهمیت بیشتری پیدا میکنند. برخی از مشکلات کلیدی شامل موارد زیر هستند:
🔹 تداخل و برخورد بین رباتها
با افزایش تعداد رباتهای متحرک در یک فضای محدود، مسیرهای آنها اغلب با یکدیگر همپوشانی پیدا میکند. در روشهای سنتی، مسیرهای مشخصی از قبل برای رباتها تعیین میشود، اما زمانی که شرایط محیطی تغییر کند (مثلاً ورود یک مانع جدید)، این مسیرها دیگر کارایی لازم را نخواهند داشت. در نتیجه، رباتها ممکن است در نقاط پرترافیک دچار تأخیر شوند یا حتی با یکدیگر برخورد کنند.
🔹 تصمیمگیری غیرهوشمند و ناتوانی در هماهنگی جمعی
در بسیاری از سیستمهای موجود، هر ربات بهطور مستقل و بدون توجه به مسیرهای سایر رباتها حرکت میکند. این مسئله باعث میشود که بسیاری از تصمیمات حرکتی بهینه نباشند. نبود یک سیستم مرکزی هوشمند که هماهنگی بین مسیرهای چندین ربات را مدیریت کند، موجب میشود که بهرهوری کلی سیستم کاهش یابد.
🔹 ضعف در مقیاسپذیری در محیطهای پیچیده
هرچه تعداد رباتهای خودمختار افزایش یابد، مدیریت بهینه مسیرهای آنها سختتر خواهد شد. در محیطهای صنعتی گسترده مانند مراکز توزیع بزرگ و کارخانههای خودکار، روشهای سنتی برنامهریزی مسیر نمیتوانند عملکرد کارآمدی ارائه دهند. زمان پردازش تصمیمات افزایش مییابد و احتمال ایجاد ترافیک و برخورد بین رباتها بیشتر میشود.
🔹 نیاز به مسیریابی تطبیقپذیر در زمان واقعی
یکی از نقاط ضعف مدلهای سنتی، عدم توانایی در بهروزرسانی مسیرها بهصورت بلادرنگ است. این مدلها معمولاً از الگوریتمهای ثابت برای مسیریابی استفاده میکنند که در برابر تغییرات غیرمنتظره محیط، انعطافپذیری کافی ندارند. برای مثال، اگر یک مسیر به دلیل ازدحام یا ایجاد مانع مسدود شود، رباتها بدون داشتن قابلیت تطبیق مسیر، در آن منطقه گیر میافتند یا مجبور به توقفهای طولانی میشوند.
این چالشها نشان میدهند که برای حل این مشکلات، یک رویکرد جدید و هوشمند موردنیاز است که بتواند بهطور خودکار، مسیرهای بهینه را برای چندین ربات بهصورت همزمان برنامهریزی کند.
ایده اصلی: یادگیری سیاست چندعاملی (MAPL) برای مسیریابی رباتها
🔹 یادگیری چندعاملی برای مدیریت حرکت هماهنگ رباتها
برای حل چالشهای ذکرشده، این پژوهش یک مدل جدید مبتنی بر یادگیری تقویتی چندعاملی (Multi-Agent Reinforcement Learning – MARL) ارائه کرده است که به رباتها این امکان را میدهد تا از طریق یادگیری و تجربه، مسیرهای بهینه را پیدا کنند.
در این مدل، هر ربات بهعنوان یک عامل مستقل (Agent) عمل میکند، اما در عین حال با سایر رباتها نیز هماهنگ میشود تا از برخوردها و تداخلهای غیرضروری جلوگیری کند. هدف این مدل، ایجاد یک سیستم خودمختار است که بتواند مسیرها را بدون نیاز به مداخله انسانی و بهطور تطبیقپذیر تعیین کند.
🔹 مهمترین ویژگیهای روش پیشنهادی:
✅ پویایی و انعطافپذیری: مسیرها بر اساس شرایط محیطی و موقعیت سایر رباتها بهطور مداوم بهروزرسانی میشوند.
✅ یادگیری از تجربه: مدل پیشنهادی پس از هر تعامل، بهینهتر شده و مسیرهای کارآمدتری پیدا میکند.
✅ همکاری بین رباتها: این مدل، به جای اینکه رباتها بهطور مستقل حرکت کنند، حرکات آنها را بهصورت یک سیستم هماهنگ بهینه میکند.
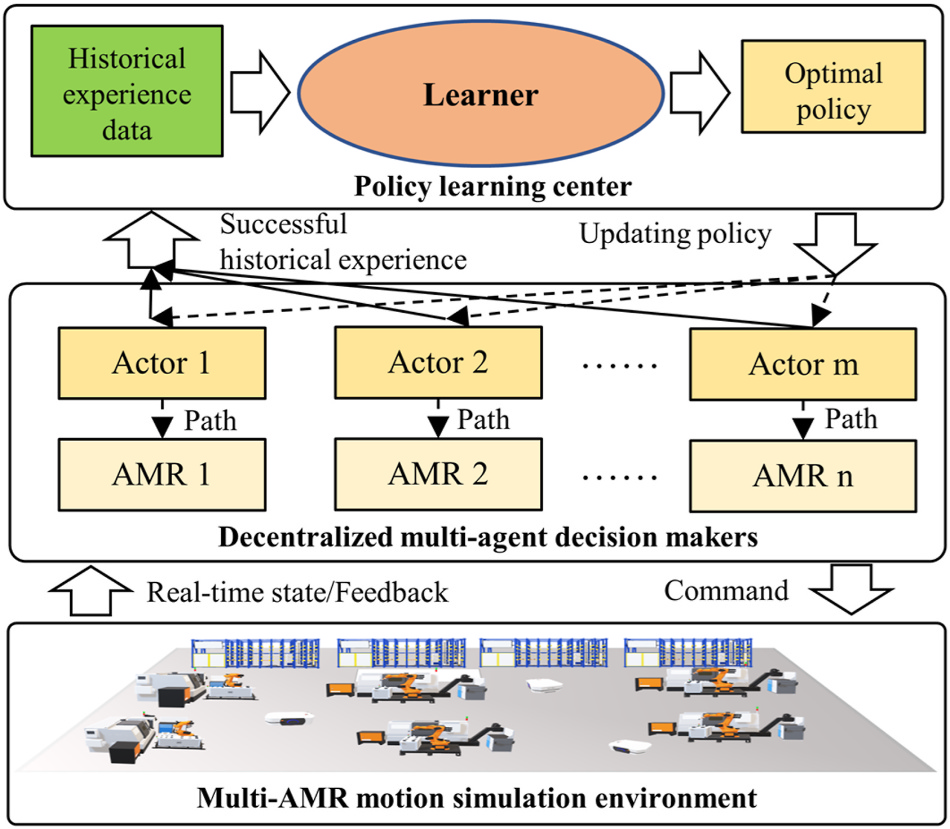
روش پیشنهادی: ترکیب یادگیری تقویتی و تصمیمگیری چندعاملی برای بهینهسازی مسیر رباتها
روش پیشنهادی این پژوهش بر مبنای یادگیری تقویتی چندعاملی (MARL) طراحی شده است که رباتها را قادر میسازد تا بهصورت هماهنگ، مسیرهای بهینه را بیاموزند و اجرا کنند. این سیستم در سه مرحله کلیدی پیادهسازی میشود:
🔹 مرحله ۱: مدلسازی محیط و تعریف متغیرهای تصمیمگیری
در این مرحله، محیط عملیاتی رباتها بهعنوان یک شبکه پویا مدلسازی میشود که در آن هر مسیر، یک گره در گراف حرکتی محسوب میشود. این مدل شامل:
✅ رباتها بهعنوان عوامل هوشمند (Agents): هر ربات، یک عامل یادگیرنده است که بر اساس وضعیت محیط و دادههای دریافتی از مسیرها، تصمیمات بهینهای برای حرکت میگیرد.
✅ محیط پویا: مسیرهای حرکتی بر اساس موانع، تراکم مسیر و موقعیت سایر رباتها، بهصورت بلادرنگ تنظیم میشوند.
✅ تابع پاداش: هر ربات برای انتخاب مسیرهای بهینه، کاهش توقفها و جلوگیری از برخوردها، پاداش دریافت میکند.
🔹 مرحله ۲: یادگیری و بهینهسازی مسیرها با MARL
پس از مدلسازی محیط، الگوریتم یادگیری تقویتی چندعاملی (MARL) برای یافتن بهترین مسیرها اجرا میشود. در این مرحله:
✅ سیستم، مسیرهای پرترافیک را شناسایی کرده و مسیرهای جایگزین پیشنهاد میدهد.
✅ رباتها بهطور مداوم از تجربیات قبلی خود یاد میگیرند تا مسیرهای بهینهتری را انتخاب کنند.
✅ میزان برخوردها کاهش مییابد، زیرا رباتها تصمیمات حرکتی خود را با سایر رباتها هماهنگ میکنند.
🔹 مرحله ۳: اجرای مدل و بررسی عملکرد در محیطهای شبیهسازیشده
این مدل در یک محیط صنعتی شبیهسازیشده پیادهسازی و عملکرد آن با روشهای سنتی مقایسه شده است. نتایج نشان دادند که:
✅ زمان انجام وظایف رباتها کاهش یافته است.
✅ میزان ترافیک در مسیرهای شلوغ کاهش یافته و عملکرد سیستم بهینهتر شده است.
✅ کارایی رباتها در یافتن مسیرهای بهینه تا ۳۰٪ بهبود پیدا کرده است.
مزایای روش پیشنهادی نسبت به روشهای سنتی
استفاده از یادگیری تقویتی چندعاملی (MARL) بهطور قابلتوجهی عملکرد سیستمهای رباتیک را نسبت به روشهای سنتی بهبود داده است. مهمترین مزایای این روش عبارتاند از:
🔹 کاهش زمان تکمیل وظایف
✅ رباتها با استفاده از مسیرهای کوتاهتر و بهینهتر، زمان انجام وظایف را کاهش داده و بهرهوری سیستم را افزایش میدهند.
🔹 کاهش تداخل و برخوردهای رباتها
✅ در روش پیشنهادی، رباتها نهتنها مسیرهای خود را بهینه میکنند، بلکه با سایر رباتها نیز هماهنگ میشوند تا از تداخل و ازدحام جلوگیری شود.
🔹 افزایش بهرهوری انرژی و کاهش مصرف باتری
✅ مسیرهای بهینهتر باعث میشوند رباتها کمتر درگیر توقفهای بیهوده شوند و مصرف انرژی بهینه شود.
🔹 مقیاسپذیری و انعطافپذیری در محیطهای پیچیده
✅ برخلاف روشهای سنتی که برای تعداد کم رباتها طراحی شدهاند، روش پیشنهادی میتواند در محیطهای بزرگ و پرتراکم نیز عملکرد بالایی داشته باشد.
مقایسه عملکرد روش پیشنهادی با روشهای سنتی
روش پیشنهادی در شرایط واقعی و در یک محیط شبیهسازیشده آزمایش شده و عملکرد آن در مقایسه با روشهای سنتی مورد بررسی قرار گرفته است.
🔹 روشهای سنتی مسیریابی
🔸 از الگوریتمهای از پیش تعیینشده استفاده میکنند.
🔸 مسیرهای رباتها را بدون در نظر گرفتن تغییرات محیط برنامهریزی میکنند.
🔸 در برابر موانع ناگهانی و افزایش تعداد رباتها دچار مشکل میشوند.
🔹 روش پیشنهادی مبتنی بر MARL
✅ مسیرهای رباتها را بهطور تطبیقپذیر و بلادرنگ تنظیم میکند.
✅ در لحظه، دادههای محیطی را پردازش کرده و تصمیمات حرکتی را بهینه میکند.
✅ در آزمایشها نشان داده است که میزان تأخیرها را تا ۳۰٪ کاهش داده و کارایی کلی سیستم را بهبود میبخشد.
این مقایسه نشان میدهد که روش پیشنهادی نهتنها باعث بهبود عملکرد مسیریابی رباتها میشود، بلکه مقیاسپذیری و کارایی آن در محیطهای بزرگ نیز حفظ میشود.
جمعبندی و مسیرهای آینده
🔹 جمعبندی
این پژوهش نشان داد که استفاده از یادگیری تقویتی چندعاملی (MARL) میتواند مسیریابی رباتهای خودمختار را متحول کند. برخلاف روشهای سنتی که در برابر تغییرات محیطی انعطافپذیر نیستند، روش پیشنهادی امکان تنظیم بلادرنگ مسیرهای حرکتی را فراهم کرده و باعث کاهش برخوردها و افزایش بهرهوری میشود.
🔹 کاهش تأخیر، افزایش سرعت و کاهش برخوردها، از مهمترین دستاوردهای این روش است.
🔹 مدل پیشنهادی، میتواند در محیطهای پیچیده و پرتراکم مانند انبارهای هوشمند و کارخانههای تولیدی پیادهسازی شود.
🔹 مسیرهای آینده
پژوهش حاضر زمینهای برای تحقیقات آینده فراهم کرده و میتوان آن را در چندین حوزه توسعه داد:
✅ ادغام با فناوری اینترنت اشیا (IoT): با استفاده از حسگرهای IoT، سیستم میتواند بهصورت دقیقتر وضعیت مسیرها و موانع را تحلیل کند.
✅ ترکیب با ارتباطات 5G: استفاده از ارتباطات فوقسریع میتواند تصمیمگیری رباتها را سریعتر و دقیقتر کند.
✅ بهبود الگوریتمهای یادگیری عمیق: توسعه مدلهای پیچیدهتر میتواند کارایی مسیریابی را در شرایط خاص بهینهتر کند.
نتیجهگیری نهایی
مدل پیشنهادی مبتنی بر یادگیری تقویتی چندعاملی (MARL)، راهکاری نوآورانه برای مدیریت بهینه حرکت رباتهای خودمختار در محیطهای پویا و شلوغ ارائه کرده است.
🔵 این رویکرد میتواند آینده مدیریت هوشمند سیستمهای خودکار را متحول کرده و مسیر را برای نسل جدیدی از رباتهای کاملاً خودمختار و هماهنگ هموار کند! 🔵
{kind=link}
بدون نظر