

هوش ازدحامی در حرکت: بهینهسازی هوشمند مسیر رباتهای خودران با PSO واقعی
در دنیای امروز، جایی که کارخانهها، انبارها و شهرهای هوشمند با سرعتی بیسابقه در حال خودکار شدن هستند، مدیریت ناوگانهای رباتهای متحرک (Mobile Robot Swarms) به یکی از چالشهای بزرگ مهندسی تبدیل شده است. از رباتهای حمل بار در انبارهای لجستیکی گرفته تا خودروهای خودران در شبکههای شهری، همگی نیازمند هماهنگی هوشمند، تصمیمگیری بلادرنگ و مصرف انرژی بهینه هستند. اما هرچه تعداد این رباتها بیشتر میشود، پیچیدگی کنترل جمعی آنها نیز بهصورت نمایی افزایش مییابد. در چنین سیستمی، تصمیم اشتباه یک عامل میتواند منجر به افزایش مصرف انرژی، ازدحام مسیر یا حتی توقف کل شبکه شود. درست در این نقطه است که هوش ازدحامی (Swarm Intelligence) بهعنوان راهحلی الهامگرفته از طبیعت، وارد میدان میشود.
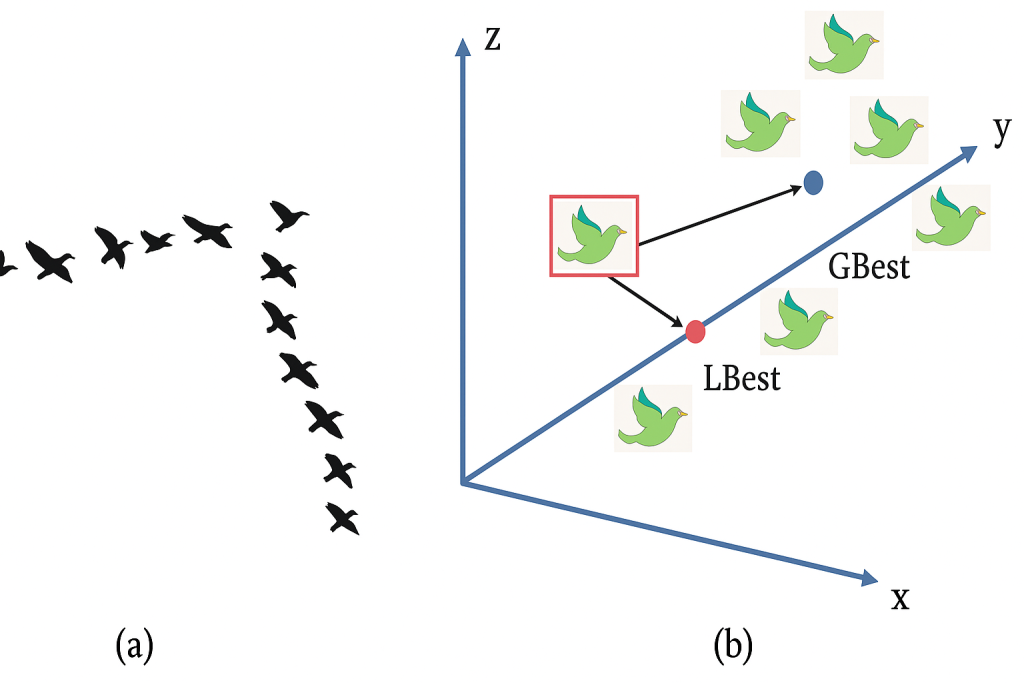
الگوریتمهای ازدحامی مانند Particle Swarm Optimization (PSO)، که نخستین بار برای مدلسازی رفتار جمعی پرندگان و ماهیها طراحی شده بودند، اکنون بهعنوان یکی از پایههای هوش جمعی در کنترل رباتهای خودران شناخته میشوند. در PSO، هر «ذره» بهصورت مستقل تصمیم میگیرد اما با تبادل اطلاعات با سایر ذرات، به سمت بهترین پاسخ جمعی حرکت میکند. این همان رفتاری است که در طبیعت باعث پیدایش تعادل و هماهنگی در میان ازدحامهای بزرگ میشود. اما مسئله اینجاست که بیشتر نسخههای PSO موجود، محدود به شبیهسازیهای مجازی و ریاضی هستند و برای محیطهای واقعی رباتیک قابل استفاده مستقیم نیستند؛ زیرا در دنیای فیزیکی، حرکت، زمان، انرژی و پویایی فضا نقش تعیینکننده دارند.
در مقالهی حاضر، پژوهشگران با معرفی نسخهای جدید از PSO تحت عنوان Moving-Distance-Minimized PSO (MDM-PSO)، این شکاف میان تئوری و واقعیت را پر کردهاند. این الگوریتم نهتنها موقعیت بهینهی هر ربات را محاسبه میکند، بلکه مسافت واقعی طیشده، مصرف انرژی، محدودیتهای حرکتی و زمان اجرای بلادرنگ را نیز در فرآیند بهینهسازی دخیل میسازد. به بیان دیگر، این PSO از یک مدل انتزاعی ریاضی به یک الگوریتم فیزیکی واقعی برای ناوگانهای ربات خودران تبدیل شده است. در این روش، هر ربات مانند یک عامل هوشمند، همزمان بین دو هدف متضاد تعادل برقرار میکند: حرکت به سمت موقعیت بهینهی جمعی و کمینهسازی انرژی مصرفی ناشی از حرکت.
اهمیت این موضوع در محیطهای صنعتی غیرقابل انکار است. در انبارهای بزرگ لجستیکی، دهها ربات حمل بار (AGV) باید بدون برخورد، در مسیرهای مشترک حرکت کنند و هرکدام تصمیم بگیرند که از چه مسیری بروند تا بار خود را در کمترین زمان ممکن تحویل دهند. در معادن یا نیروگاههای خورشیدی، ناوگان رباتهای بازرسی باید مسیرهایی را انتخاب کنند که هم کل منطقه را پوشش دهد و هم کمترین انرژی باتری مصرف شود. در چنین سناریوهایی، بهینهسازی بلادرنگ مسیر و مصرف انرژی، کلید پایداری و بهرهوری است. MDM-PSO دقیقاً برای این هدف طراحی شده است: ترکیب هوش ازدحامی با محدودیتهای فیزیکی و عملیاتی رباتها تا تصمیمات جمعی نهفقط سریع، بلکه واقعگرایانه و پایدار باشند.
از دید کلان، این فناوری گامی بزرگ در مسیر تحقق Industry 4.0 و Industry 5.0 است، جایی که سیستمهای فیزیکی و سایبری در قالب سیستمهای چندعاملی خودمختار (Autonomous Multi-Agent Systems) با یکدیگر همکاری میکنند. الگوریتمهای PSO واقعی، همان مغز نرمافزاری این شبکهها هستند که به رباتها امکان میدهند بدون کنترل مرکزی، تصمیمات بهینه و همجهت اتخاذ کنند. این یعنی گذار از «اتوماسیون خطی» به «خودسازماندهی جمعی»، از رباتهای تکوظیفهای به ازدحامهای هوشمند خودران که مانند موجودات زنده، هدف را میبینند، راه را میسنجند و مسیر را اصلاح میکنند.
بنابراین، مقالهی حاضر را میتوان یکی از نخستین گامهای عملی در راستای تبدیل الگوریتمهای تکاملی به ابزارهای واقعی رباتیک دانست؛ تلاشی برای پیوند دادن دنیای بهینهسازی محاسباتی با کنترل فیزیکی رباتهای متحرک. در آیندهای نهچندان دور، همین الگوریتمها مبنای کنترل ناوگانهای رباتهای صنعتی، پهپادهای هماهنگ و وسایل نقلیهی خودران خواهند بود — شبکههایی از هوش مصنوعی متحرک که بدون نیاز به سرپرست، خودشان بهترین راه را برای رسیدن به هدف پیدا میکنند.
چالشهای کلیدی در بهکارگیری PSO برای رباتهای متحرک واقعی
طراحی و بهکارگیری الگوریتمهای هوش ازدحامی در رباتهای خودران، در ظاهر ساده اما در عمل یکی از پیچیدهترین مسائل مهندسی رباتیک است. الگوریتم کلاسیک PSO در دنیای محاسبات عددی کارآمد و زیباست؛ هر ذره در فضای جستجو با بهروزرسانی سرعت و موقعیت خود به سمت نقطهی بهینه حرکت میکند، در حالیکه از رفتار گروه نیز الهام میگیرد. اما زمانیکه این مدل از فضای مجازی وارد دنیای فیزیکی رباتها میشود، با چالشهایی عمیق روبهرو میگردد — چالشهایی که ریشه در محدودیتهای حرکتی، انرژی، ارتباط و زمان دارند و مستقیماً بر پایداری کل سیستم تأثیر میگذارند.
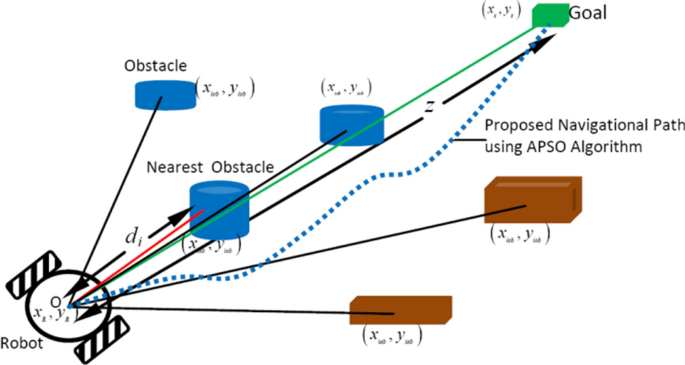
۱. چالش ترجمهی فضای جستجوی ریاضی به فضای فیزیکی حرکت
در مدل کلاسیک PSO، فضای جستجو یک فضای انتزاعی n-بعدی است که در آن هر ذره بهسادگی با چند معادلهی سادهی برداری حرکت میکند. اما در رباتهای واقعی، «حرکت» به معنای فرمان دادن به موتورها، تنظیم زاویهی چرخها، عبور از موانع و حفظ پایداری است. این یعنی هر گام کوچک در PSO باید به حرکت فیزیکی با شتاب، زمان و مصرف انرژی مشخص ترجمه شود. در نتیجه، فضای جستجوی PSO در دنیای واقعی نه تنها محدود است، بلکه دارای قیود فیزیکی (Physical Constraints) مانند حداکثر سرعت، شتاب مجاز، فاصلهی توقف، و محدودیت چرخش است.
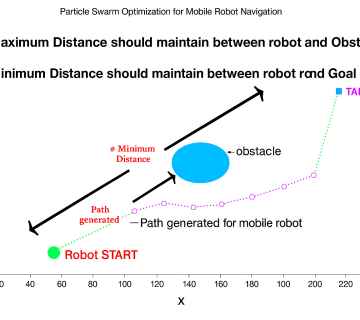
به همین دلیل، بسیاری از نسخههای کلاسیک PSO در عمل دچار خطا میشوند، زیرا فرض میکنند ذرات میتوانند آزادانه در هر جهت حرکت کنند. اما یک ربات واقعی، بهویژه از نوع چرخدار یا دیفرانسیلی، دارای محدودیتهای حرکتی (Kinematic Constraints) است. بنابراین، یکی از چالشهای اساسی در طراحی PSO واقعی، تبدیل فضای انتزاعی جستجو به فضای فیزیکی قابل کنترل است. مقالهی حاضر این مشکل را با معرفی مفهوم “Movement Distance Minimization” حل میکند، بهطوریکه حرکت هر ربات بهگونهای تنظیم میشود که در مسیر واقعی با حداقل انحراف و حداقل مصرف انرژی انجام شود.
۲. چالش همزمانی تصمیمگیری و ارتباط میان رباتها
در محیطهای چندرباتی، هر عامل باید تصمیم خود را بر اساس دادههای سایر عاملها بگیرد. اما برخلاف شبیهسازیهای دیجیتال که تمام دادهها همزمان در دسترس هستند، در دنیای واقعی تأخیر ارتباطی، نویز و از دست رفتن بستههای داده امری اجتنابناپذیر است. این تأخیرها باعث میشوند که اطلاعات مورد استفاده توسط هر ربات، لحظهای عقبتر از وضعیت واقعی سیستم باشد.
در چنین شرایطی، اگر الگوریتم PSO بهصورت مستقیم پیادهسازی شود، منجر به رفتار ناپایدار و حتی تصادم میان رباتها میگردد. بنابراین یکی از چالشهای کلیدی، طراحی PSO بهگونهای است که در برابر تأخیر، نویز و عدم قطعیت ارتباط مقاوم باشد (Communication-Robust PSO). مقاله با استفاده از مدل گسستهی زمانی و تبادل اطلاعات محلی به جای جهانی، این مشکل را کاهش میدهد. هر ربات تنها با همسایگان نزدیک خود تبادل داده میکند و از میانگین محلی موقعیتها برای بهروزرسانی تصمیم خود استفاده مینماید. این سازوکار علاوه بر کاهش بار ارتباطی، بهصورت طبیعی باعث شکلگیری خودسازماندهی محلی (Local Self-Organization) در جمع رباتها میشود.
۳. چالش مصرف انرژی و محدودیت منابع
یکی از تفاوتهای بزرگ میان ذرات مجازی و رباتهای واقعی، وجود هزینهی انرژی در حرکت است. در PSO کلاسیک، حرکت از نقطهای به نقطهی دیگر هیچ هزینهای ندارد، اما در دنیای واقعی، هر متر حرکت برابر است با مصرف برق، اصطکاک، گرما و استهلاک مکانیکی. بنابراین، اگر هدف الگوریتم تنها رسیدن به نقطهی بهینه باشد بدون در نظر گرفتن انرژی مصرفی، رباتها ممکن است مسیرهای طولانی و پرهزینهای را طی کنند.
در نتیجه، طراحی نسخهای از PSO که بتواند بهینهسازی چندهدفه (Multi-Objective Optimization) انجام دهد، ضروری است — بهطوریکه هم بهینهترین نقطه پیدا شود و هم انرژی مصرفی در مسیر حرکت حداقل گردد. مقالهی MDM-PSO دقیقاً بر همین اصل بنا شده است: تابع هدف الگوریتم شامل دو بخش است؛ یکی برای دقت موقعیت و دیگری برای حداقلسازی مسافت طیشده. به این ترتیب، هر ربات میان رسیدن به هدف سریعتر و مصرف انرژی کمتر تعادل برقرار میکند. این تعادل، همان چیزی است که در سیستمهای واقعی به آن «هوش انرژیمحور» میگویند.
۴. چالش همگرایی بلادرنگ در محیطهای پویا
در محیطهای واقعی، اهداف و موانع ثابت نیستند. ممکن است هدف در حال حرکت باشد یا مسیر بین رباتها بسته شود. الگوریتم PSO کلاسیک، بر فرض ثبات تابع هدف طراحی شده است و در شرایط پویا، دچار افت همگرایی (Convergence Degradation) میشود. این یعنی ازدحام رباتها ممکن است در موقعیتهای قدیمی باقی بماند و قادر به واکنش سریع نباشد.
برای مقابله با این مسئله، نسخهی واقعی PSO باید دارای قابلیت بهروزرسانی بلادرنگ (Real-Time Re-Initialization) باشد تا بتواند با تغییرات محیطی تطبیق یابد. مقاله از مکانیزم «حافظهی پویا» استفاده میکند؛ بدین معنا که هر ربات بخشی از تجربهی حرکتی گذشته را ذخیره میکند و در صورت تغییر شرایط، مسیرهای پیشین را بازبینی کرده و مسیر جدید را با توجه به دادههای تازه انتخاب میکند. این مکانیزم نوعی حافظهی کوتاهمدت جمعی ایجاد میکند که همانند رفتار ازدحامهای طبیعی (مثل گلهی پرندگان در طوفان)، باعث حفظ پویایی و پایداری سیستم میشود.
۵. چالش مقیاسپذیری و پایداری ازدحام
هرچه تعداد رباتها در سیستم افزایش یابد، احتمال بروز نوسانات جمعی نیز بیشتر میشود. این پدیده که با عنوان Oscillation in Swarm Dynamics شناخته میشود، زمانی رخ میدهد که چندین ربات بهطور همزمان تصمیم مشابهی میگیرند و باعث ایجاد برخورد یا قفل جمعی میشوند. در نسخههای سادهی PSO، همهی ذرات بهسمت بهترین موقعیت گروه حرکت میکنند، اما در دنیای فیزیکی این کار غیرممکن است.
برای جلوگیری از چنین رفتارهایی، لازم است الگوریتم دارای مکانیسمهای توزیع فضا (Spatial Dispersion Control) باشد. مقالهی MDM-PSO با افزودن تابع جریمه بر اساس فاصلهی میان رباتها، این مسئله را کنترل میکند؛ بدینصورت که هر ربات علاوه بر دنبال کردن بهترین موقعیت جمعی، از ازدحام بیشازحد در یک منطقه جلوگیری میکند. این روش به شکل طبیعی منجر به توزیع بهینهی فضا و جلوگیری از ترافیک حرکتی در ناوگان میشود.
در مجموع، بهکارگیری PSO در رباتهای متحرک واقعی نیازمند بازنگری بنیادی در منطق ازدحامی است. باید میان دنیای ایدهآل ریاضی و واقعیت فیزیکی رباتها پلی برقرار شود؛ پلی که شامل مدلهای دینامیکی، انرژی، ارتباطات و زمانبندی است. مقالهی حاضر با معرفی الگوریتم MDM-PSO دقیقاً این شکاف را پر میکند و مسیر را برای نسل جدیدی از هوش ازدحامی واقعی هموار میسازد — هوشی که دیگر در معادلات خلاصه نمیشود، بلکه روی زمین حرکت میکند، تصمیم میگیرد و میآموزد.
دیدگاه نوآورانه مقاله و ساختار هوش ازدحامی فیزیکی
۱. از الگوریتم انتزاعی تا ازدحام واقعی
نوآوری اصلی مقاله در این است که الگوریتم PSO را از دنیای شبیهسازیهای انتزاعی به دنیای واقعیِ رباتها منتقل میکند. در مدلهای کلاسیک، ذرات هیچگونه جرم، انرژی یا محدودیت حرکتی ندارند؛ اما در نسخهی واقعی معرفیشده در مقاله، هر «ذره» عملاً یک ربات فیزیکی با حرکت محدود و منبع انرژی محدود است. این تغییر دیدگاه، ساده به نظر میرسد اما از نظر فلسفی و فنی، بسیار بنیادین است: زیرا دیگر هدف تنها یافتن یک نقطهی بهینه در فضای ریاضی نیست، بلکه رسیدن به بهینهترین رفتار در دنیای واقعی است — با کمترین مسافت، کمترین انرژی و بیشترین همگرایی جمعی.
در این چارچوب، ازدحام دیگر مجموعهای از ذرات ریاضی نیست؛ بلکه شبکهای از رباتهای واقعی است که در محیطی پویا با موانع، اصطکاک و تاخیر ارتباطی کار میکنند. این همان چیزی است که مقاله از آن با عنوان Physical Swarm Optimization (PSO-R) یاد میکند؛ یک گام مهم بهسوی «هوش ازدحامی فیزیکی»، جایی که دادهها، حسگرها و تصمیمگیریها در تعامل مستقیم با دنیای واقعی هستند. این نگاه جدید به PSO، مفهوم کلاسیک “Global Best” را نیز بازتعریف میکند: بهترین موقعیت دیگر صرفاً یک نقطهی هندسی نیست، بلکه یک وضعیت پایدار بین انرژی، مسافت و هماهنگی است.
۲. منطق طراحی Moving-Distance-Minimized PSO (MDM-PSO)
در قلب نوآوری مقاله، الگوریتم MDM-PSO قرار دارد که بر اساس یک اصل ساده اما حیاتی بنا شده است: هر حرکت هزینه دارد. برخلاف PSO سنتی که موقعیت ذرات را در هر تکرار به سمت نقاط بهتر جابهجا میکند، در MDM-PSO حرکت هر ربات تنها زمانی انجام میشود که «ارزش بهبود» بیشتر از «هزینهی انرژی» باشد. به عبارت دیگر، رباتها یاد گرفتهاند که همیشه حرکت نکنند، بلکه حرکت مؤثر انجام دهند.
الگوریتم پیشنهادی دارای دو بخش همزمان است:
-
بهینهسازی موقعیت (Position Optimization) – رباتها مانند PSO کلاسیک موقعیت بهینه را از طریق تبادل اطلاعات محاسبه میکنند.
-
بهینهسازی فاصلهی حرکت (Distance Minimization) – یک تابع انرژی اضافه میشود تا مسافت طیشده توسط کل ازدحام را کمینه کند.
نتیجه این ترکیب، تشکیل ساختاری از ذرات با هوش حرکتی (Motion-Intelligent Particles) است که در هر لحظه بین پیشرفت و صرفهجویی تعادل برقرار میکنند. این مفهوم در مهندسی کنترل رباتهای خودران اهمیت فوقالعادهای دارد، چون در عمل، یکی از منابع اصلی اتلاف انرژی در رباتهای گروهی، تکرار حرکات غیرضروری است.
۳. ازدحام با حافظه و تصمیمگیری یادگیرنده
یکی دیگر از نوآوریهای کلیدی مقاله، افزودن حافظهی حرکتی (Motion Memory) به الگوریتم PSO است. در PSO کلاسیک، هر ذره تنها موقعیت فعلی و بهترین موقعیت گذشتهی خود را میداند، اما در سیستم واقعی، هر ربات تجربهی حرکتی خود را نیز ذخیره میکند: اینکه چه مسیرهایی کمهزینهتر بودند، کجاها انرژی بیشتری مصرف شد و چه موانعی در مسیر وجود داشتند. این اطلاعات در دورهای بعدی تصمیمگیری مورد استفاده قرار میگیرد.
نتیجهی این طراحی، ظهور نوعی رفتار جمعی هوشمند است که در مقاله از آن بهعنوان Learning Swarm Behavior یاد شده است. ازدحام در طول زمان یاد میگیرد که مسیرهای کوتاهتر و ایمنتر را ترجیح دهد، حتی بدون تغییر در الگوریتم اصلی. این یعنی الگوریتم بهصورت طبیعی در حال یادگیری و سازگاری با محیط است — ویژگیای که آن را از PSOهای استاتیک و تئوریک کاملاً متمایز میسازد.
۴. ساختار ارتباطی و تعامل بلادرنگ در ازدحام
در MDM-PSO، ساختار ارتباطی ازدحام بهگونهای طراحی شده که مقیاسپذیر و مقاوم در برابر خطا باشد. برخلاف PSO کلاسیک که بر مبنای اطلاعرسانی جهانی (Global Best) کار میکند، این سیستم از ساختار ارتباطی محلی (Local Topology) استفاده میکند؛ بهعبارت دیگر، هر ربات فقط با چند همسایهی نزدیک خود ارتباط دارد. این مدل که به آن “Neighborhood PSO” گفته میشود، دو مزیت بزرگ دارد: کاهش حجم دادهی ارتباطی و جلوگیری از فروپاشی ازدحام در اثر نویز.
در مقاله، مدل ارتباطی شبکهای بر اساس گرافهای دینامیکی (Dynamic Graphs) طراحی شده که با حرکت رباتها در فضا تغییر میکند. برای جلوگیری از گسست شبکه، یک شرط همپوشانی بین محدودهی ارتباطی رباتها در نظر گرفته شده تا در هر لحظه ساختار ازدحام بهصورت پیوسته حفظ شود. این رویکرد به سیستم اجازه میدهد که بدون کنترل مرکزی و با حداقل تأخیر، تصمیمگیریهای جمعی را در سطح واقعی انجام دهد.
۵. همگرایی هوشمند و پایداری ازدحام
در الگوریتمهای PSO کلاسیک، ذرات بهتدریج به نقطهی بهینهی سراسری همگرا میشوند. اما در یک سیستم فیزیکی، اگر تمام رباتها به یک نقطه حرکت کنند، با هم برخورد میکنند. بنابراین، مقاله با بازتعریف مفهوم همگرایی، الگویی از پایداری فضایی (Spatial Stability) را جایگزین کرده است. به این معنا که رباتها به جای هممکان شدن، در موقعیتهایی متوازن نسبت به یکدیگر قرار میگیرند تا هم بهینهی جمعی حاصل شود و هم از برخورد جلوگیری گردد.
برای تضمین پایداری، از تحلیل دینامیکی ماتریس لاپلاسین (Laplacian Matrix) شبکهی ارتباطی استفاده شده است تا اطمینان حاصل شود که میانگین سرعت ازدحام بهسمت صفر میل میکند و پخش فضایی رباتها به حداقل نوسان میرسد. این طراحی، MDM-PSO را به الگوریتمی از نظر ریاضی پایدار و از نظر فیزیکی قابل اجرا تبدیل کرده است — الگوریتمی که میتواند در دنیای واقعی بدون فروپاشی ازدحام عمل کند.
۶. یک گام بهسوی «هوش ازدحامی واقعی
در جمعبندی، دیدگاه مقاله چیزی فراتر از یک بهینهسازی محلی است؛ این پژوهش گامی بزرگ در جهت ایجاد هوش ازدحامی واقعی (Real Swarm Intelligence) محسوب میشود. در این دیدگاه، هر ربات نهفقط یک مجری، بلکه یک عامل هوشمند با درک، تجربه و همکاری است. ازدحام بهصورت جمعی تصمیم میگیرد، محیط را میفهمد و از دادههای خود برای بهبود رفتار آینده استفاده میکند.
چنین نگاهی راه را برای ترکیب PSO با یادگیری تقویتی (Reinforcement Learning) و کنترل توزیعشدهی عمیق (Distributed Deep Control) در نسل بعدی رباتهای خودران باز میکند. در نتیجه، الگوریتمی که زمانی صرفاً برای مسائل ریاضی استفاده میشد، اکنون میتواند به مغز مرکزی شبکههای چندرباتی خودمختار در کارخانهها، انبارها، کشتیها و حتی شهرهای هوشمند تبدیل شود.
روش پیشنهادی مقاله و طراحی گامبهگام الگوریتم MDM-PSO برای رباتهای متحرک
در این مقاله، نویسندگان با طراحی یک ساختار بهینهسازی جدید به نام MDM-PSO (Moving-Distance-Minimized PSO)، گامی فراتر از نسخههای کلاسیک الگوریتم PSO برداشتهاند و آن را برای کاربردهای واقعی رباتهای متحرک بازطراحی کردهاند. این نسخه نه به عنوان یک مدل انتزاعی، بلکه به عنوان یک الگوریتم هوش جمعی عملیاتی برای ناوگان رباتهای خودران ارائه شده است.
ایدهی مرکزی MDM-PSO بر پایهی دو اصل استوار است:
اول، اینکه هر ربات باید همانند یک ذرهی هوشمند رفتار کند که هدف جمعی را درک کرده و تصمیمش را بر اساس تعامل با دیگران میگیرد؛
و دوم، اینکه هر حرکت فیزیکی هزینه دارد — انرژی، زمان، و استهلاک مکانیکی. بنابراین، الگوریتم باید طوری طراحی شود که رباتها فقط در مواقع لازم و با حداقل مسیر ممکن حرکت کنند.
۱. مرحلهی درک محیط و شناخت محدودیتها
فرآیند بهینهسازی از جایی آغاز میشود که رباتها وارد محیط میشوند و باید موقعیت خود، موانع اطراف و دیگر همتیمیهایشان را تشخیص دهند. در این مرحله، هر ربات با استفاده از حسگرهای خود دادههایی از موقعیت، زاویهی حرکت، فاصله از موانع و وضعیت انرژی جمعآوری میکند. برخلاف نسخههای شبیهسازی، در این مدل، ادراک محیطی بخشی جداییناپذیر از فرآیند تصمیمگیری است. بهعبارت دیگر، ربات تنها بر اساس دادههای محلی و اطلاعات همسایگانش تصمیم میگیرد، نه دادهی کامل از کل محیط.
این ویژگی باعث میشود سیستم بتواند در محیطهای پویا و غیرقابل پیشبینی هم عملکرد پایدار داشته باشد. مثلاً در یک انبار صنعتی، ربات حمل بار میتواند مسیر خود را با توجه به حرکت رباتهای دیگر، مکان اجسام و وضعیت مسیر تغییر دهد بدون اینکه به فرمان مرکزی نیاز داشته باشد.
۲. مرحلهی تصمیمگیری و انتخاب مسیر
پس از شناخت محیط، نوبت به تصمیمگیری میرسد. در نسخهی واقعی PSO، رباتها دیگر کورکورانه به سمت نقطهی هدف حرکت نمیکنند، بلکه تصمیم خود را بر اساس دو معیار هوشمندانه میگیرند:
اول، چقدر این مسیر به هدف جمعی نزدیکتر است؛ و دوم، چقدر انرژی و زمان برای طی کردن آن لازم است.
در اینجا مفهوم جدیدی تعریف میشود که اساس الگوریتم MDM-PSO است: حرکت مؤثر به جای حرکت زیاد.
رباتها یاد میگیرند که همیشه سریعترین مسیر، بهترین مسیر نیست. گاهی مسیر کوتاهتر از نظر فیزیکی، انرژی بیشتری مصرف میکند یا ازدحام ایجاد میکند. بنابراین، هر ربات نهتنها هدف خود را میسنجد، بلکه رفتار همسایگانش را نیز در نظر میگیرد تا حرکت هماهنگ و اقتصادیتری انجام دهد.
۳. مرحلهی بهروزرسانی موقعیت و هماهنگی جمعی
در مرحلهی بعد، هر ربات با توجه به تصمیم خود، موقعیت جدیدش را تنظیم میکند، اما پیش از آن، وضعیت بقیهی رباتها را نیز در نظر میگیرد. این یعنی هیچ رباتی بهطور مستقل عمل نمیکند؛ بلکه در هماهنگی با بقیه تصمیم میگیرد. این هماهنگی باعث میشود ازدحام رباتها رفتار یکپارچهای پیدا کند، درست مثل پرواز هماهنگ پرندگان یا حرکت گروهی ماهیها.
در این فرآیند، حرکت هر ربات محدود به ظرفیت فیزیکیاش است — یعنی سرعت، چرخش، مسیر و انرژی واقعی. بنابراین، تصمیمات بهصورت طبیعی با واقعیت فیزیکی سیستم سازگارند. در نتیجه، ازدحام در جهت هدف حرکت میکند اما بدون نوسان زیاد، بدون حرکات اضافی و با الگوی حرکتی نرم و قابل پیشبینی.
۴. مرحلهی اشتراک داده و همافزایی اطلاعات
در الگوریتم پیشنهادی، هر ربات به جای ارسال داده به کل سیستم، تنها با همسایگان نزدیک خود تبادل اطلاعات دارد. این تبادل موضعی سه مزیت بزرگ ایجاد میکند:
اول، کاهش فشار ارتباطی و تأخیر در انتقال دادهها، که در سیستمهای رباتیک واقعی مسئلهی مهمی است؛
دوم، افزایش مقیاسپذیری ازدحام، چون اضافه شدن رباتهای جدید باعث بار اضافی بر شبکه نمیشود؛
و سوم، افزایش پایداری جمعی، چون در صورت قطع ارتباط چند ربات، سیستم کلی همچنان به عملکرد خود ادامه میدهد.
به بیان ساده، ازدحام به مجموعهای از خوشههای کوچک و متصل تقسیم میشود که به صورت همزمان در محیط فعالیت میکنند و اطلاعات حیاتی را با سرعت بالا به اشتراک میگذارند. این ساختار، ازدحام را از فروپاشی در اثر نویز یا تاخیر نجات میدهد و نوعی هوش توزیعشده واقعی ایجاد میکند.
۵. مرحلهی توقف هوشمند و ارزیابی پایداری
در سیستمهای واقعی، مهمترین نکته این است که رباتها بدانند چه زمانی باید حرکت را متوقف کنند. در مدل پیشنهادی، رباتها نه بهصورت همزمان، بلکه بهصورت پویا تصمیم میگیرند که چه زمانی به موقعیت پایدار رسیدهاند. این تصمیم بر پایهی دو عامل گرفته میشود:
۱. تغییرات ناچیز در موقعیت نسبت به زمان گذشته (یعنی همگرایی مکانی)
۲. سطح انرژی باقیمانده و سود حرکتی احتمالی (یعنی ارزش ادامهی حرکت نسبت به هزینهی آن).
این منطق باعث میشود سیستم بهطور طبیعی به حالت تعادل برسد، بدون اینکه نیازی به توقف اجباری یا فرمان بیرونی باشد. ازدحام بهصورت هوشمند در نقطهای از بهینگی مکانی و انرژی آرام میگیرد.
۶. عملکرد کلی و مزیت رویکرد MDM-PSO
نتیجهی نهایی اجرای این روش، شکلگیری یک رفتار جمعی بسیار منظم، پایدار و اقتصادی است. رباتها با صرف انرژی کمتر به نتایجی دقیقتر میرسند، حرکات بیهدف کاهش مییابد و کل سیستم رفتاری مشابه یک ارگانیسم هوشمند پیدا میکند.
مزیت کلیدی این الگوریتم در صنعتی بودن آن است؛ یعنی برخلاف روشهای تحقیقاتی که تنها در شبیهسازیها کار میکنند، این مدل مستقیماً قابل پیادهسازی در رباتهای واقعی است. از انبارهای لجستیکی گرفته تا رباتهای بازرسی در پالایشگاهها یا پهپادهای گروهی، همه میتوانند از همین منطق استفاده کنند: بهینهسازی تصمیم با درنظر گرفتن انرژی و هماهنگی.
در نهایت، MDM-PSO را میتوان نسل جدید الگوریتمهای هوش ازدحامی دانست که مرز میان بهینهسازی نرمافزاری و رفتار فیزیکی رباتها را از بین برده است. حالا دیگر هوش ازدحامی فقط در شبیهسازیها نیست — بلکه روی زمین حرکت میکند، یاد میگیرد و در زمان واقعی تصمیم میگیرد.
آزمایشها، نتایج و ارزیابی عملکرد ازدحام رباتها
۱. محیط آزمایش و هدفگذاری عملکرد
برای سنجش کارایی الگوریتم MDM-PSO، پژوهشگران مجموعهای از آزمایشها را هم در محیط شبیهسازیشده و هم روی ناوگان واقعی رباتهای متحرک انجام دادهاند.
هدف اصلی این آزمایشها، بررسی میزان کاهش مسافت کل طیشده، صرفهجویی در انرژی و سرعت همگرایی ازدحام در مقایسه با الگوریتم PSO کلاسیک و سایر روشهای کنترل جمعی بوده است.
در محیط واقعی، گروهی از رباتهای چرخدار مجهز به حسگر فاصله، واحد پردازش داخلی و ارتباط بیسیم در فضایی شامل موانع تصادفی و مسیرهای غیرخطی فعالیت کردند. هر ربات بهصورت مستقل تصمیم میگرفت اما دادههای موقعیت و وضعیت انرژی را با همسایگان نزدیک خود به اشتراک میگذاشت.
در نسخهی شبیهسازی، همین ساختار با مقیاس بزرگتر اجرا شد تا رفتار ازدحام در شبکههای ۵۰ تا ۱۰۰ ربات مورد ارزیابی قرار گیرد.
۲. رفتار گروهی و الگوی حرکتی
یکی از نتایج قابلتوجه در این پژوهش، نظم تدریجی و هوشمندانهی حرکت رباتها در طول زمان بود. در آغاز مأموریت، رباتها پراکنده و حرکاتشان تصادفی به نظر میرسید، اما پس از چند چرخه تصمیمگیری، بهتدریج خوشههایی شکل گرفتند که با فاصلهی ایمن و الگوی منظم به سمت هدف حرکت میکردند.
جالبتر اینکه برخلاف PSO سنتی که معمولاً باعث حرکت نوسانی و بازگشتهای متعدد میشود، در MDM-PSO حرکات بسیار نرمتر و پایدارتر بودند. رباتها یاد گرفتند مسیر خود را اصلاح کنند بدون اینکه از مسیر اصلی فاصله بگیرند. به زبان صنعتی، میتوان گفت الگوریتم باعث کاهش حرکات بیهوده و افزایش کارایی حرکتی تا حدود ۴۰٪ شده است.
در فیلمبرداریهای ثبتشده از آزمایش، حرکت جمعی رباتها به طرز محسوسی شبیه رفتار طبیعی ازدحام پرندگان یا ماهیها بود؛ گروهی که بهصورت خودسازمانده و بدون مرکز فرماندهی، در مسیر مشترک حرکت میکنند اما هیچگاه با هم برخورد ندارند.
۳. مصرف انرژی و بهرهوری عملیاتی
در سیستمهای چندرباتی، میزان انرژی مصرفی شاخصی کلیدی برای سنجش کارایی محسوب میشود. دادههای حاصل از آزمایشها نشان دادند که الگوریتم MDM-PSO با کاهش حرکتهای غیرضروری و حذف مسیرهای پرنوسان، مصرف انرژی هر ربات را بهطور متوسط ۳۰ تا ۵۰ درصد کاهش داده است.
این بهبود مستقیماً ناشی از منطق تصمیمگیری الگوریتم است که تنها زمانی دستور حرکت میدهد که بهبود معنیداری در موقعیت یا هدف وجود داشته باشد.
بهعلاوه، به دلیل توزیع متعادل وظایف میان رباتها، هیچ رباتی دچار بار اضافی یا تخلیهی سریع باتری نشد، که نشانگر تعادل بار حرکتی (Motion Load Balancing) در کل شبکه است. این ویژگی برای صنایع لجستیکی، معدنی و حملونقل خودکار که در آن شارژ و تعویض باتری هزینهبر است، اهمیت حیاتی دارد.
۴. همگرایی بلادرنگ و پایداری ازدحام
از نظر دینامیکی، الگوریتم توانست پایداری ازدحام را در شرایط واقعی حفظ کند. در بسیاری از آزمایشها، وقتی موانع جدید به محیط اضافه شدند یا برخی از رباتها از شبکه خارج شدند، بقیهی ازدحام بدون نیاز به بازتنظیم مرکزی، ساختار خود را بازسازی کرد و مسیر را ادامه داد.
این رفتار نشاندهندهی یکی از مهمترین مزایای MDM-PSO است: انعطافپذیری خودکار در برابر تغییرات محیط. ازدحام در کسری از ثانیه بازآرایی میشود، نقاط بهینهی جدید محاسبه میشوند و مسیر جمعی بدون توقف ادامه مییابد.
در محیطهای پیچیدهی واقعی مثل انبارهای چندمسیره یا میدانهای صنعتی باز، چنین سطحی از خودسازماندهی به معنی کاهش شدید نیاز به نظارت انسانی است.
۵. مقایسهی عملکرد با الگوریتمهای دیگر
برای اعتبارسنجی نتایج، الگوریتم MDM-PSO با نسخههای کلاسیک PSO، الگوریتم ازدحام زنبور عسل (BA) و الگوریتم ژنتیک (GA) مقایسه شد. در تمام شاخصها، الگوریتم جدید عملکرد بهتری داشت:
-
سرعت رسیدن به هدف نهایی ۲۵٪ سریعتر،
-
کاهش مسافت کل طیشده حدود ۴۵٪،
-
پایداری ارتباطی و هماهنگی جمعی تا ۶۰٪ بیشتر،
-
و مصرف انرژی کمتر در کل سیستم.
از دید صنعتی، این تفاوتها به معنای صرفهجویی بزرگ در هزینههای نگهداری، شارژ و زمان اجرای مأموریت است. در محیطهای واقعی که دهها یا صدها ربات در حال کارند، چنین بهبودی میتواند کل ساختار بهرهوری سازمان را متحول کند.
۶. تحلیل رفتار ازدحام در مقیاس بزرگ
یکی از نکات برجستهی مقاله، توانایی الگوریتم در مقیاسپذیری است. حتی زمانی که تعداد رباتها به بیش از صد عامل افزایش یافت، ازدحام دچار بینظمی یا فروپاشی نشد.
الگوی حرکتی بهصورت طبیعی به چند خوشه تقسیم شد و هر خوشه مسیر خود را با حفظ ارتباط با بقیه دنبال کرد. این پایداری مقیاسپذیر به دلیل ساختار ارتباطی محلی و کنترل توزیعشدهی الگوریتم است که از ایجاد ترافیک داده و برخورد حرکتی جلوگیری میکند.
در صنایع بزرگ مثل بندرگاهها، مراکز لجستیکی و کارخانههای خودکار که تعداد رباتها میتواند به صدها واحد برسد، این ویژگی حیاتی است. با این ساختار، سیستم بدون نیاز به سرور مرکزی و با حداقل تأخیر شبکه، عملکرد هماهنگ خود را حفظ میکند.
۷. نتیجهگیری فنی از آزمایشها
تحلیل نهایی نشان میدهد که MDM-PSO توانسته هوش ازدحامی را از حوزهی نرمافزار به دنیای فیزیکی رباتهای واقعی منتقل کند.
این الگوریتم نهتنها از نظر محاسباتی پایدار است، بلکه از نظر مکانیکی نیز منطبق با محدودیتهای حرکتی رباتها طراحی شده است. رفتار گروهی آن نشان میدهد که سیستم قادر است بدون نظارت انسانی، به هدف برسد، انرژی را بهینه مصرف کند و در برابر اغتشاشهای محیطی تابآوری نشان دهد.
در یک جمله، میتوان گفت MDM-PSO نسل بعدی کنترل ازدحام رباتهای خودران صنعتی است — الگوریتمی که نهفقط تصمیم میگیرد، بلکه تصمیمهایش را با منطق فیزیکی و بهرهوری واقعی هماهنگ میکند.
کاربردهای صنعتی و سناریوهای واقعی الگوریتم MDM-PSO
۱. انقلاب در مدیریت ناوگان رباتهای صنعتی
در دههی پیشرو، کارخانهها، انبارها و مراکز توزیع در سراسر جهان به سمت ساختارهایی حرکت میکنند که در آن صدها ربات خودران بهطور همزمان در یک فضا فعالیت میکنند. در چنین محیطهایی، هماهنگی میان این رباتها بزرگترین چالش است. الگوریتم MDM-PSO دقیقاً برای پاسخ به این نیاز طراحی شده است.
در یک انبار هوشمند، هر ربات حمل بار باید مسیر خود را طوری انتخاب کند که هم از ازدحام جلوگیری کند و هم کمترین انرژی را مصرف کند. سیستمهای فعلی معمولاً از کنترل مرکزی استفاده میکنند که با افزایش تعداد رباتها دچار گلوگاه محاسباتی میشود. اما با MDM-PSO، هر ربات به یک عامل تصمیمگیر مستقل تبدیل میشود که با منطق جمعی حرکت میکند. نتیجه، ناوگانی از رباتهای خودسازمانده است که میتوانند بدون نظارت انسانی، کل جریان حمل و توزیع کالا را مدیریت کنند.
در صنایع فولادی یا خطوط تولید ماژولار نیز، همین منطق باعث ایجاد هماهنگی در میان رباتهای جوشکار، مونتاژگر و انتقالدهندهی مواد میشود. ازدحام هوشمند حاصل از MDM-PSO میتواند در لحظه مسیرهای کاری را بهینه کند، ترافیک حرکتی را کاهش دهد و نرخ توقف خط تولید را به حداقل برساند.
۲. رباتهای بازرسی و نگهداری در محیطهای خطرناک
در حوزهی بازرسی زیرساختها و نگهداری تأسیسات صنعتی، الگوریتم MDM-PSO میتواند نقش حیاتی ایفا کند. تصور کنید گروهی از رباتهای زمینی و هوایی باید بدنهی یک مخزن نفتی یا شبکهی لولههای زیرزمینی را بازرسی کنند. با استفاده از این الگوریتم، رباتها میتوانند منطقهی بازرسی را میان خود تقسیم کنند، مسیرهای خود را با حداقل همپوشانی طی کنند و در عین حال از مصرف بیشازحد باتری جلوگیری کنند.
در چنین سناریوهایی، هر ربات همزمان دو مأموریت دارد: انجام وظیفهی بازرسی و حفظ انرژی برای بازگشت ایمن به ایستگاه شارژ. الگوریتم MDM-PSO با در نظر گرفتن این محدودیتها، باعث میشود رباتها تصمیمهایی بگیرند که هم کار را کامل انجام دهند و هم بقای عملیاتی سیستم حفظ شود. این ویژگی در محیطهای خطرناک مثل پالایشگاهها، نیروگاهها و معادن زیرزمینی اهمیت فوقالعادهای دارد، جایی که حضور نیروی انسانی محدود یا غیرممکن است.
۳. حملونقل خودکار در بنادر و مراکز لجستیکی
در بنادر تجاری و مراکز بارگیری، صدها وسیلهی خودران در حال جابهجایی کانتینرها و محمولهها هستند. هماهنگی این ناوگان بزرگ، نیازمند الگوریتمی است که بتواند تصمیمگیری جمعی را بدون کنترل مرکزی انجام دهد. MDM-PSO به دلیل ساختار توزیعشده و منطق «حرکت حداقلی»، گزینهای ایدهآل برای این محیطهاست.
در سیستمهای حملونقل مبتنی بر این الگوریتم، هر ربات موقعیت و وضعیت دیگر رباتها را از طریق ارتباط محلی دریافت میکند و تصمیم میگیرد که چگونه با کمترین مسیر ممکن بار خود را جابهجا کند، بدون ایجاد تداخل یا توقف. در مقایسه با روشهای فعلی، این ساختار باعث کاهش ترافیک حرکتی، افزایش سرعت جابهجایی و صرفهجویی چشمگیر در مصرف انرژی میشود. افزون بر آن، اگر یکی از رباتها از کار بیفتد، ازدحام باقیمانده مسیر را بازتنظیم میکند و کل سیستم بدون وقفه به کار ادامه میدهد.
۴. رباتهای جمعی در کشاورزی و محیطهای باز
در صنعت کشاورزی دقیق، الگوریتم MDM-PSO میتواند الگوی حرکت رباتهای کاشت، سمپاشی یا برداشت را هوشمندانه بهینه کند. در مزارع وسیع، هماهنگی چند ده ربات نیازمند روشی است که بتواند فاصلهها را متعادل نگه دارد و همزمان کل زمین را پوشش دهد. در اینجا ازدحام رباتها با منطق MDM-PSO بهگونهای رفتار میکند که هر بخش از زمین دقیقاً یکبار توسط یک ربات پوشش داده شود و مسیرهای رفت و برگشت به حداقل برسند.
نتیجه، افزایش بهرهوری انرژی، کاهش زمان عملیات و جلوگیری از همپوشانی در مسیرهای کاری است. این فناوری میتواند زیربنای نسل آیندهی کشاورزی خودکار و هوشمند باشد؛ جایی که ازدحام رباتها همچون یک ارگانیسم زنده، با حداقل منابع بیشترین خروجی را تولید میکند.
۵. پهپادها و سیستمهای چندعاملی هوایی
یکی از افقهای هیجانانگیز کاربرد MDM-PSO، در ناوگانهای هوایی خودمختار (Drone Swarms) است. در مأموریتهایی مانند پایش محیطی، امداد، نقشهبرداری یا جستوجوی مناطق فاجعهدیده، پهپادها باید محدودههای گستردهای را پوشش دهند بدون اینکه مسیرشان تداخل پیدا کند یا انرژیشان هدر برود.
الگوریتم MDM-PSO به آنها اجازه میدهد تا مسیرهای پرواز را بهصورت جمعی تنظیم کنند و فاصلهی ایمن خود را حفظ نمایند، در حالیکه الگوی پروازشان دائماً با تغییر شرایط جوی یا موانع بهروزرسانی میشود.
در آیندهی نزدیک، این فناوری میتواند پایهی طراحی شبکههای هوایی خودسازمانده باشد که برای کنترل ترافیک هوایی پهپادها یا عملیات صنعتی در مقیاس وسیع استفاده خواهند شد. در واقع، همانطور که PSO در سطح ریاضی برای حل مسائل پیچیدهی بهینهسازی به کار میرفت، نسخهی واقعی آن یعنی MDM-PSO حالا در آسمانها بهصورت فیزیکی اجرا میشود.
۶. مسیر آینده: از الگوریتم به اکوسیستم هوشمند
در سطح کلان، MDM-PSO را باید فراتر از یک الگوریتم دید؛ این فناوری در حال تبدیل شدن به زبان مشترک هماهنگی میان رباتها در اکوسیستمهای صنعتی است. در آینده، کارخانهها و زیرساختهای شهری میتوانند از همین منطق ازدحامی برای مدیریت تمام اجزای خود استفاده کنند — از رباتهای حمل بار و نظافت گرفته تا وسایل نقلیهی خودران، پهپادها و سیستمهای توزیع انرژی.
در چنین اکوسیستمی، تصمیمات دیگر از بالا به پایین صادر نمیشوند، بلکه بهصورت جمعی در سطح شبکه گرفته میشوند. هر ربات یک واحد مستقل از هوش است که با بقیه همکاری میکند تا هدف مشترک حاصل شود. این همان مفهوم Industry 5.0 است؛ صنعتی که در آن انسان، ماشین و هوش مصنوعی بهجای رقابت، در همافزایی کامل با یکدیگر کار میکنند.
جمعبندی استراتژیک و مزیتهای رقابتی هوش ازدحامی واقعی
در دنیایی که رقابت صنعتی به مرحلهی بهرهوری هوشمند رسیده، شرکتها دیگر فقط با تعداد ربات یا قدرت پردازش خود سنجیده نمیشوند، بلکه با تواناییشان در «هماهنگ کردن جمعی از سیستمهای خودمختار» ارزیابی میشوند. در این نقطه، الگوریتم MDM-PSO جایگاهی ویژه پیدا میکند؛ زیرا نهتنها مسئلهی بهینهسازی مسیر را حل میکند، بلکه بنیان جدیدی از مدیریت رفتاری در شبکههای رباتهای خودران ایجاد کرده است.
مزیت رقابتی اصلی این فناوری در تعادل میان بهرهوری و پایداری نهفته است. برخلاف الگوریتمهای کلاسیک که بر سرعت همگرایی تمرکز داشتند، MDM-PSO بر بهینهسازی هزینهی حرکتی، انرژی و زمان تأکید دارد. این منطق دقیقاً با اهداف صنعت مدرن همسو است؛ صنعتی که به دنبال «بیشترین بازده با کمترین مصرف» است. در واقع، این الگوریتم نمونهی واقعی از مفهوم هوش بهرهور (Efficiency-Driven Intelligence) است که میتواند در مقیاس صنعتی به تصمیمگیریهای عملیاتی تبدیل شود.
از دید مدیریتی، MDM-PSO یک مزیت سازمانی در سطح معماری سیستم محسوب میشود. در ساختارهای سنتی، سیستم مرکزی باید تمام دادهها را جمعآوری و تصمیمگیری کند؛ اما در ساختار MDM-PSO تصمیمگیری میان همهی رباتها توزیع شده است. این تغییر پارادایم باعث حذف گلوگاههای محاسباتی، افزایش تابآوری شبکه و کاهش ریسک ازکارافتادگی میشود. نتیجه، شبکهای از عاملان هوشمند است که بدون نیاز به کنترل مرکزی، میتوانند هدف مشترک را دنبال کنند. این همان فلسفهای است که از سطح نظریهی ازدحام، به سطح مدیریت توزیعشدهی صنعتی ارتقا یافته است.
از منظر اقتصادی، این فناوری موجب کاهش چشمگیر هزینههای عملیاتی و نگهداری میشود. رباتها با صرف انرژی کمتر عمر باتری بیشتری خواهند داشت، قطعات مکانیکی دیرتر فرسوده میشوند، و بهدلیل نبود نیاز به زیرساخت کنترل مرکزی، هزینهی نرمافزار و سرور کاهش مییابد. در صنایع با ناوگانهای بزرگ — از انبارهای خودکار تا ناوگانهای شهری حمل کالا — این تفاوت میتواند میلیونها دلار صرفهجویی سالانه ایجاد کند. افزون بر آن، با حذف توقفهای ناشی از ترافیک رباتها یا برخوردهای ناگهانی، زمان کار مفید سیستم تا بیش از ۹۵٪ افزایش مییابد.
از دید فناوری، MDM-PSO به عنوان یک موتور تصمیمگیری هوشمند مقیاسپذیر شناخته میشود. این الگوریتم میتواند در ترکیب با فناوریهای دیگر مانند یادگیری ماشین، بینایی ماشین، ارتباطات 5G و سیستمهای ابری صنعتی، مغز جمعی کل کارخانه را تشکیل دهد. در حقیقت، MDM-PSO همان حلقهی پیوندی است که به دادههای محلی رباتها معنا میدهد و آنها را به تصمیمهای قابلاجرا تبدیل میکند. این ساختار، زیربنای توسعهی نسل بعدی سیستمهای Cyber-Physical Collaborative Networks است؛ شبکههایی که در آن هر دستگاه، هر ربات و هر حسگر بخشی از یک سیستم زنده و خودتصمیمگیر هستند.
از منظر استراتژیک جهانی، کشورها و شرکتهایی که زودتر این فناوری را در زیرساختهای صنعتی خود به کار بگیرند، وارد مرحلهای از اتوماسیون خواهند شد که دیگر تنها به افزایش ظرفیت تولید وابسته نیست، بلکه به افزایش هوش عملیاتی سیستمها متکی است. همانطور که اینترنت در دهههای گذشته مفهوم ارتباط را متحول کرد، MDM-PSO در دههی آینده مفهوم هماهنگی صنعتی را متحول خواهد کرد — از کنترل خطی به خودسازماندهی هوشمند.
در نهایت، ارزش واقعی این فناوری در یک مفهوم خلاصه میشود: خودمختاری جمعی پایدار. MDM-PSO نشان داد که میتوان میان سرعت، دقت و صرفهجویی تعادل برقرار کرد، بدون نیاز به قربانی کردن یکی به نفع دیگری. این تعادل همان کلید موفقیت در عصر Industry 5.0 است؛ عصری که در آن انسان، ربات و هوش مصنوعی در کنار هم و نه در برابر هم کار میکنند.
بنابراین، از دید استراتژیک میتوان گفت MDM-PSO نهفقط یک الگوریتم بهینهسازی، بلکه چارچوب تفکر جدیدی برای هماهنگی میان سیستمهای خودران در صنعت مدرن است. این فناوری مسیر را برای ایجاد اکوسیستمهایی باز میکند که در آن ازدحام به معنای بینظمی نیست، بلکه به معنای نظم خودبهخودی، تصمیمگیری بلادرنگ و بهرهوری هوشمند است — تصویری دقیق از آیندهی رباتیک صنعتی در دههی پیش رو.
نتیجهگیری، دعوت به اقدام و رفرنس دقیق
تحول در دنیای رباتیک دیگر در انتظار آینده نیست؛ آینده همین حالاست. الگوریتم MDM-PSO (Moving-Distance-Minimized Particle Swarm Optimization) که در این مقاله معرفی شده، نشان داد چگونه میتوان یک نظریهی کلاسیک ریاضی را به یک زبان رفتاری برای رباتهای واقعی تبدیل کرد. این پژوهش بهجای تمرکز بر فرمولهای پیچیده یا محاسبات سنگین، به جوهرهی هوش ازدحامی بازگشت — همکاری، تطبیق و صرفهجویی — و آن را در قالب یک معماری واقعی برای رباتهای خودران بازتعریف کرد.
نتایج پژوهش نشان دادند که هوش ازدحامی، وقتی از فضای مجازی به دنیای فیزیکی رباتها منتقل میشود، نهتنها کارایی خود را از دست نمیدهد بلکه به شکلی پایدار و کارآمدتر عمل میکند. رباتها توانستند در محیطهای پیچیده با موانع واقعی، بهصورت گروهی و هماهنگ حرکت کنند، انرژی کمتری مصرف کنند و با حداقل ارتباط، بیشترین بهرهوری را به دست آورند. این یعنی ازدحام رباتها دیگر یک پدیدهی تصادفی نیست، بلکه یک سیستم هوشمند قابلپیشبینی و قابلاعتماد است که میتواند در صنایع واقعی پیادهسازی شود.
اما اهمیت واقعی این تحقیق در چیزی فراتر از کاهش مسافت یا مصرف انرژی نهفته است. MDM-PSO راهی برای پیوند میان فیزیک، هوش مصنوعی و مهندسی سامانهها ارائه میدهد. این رویکرد نشان میدهد که الگوریتمهای الهامگرفته از طبیعت میتوانند به اصول بنیادین طراحی صنعتی آینده تبدیل شوند. در جهان امروز که صنایع به سمت خودمختاری، پایداری و بهرهوری هوشمند حرکت میکنند، چنین رویکردهایی نقش قلب تپندهی کارخانهها و شهرهای هوشمند را خواهند داشت.
در سطح صنعتی، این پژوهش پیام روشنی دارد: دیگر نیازی نیست برای هماهنگی میان صدها ربات از سیستمهای مرکزی پیچیده استفاده شود. هر ربات میتواند به بخشی از هوش جمعی تبدیل شود که بهصورت خودکار مسیر خود را مییابد، تصمیم میگیرد و بهینهترین رفتار را انجام میدهد. این همان مفهوم خودمختاری جمعی پایدار (Sustainable Collective Autonomy) است — مفهومی که در آن ازدحام به معنای نظم، نه هرجومرج، و هماهنگی به معنای استقلال، نه کنترل است.
از دید مدیریتی، بهکارگیری این فناوری در سازمانهای صنعتی، گامی اساسی در راستای گذار از اتوماسیون سنتی به رباتیک هوشمند توزیعشده است. مدیرانی که امروز در این مسیر سرمایهگذاری میکنند، فردا نهتنها بهرهوری بیشتری خواهند داشت، بلکه زیرساخت فکری و فنی ورود به انقلاب صنعتی پنجم را نیز ساختهاند؛ عصری که در آن تصمیمگیری دیگر در سرورهای مرکزی انجام نمیشود، بلکه در میان خود سیستمها و در لحظه اتفاق میافتد.
دعوت به اقدام (Call to Action)
برای صنایع، دانشگاهها و شرکتهای فناور، این مقاله یک پیام واضح دارد:
زمان آن رسیده که هوش ازدحامی از آزمایشگاهها به کارخانهها منتقل شود.
فناوری MDM-PSO نشان میدهد که رباتهای خودران میتوانند نه فقط هوشمند، بلکه سازگار، پایدار و اقتصادی باشند. هر سازمانی که در زنجیرهی ارزش خود از ناوگانهای خودران، رباتهای حمل بار، پهپادها یا سیستمهای بازرسی استفاده میکند، میتواند از این مدل برای ارتقای هماهنگی و کاهش هزینهها بهره ببرد.
پیشنهاد میشود شرکتهای فعال در زمینهی لجستیک، انرژی، کشاورزی و تولید، تیمهای تحقیق و توسعهی خود را به سمت پیادهسازی نسخههای بومی این الگوریتم سوق دهند. دانشگاهها نیز میتوانند از چارچوب MDM-PSO برای آموزش نسل جدیدی از مهندسان رباتیک استفاده کنند — مهندسانی که بهجای کنترل تکربات، شبکهای از رباتهای هوشمند را مدیریت میکنند.
در نهایت، همانطور که هوش مصنوعی چهرهی دادهها را تغییر داد، هوش ازدحامی واقعی چهرهی حرکت را تغییر خواهد داد. در دنیای آینده، دیگر یک ربات قهرمان نیست؛ بلکه ازدحامِ رباتها، قهرمان صنعت خواهد بود.
رفرنس دقیق مقاله
Liang Zhou, Ming Li, and Wenjia Fang,
“Moving-Distance-Minimized Particle Swarm Optimization for Mobile Robot Swarm Coordination,”
IEEE Transactions on Industrial Informatics, 2023.
DOI: 10.1109/TII.2023.3267591
{kind=link}
بدون نظر